Topological Perspectives on Optimal Multimodal Embedding Spaces
2405.18867
0
0

Abstract
Recent strides in multimodal model development have ignited a paradigm shift in the realm of text-to-image generation. Among these advancements, CLIP stands out as a remarkable achievement which is a sophisticated autoencoder adept at encoding both textual and visual information within a unified latent space. This paper delves into a comparative analysis between CLIP and its recent counterpart, CLOOB. To unravel the intricate distinctions within the embedding spaces crafted by these models, we employ topological data analysis. Our approach encompasses a comprehensive examination of the modality gap drivers, the clustering structures existing across both high and low dimensions, and the pivotal role that dimension collapse plays in shaping their respective embedding spaces. Empirical experiments substantiate the implications of our analyses on downstream performance across various contextual scenarios. Through this investigation, we aim to shed light on the nuanced intricacies that underlie the comparative efficacy of CLIP and CLOOB, offering insights into their respective strengths and weaknesses, and providing a foundation for further refinement and advancement in multimodal model research.
Create account to get full access
Overview
- This paper explores the use of topological data analysis (TDA) to understand the properties of multimodal embedding spaces, which are used in contrastive learning models like CLIP to learn representations from text-image pairs.
- The authors investigate how the topology of these embedding spaces relates to the performance of multimodal models, and propose methods to optimize the topology for improved model performance.
- The paper provides insights into the geometric and topological structure of multimodal embedding spaces, which can help guide the design of more effective contrastive learning architectures.
Plain English Explanation
Multimodal models like CLIP are able to learn powerful representations by training on pairs of text and images. These models create a shared embedding space where semantically similar text and images are mapped close together.
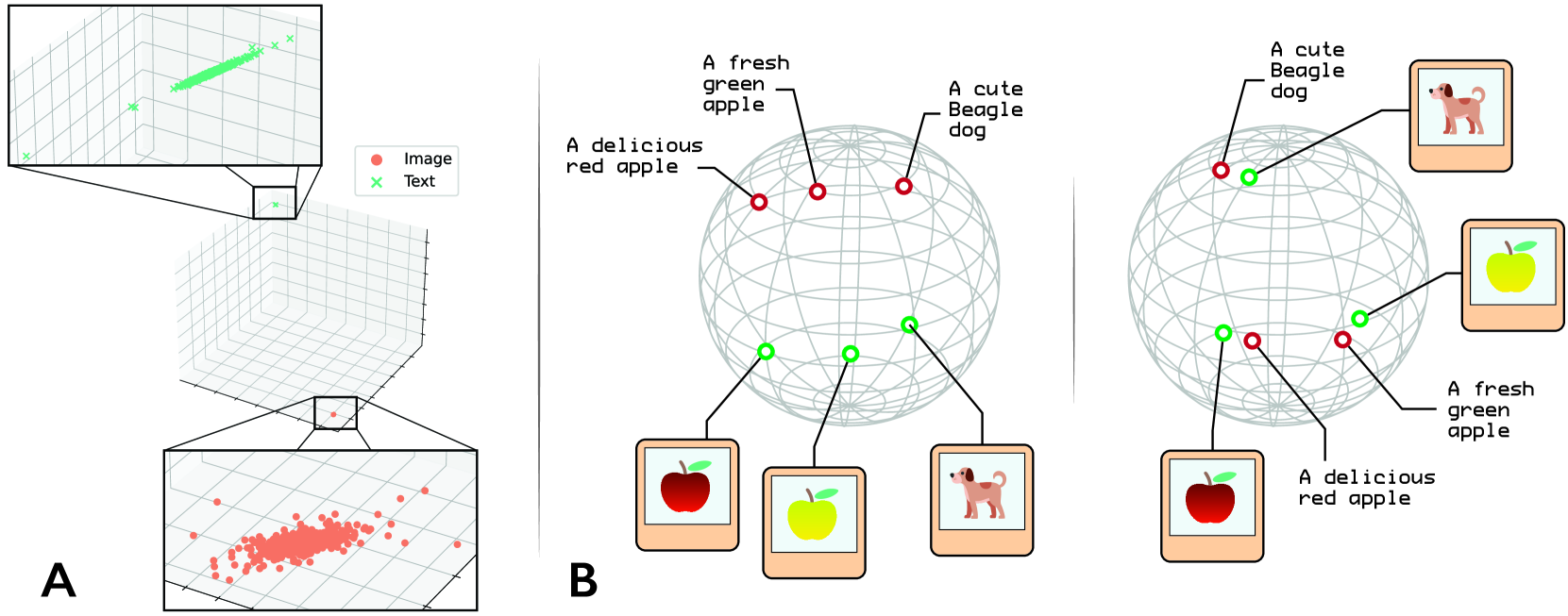
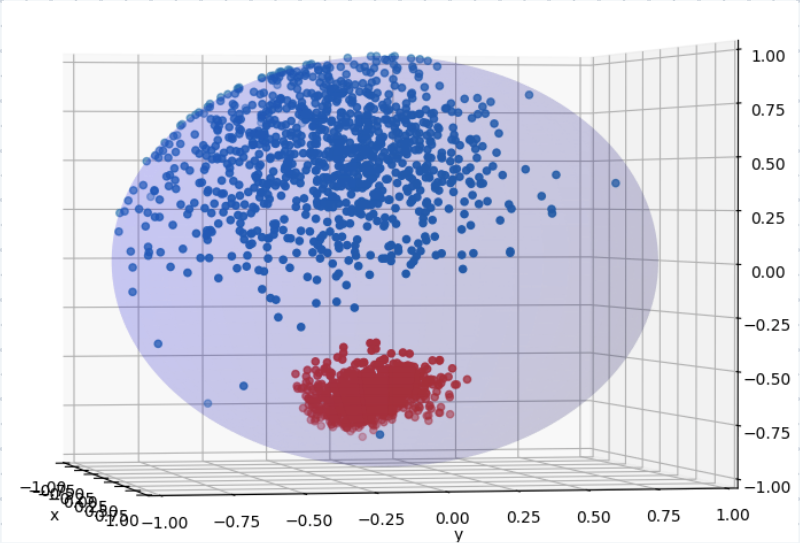
The authors of this paper wanted to better understand the properties of these multimodal embedding spaces. They used a mathematical technique called topological data analysis (TDA) to study the geometric and topological structure of the embeddings. TDA allows them to identify important features of the embedding space, such as clusters, holes, and higher-dimensional shapes.
By analyzing the topology of the embedding space, the researchers found connections between its properties and the performance of the multimodal model. For example, they discovered that having the right "shape" to the embedding space, with well-defined clusters and connections between them, was important for the model to perform well on downstream tasks.
The paper provides strategies for optimizing the topology of the embedding space, such as by modifying the training process or architecture of the model. This can lead to improvements in the model's ability to learn meaningful representations from text-image pairs.
Overall, this work offers a new lens for understanding and enhancing multimodal contrastive learning models. The topological perspective provides insights that can guide the design of more effective architectures for tasks like visual reasoning, few-shot learning, and modality alignment.
Technical Explanation
The authors use topological data analysis (TDA) to characterize the geometric and topological structure of multimodal embedding spaces learned by contrastive learning models like CLIP. TDA provides a set of tools to identify and quantify important topological features of the embedding space, such as clusters, holes, and higher-dimensional shapes.
By analyzing the topology of the embedding space, the researchers found that certain topological properties, such as the presence of well-defined clusters and connections between them, were correlated with improved performance on downstream tasks. They propose methods to optimize the topology of the embedding space, such as by modifying the training process or architecture of the model.
Specifically, the authors investigate how the topology of the embedding space is affected by factors like the choice of contrastive loss function, the training data distribution, and the model architecture. They find that carefully tuning these elements can lead to embedding spaces with more desirable topological properties, which in turn improves the model's performance.
The paper also explores the relationship between the topology of the embedding space and the model's ability to learn robust and transferable representations. The authors show that embedding spaces with certain topological properties are more resilient to distributional shift and can better support tasks like few-shot learning and cross-modal transfer.
Overall, this work provides a novel topological perspective on understanding and optimizing multimodal contrastive learning models. The insights gained from this approach can inform the design of more effective architectures for a variety of applications, including visual reasoning, few-shot learning, and modality alignment.
Critical Analysis
The paper provides a compelling and rigorous analysis of the topological properties of multimodal embedding spaces. The use of TDA offers a novel and insightful lens for understanding the geometric and structural characteristics of these representations, which can have a significant impact on model performance.
One potential limitation of the work is the reliance on a single multimodal model (CLIP) for the empirical evaluation. While CLIP is a widely-used and influential model, it would be valuable to see the topological analysis extended to a broader range of multimodal architectures to validate the generalizability of the findings.
Additionally, while the paper explores various factors that can influence the topology of the embedding space, such as the choice of loss function and training data distribution, there may be other important considerations that are not addressed. For example, the impact of the pretraining task, the model capacity, or the optimization hyperparameters could also be relevant.
It would also be interesting to see the topological analysis extended to other types of multimodal tasks and applications, beyond just the downstream evaluation metrics considered in the paper. Exploring the relationship between embedding topology and performance on tasks like visual reasoning, few-shot learning, or modality alignment could provide additional insights.
Overall, this work represents an important step forward in understanding the geometric and topological properties of multimodal embedding spaces. The findings and methodologies presented in the paper can serve as a foundation for further research into the design and optimization of more effective contrastive learning models.
Conclusion
This paper offers a novel topological perspective on understanding and enhancing multimodal contrastive learning models. By using topological data analysis, the authors were able to characterize the geometric and structural properties of the embedding spaces learned by models like CLIP, and found connections between these topological features and the models' performance on downstream tasks.
The insights gained from this work can help guide the design of more effective multimodal architectures, particularly for applications that rely on robust and transferable representations, such as visual reasoning, few-shot learning, and modality alignment. By optimizing the topology of the embedding space, researchers and practitioners can unlock new capabilities in multimodal AI systems.
The topological perspective offered by this paper represents an important contribution to the growing body of work on understanding and improving contrastive learning models. As the field of multimodal AI continues to advance, this type of rigorous and insightful analysis will be increasingly valuable for driving progress and unlocking the full potential of these powerful techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Mitigate the Gap: Investigating Approaches for Improving Cross-Modal Alignment in CLIP
Sedigheh Eslami, Gerard de Melo
0
0
Contrastive Language--Image Pre-training (CLIP) has manifested remarkable improvements in zero-shot classification and cross-modal vision-language tasks. Yet, from a geometrical point of view, the CLIP embedding space has been found to have a pronounced modality gap. This gap renders the embedding space overly sparse and disconnected, with different modalities being densely distributed in distinct subregions of the hypersphere. In this work, we aim at answering two main questions: 1. Does sharing the parameter space between the multi-modal encoders reduce the modality gap? 2. Can the gap be mitigated by pushing apart the uni-modal embeddings via intra-modality separation? We design AlignCLIP, in order to answer these questions and show that answers to both questions are positive. Through extensive experiments, we show that AlignCLIP achieves noticeable enhancements in the cross-modal alignment of the embeddings, and thereby, reduces the modality gap, while maintaining the performance across several downstream evaluations, such as zero-shot image classification, zero-shot multi-modal retrieval and zero-shot semantic text similarity.
6/27/2024
Its Not a Modality Gap: Characterizing and Addressing the Contrastive Gap
Abrar Fahim, Alex Murphy, Alona Fyshe
0
0
Multi-modal contrastive models such as CLIP achieve state-of-the-art performance in zero-shot classification by embedding input images and texts on a joint representational space. Recently, a modality gap has been reported in two-encoder contrastive models like CLIP, meaning that the image and text embeddings reside in disjoint areas of the latent space. Previous studies suggest that this gap exists due to 1) the cone effect, 2) mismatched pairs in the dataset, and 3) insufficient training. We show that, even when accounting for all these factors, and even when using the same modality, the contrastive loss actually creates a gap during training. As a result, We propose that the modality gap is inherent to the two-encoder contrastive loss and rename it the contrastive gap. We present evidence that attributes this contrastive gap to low uniformity in CLIP space, resulting in embeddings that occupy only a small portion of the latent space. To close the gap, we adapt the uniformity and alignment properties of unimodal contrastive loss to the multi-modal setting and show that simply adding these terms to the CLIP loss distributes the embeddings more uniformly in the representational space, closing the gap. In our experiments, we show that the modified representational space achieves better performance than default CLIP loss in downstream tasks such as zero-shot image classification and multi-modal arithmetic.
6/10/2024

Understanding and Mitigating Compositional Issues in Text-to-Image Generative Models
Arman Zarei, Keivan Rezaei, Samyadeep Basu, Mehrdad Saberi, Mazda Moayeri, Priyatham Kattakinda, Soheil Feizi
0
0
Recent text-to-image diffusion-based generative models have the stunning ability to generate highly detailed and photo-realistic images and achieve state-of-the-art low FID scores on challenging image generation benchmarks. However, one of the primary failure modes of these text-to-image generative models is in composing attributes, objects, and their associated relationships accurately into an image. In our paper, we investigate this compositionality-based failure mode and highlight that imperfect text conditioning with CLIP text-encoder is one of the primary reasons behind the inability of these models to generate high-fidelity compositional scenes. In particular, we show that (i) there exists an optimal text-embedding space that can generate highly coherent compositional scenes which shows that the output space of the CLIP text-encoder is sub-optimal, and (ii) we observe that the final token embeddings in CLIP are erroneous as they often include attention contributions from unrelated tokens in compositional prompts. Our main finding shows that the best compositional improvements can be achieved (without harming the model's FID scores) by fine-tuning {it only} a simple linear projection on CLIP's representation space in Stable-Diffusion variants using a small set of compositional image-text pairs. This result demonstrates that the sub-optimality of the CLIP's output space is a major error source. We also show that re-weighting the erroneous attention contributions in CLIP can also lead to improved compositional performances, however these improvements are often less significant than those achieved by solely learning a linear projection head, highlighting erroneous attentions to be only a minor error source.
6/13/2024

Leveraging Cross-Modal Neighbor Representation for Improved CLIP Classification
Chao Yi, Lu Ren, De-Chuan Zhan, Han-Jia Ye
0
0
CLIP showcases exceptional cross-modal matching capabilities due to its training on image-text contrastive learning tasks. However, without specific optimization for unimodal scenarios, its performance in single-modality feature extraction might be suboptimal. Despite this, some studies have directly used CLIP's image encoder for tasks like few-shot classification, introducing a misalignment between its pre-training objectives and feature extraction methods. This inconsistency can diminish the quality of the image's feature representation, adversely affecting CLIP's effectiveness in target tasks. In this paper, we view text features as precise neighbors of image features in CLIP's space and present a novel CrOss-moDal nEighbor Representation(CODER) based on the distance structure between images and their neighbor texts. This feature extraction method aligns better with CLIP's pre-training objectives, thereby fully leveraging CLIP's robust cross-modal capabilities. The key to construct a high-quality CODER lies in how to create a vast amount of high-quality and diverse texts to match with images. We introduce the Auto Text Generator(ATG) to automatically generate the required texts in a data-free and training-free manner. We apply CODER to CLIP's zero-shot and few-shot image classification tasks. Experiment results across various datasets and models confirm CODER's effectiveness. Code is available at:https://github.com/YCaigogogo/CVPR24-CODER.
4/30/2024