Mitigate Position Bias with Coupled Ranking Bias on CTR Prediction

0
Sign in to get full access
Overview
- The paper addresses the issue of position bias in click-through rate (CTR) prediction models, where items at the top of a ranking list tend to receive more clicks regardless of their true relevance.
- The authors propose a novel approach called "Coupled Ranking Bias" (CRB) that jointly models the position bias and ranking bias to mitigate the overestimation of CTR.
- CRB uses gradient interpolation to learn the complex relationship between position bias and ranking bias, capturing their interdependence.
Plain English Explanation
The paper focuses on a common problem in online recommendation systems called "position bias." This means that items at the top of a list, like search results or product recommendations, tend to get more clicks just because they're at the top, even if they're not the most relevant. This can lead to inaccurate predictions of click-through rates (CTR), which are important for things like ad placement and product rankings.
The researchers developed a new technique called "Coupled Ranking Bias" (CRB) to address this issue. CRB works by modeling the relationship between position bias (where an item is on the list) and ranking bias (how relevant an item is) at the same time. This allows the model to better understand how these two factors interact and influence the CTR predictions.
The key innovation of CRB is the use of "gradient interpolation," which is a way of learning the complex, nonlinear relationship between position bias and ranking bias. This helps the model capture the nuances of how these factors work together, rather than treating them as separate, independent issues.
By accounting for both position bias and ranking bias, the CRB model can make more accurate CTR predictions, which can lead to improved performance in recommendation systems and other applications that rely on understanding user behavior and preferences.
Technical Explanation
The paper proposes a novel approach called "Coupled Ranking Bias" (CRB) to mitigate the position bias problem in click-through rate (CTR) prediction models. Position bias refers to the tendency of items at the top of a ranking list to receive more clicks, even if they are not the most relevant.
CRB jointly models the position bias and ranking bias to address the overestimation of CTR caused by position bias. The key innovation of CRB is the use of gradient interpolation to learn the complex, nonlinear relationship between position bias and ranking bias. This allows the model to capture the interdependence between these two factors, rather than treating them as separate, independent issues.
The authors first formulate the CTR prediction task as a ranking problem, where the goal is to predict the relative order of items based on their relevance. They then introduce the CRB model, which consists of two components: a position bias model and a ranking bias model. The position bias model captures the effect of an item's position on its click probability, while the ranking bias model captures the effect of an item's relevance on its click probability.
The authors propose a gradient interpolation method to learn the relationship between position bias and ranking bias. This involves computing the gradients of the position bias and ranking bias with respect to the model parameters, and then interpolating these gradients to obtain a joint optimization objective that accounts for both types of bias.
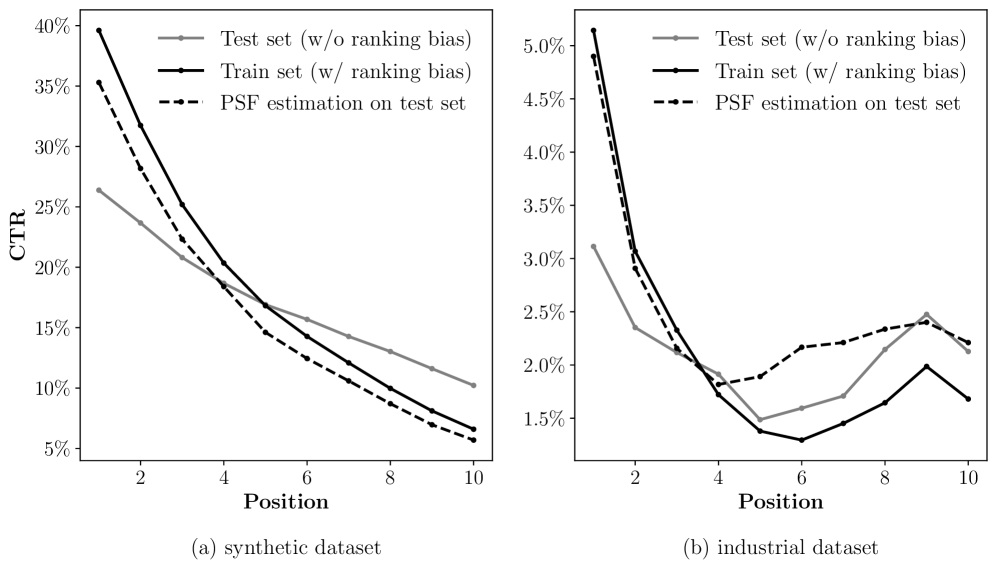
The authors evaluate the CRB model on several real-world datasets and compare its performance to various baselines, including models that address position bias using inverse propensity scoring or debiasing techniques. The results show that CRB outperforms these baselines in terms of CTR prediction accuracy, demonstrating the effectiveness of the coupled bias approach.
Critical Analysis
The paper presents a promising approach to mitigate position bias in CTR prediction models, but it also raises a few potential concerns and areas for further research.
One limitation of the CRB model is that it assumes a specific functional form for the relationship between position bias and ranking bias, which may not always be accurate. The authors use gradient interpolation to learn this relationship, but it's possible that more flexible or data-driven approaches could capture the complexity of this relationship even better.
Additionally, the paper does not explore the generalizability of the CRB model to different types of recommendation systems or domains. It would be interesting to see how the model performs in contexts beyond the e-commerce scenarios presented in the experiments.
Another area for further investigation is the potential interaction between position bias and other types of biases, such as user preference bias or demographic bias. It's possible that addressing position bias alone may not be sufficient, and a more holistic approach to debiasing recommendation systems may be necessary.
Finally, the paper does not discuss the computational complexity or real-world deployment considerations of the CRB model. As recommendation systems often need to operate at scale, the practicality and efficiency of the proposed approach would be an important factor to consider.
Despite these potential limitations, the CRB model represents an important step towards more accurate and equitable CTR prediction, which has significant implications for the design and deployment of recommendation systems. Further research and development in this area could lead to substantial improvements in the fairness and effectiveness of these systems.
Conclusion
The paper introduces a novel approach called "Coupled Ranking Bias" (CRB) to mitigate the position bias problem in click-through rate (CTR) prediction models. CRB jointly models the position bias and ranking bias, using gradient interpolation to capture their complex, interdependent relationship.
The key contributions of the CRB model are its ability to better account for the nuances of how position and ranking biases influence CTR, leading to more accurate predictions. This has important implications for the design and deployment of recommendation systems, where CTR predictions play a crucial role in tasks like ad placement and product ranking.
While the paper presents a promising approach, there are also opportunities for further research and development, such as exploring more flexible relationship modeling, investigating generalizability to different domains, and addressing potential interactions with other types of biases. Nonetheless, the CRB model represents an important step forward in the ongoing effort to build more accurate, fair, and effective recommendation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Mitigate Position Bias with Coupled Ranking Bias on CTR Prediction
Yao Zhao, Zhining Liu, Tianchi Cai, Haipeng Zhang, Chenyi Zhuang, Jinjie Gu
Position bias, i.e., users' preference of an item is affected by its placing position, is well studied in the recommender system literature. However, most existing methods ignore the widely coupled ranking bias, which is also related to the placing position of the item. Using both synthetic and industrial datasets, we first show how this widely coexisted ranking bias deteriorates the performance of the existing position bias estimation methods. To mitigate the position bias with the presence of the ranking bias, we propose a novel position bias estimation method, namely gradient interpolation, which fuses two estimation methods using a fusing weight. We further propose an adaptive method to automatically determine the optimal fusing weight. Extensive experiments on both synthetic and industrial datasets demonstrate the superior performance of the proposed methods.
Read more5/30/2024

0
Mitigate Position Bias in Large Language Models via Scaling a Single Dimension
Yijiong Yu, Huiqiang Jiang, Xufang Luo, Qianhui Wu, Chin-Yew Lin, Dongsheng Li, Yuqing Yang, Yongfeng Huang, Lili Qiu
Large Language Models (LLMs) are increasingly applied in various real-world scenarios due to their excellent generalization capabilities and robust generative abilities. However, they exhibit position bias, also known as lost in the middle, a phenomenon that is especially pronounced in long-context scenarios, which indicates the placement of the key information in different positions of a prompt can significantly affect accuracy. This paper first explores the micro-level manifestations of position bias, concluding that attention weights are a micro-level expression of position bias. It further identifies that, in addition to position embeddings, causal attention mask also contributes to position bias by creating position-specific hidden states. Based on these insights, we propose a method to mitigate position bias by scaling this positional hidden states. Experiments on the NaturalQuestions Multi-document QA, KV retrieval, LongBench and timeline reorder tasks, using various models including RoPE models, context windowextended models, and Alibi models, demonstrate the effectiveness and generalizability of our approach. Our method can improve performance by up to 15.2% by modifying just one dimension of hidden states. Our code is available at https://aka.ms/PositionalHidden.
Read more6/5/2024

0
Understanding the Ranking Loss for Recommendation with Sparse User Feedback
Zhutian Lin, Junwei Pan, Shangyu Zhang, Ximei Wang, Xi Xiao, Shudong Huang, Lei Xiao, Jie Jiang
Click-through rate (CTR) prediction is a crucial area of research in online advertising. While binary cross entropy (BCE) has been widely used as the optimization objective for treating CTR prediction as a binary classification problem, recent advancements have shown that combining BCE loss with an auxiliary ranking loss can significantly improve performance. However, the full effectiveness of this combination loss is not yet fully understood. In this paper, we uncover a new challenge associated with the BCE loss in scenarios where positive feedback is sparse: the issue of gradient vanishing for negative samples. We introduce a novel perspective on the effectiveness of the auxiliary ranking loss in CTR prediction: it generates larger gradients on negative samples, thereby mitigating the optimization difficulties when using the BCE loss only and resulting in improved classification ability. To validate our perspective, we conduct theoretical analysis and extensive empirical evaluations on public datasets. Additionally, we successfully integrate the ranking loss into Tencent's online advertising system, achieving notable lifts of 0.70% and 1.26% in Gross Merchandise Value (GMV) for two main scenarios. The code is openly accessible at: https://github.com/SkylerLinn/Understanding-the-Ranking-Loss.
Read more7/9/2024

0
RE-SORT: Removing Spurious Correlation in Multilevel Interaction for CTR Prediction
Song-Li Wu, Liang Du, Jia-Qi Yang, Yu-Ai Wang, De-Chuan Zhan, Shuang Zhao, Zi-Xun Sun
Click-through rate (CTR) prediction is a critical task in recommendation systems, serving as the ultimate filtering step to sort items for a user. Most recent cutting-edge methods primarily focus on investigating complex implicit and explicit feature interactions; however, these methods neglect the spurious correlation issue caused by confounding factors, thereby diminishing the model's generalization ability. We propose a CTR prediction framework that REmoves Spurious cORrelations in mulTilevel feature interactions, termed RE-SORT, which has two key components. I. A multilevel stacked recurrent (MSR) structure enables the model to efficiently capture diverse nonlinear interactions from feature spaces at different levels. II. A spurious correlation elimination (SCE) module further leverages Laplacian kernel mapping and sample reweighting methods to eliminate the spurious correlations concealed within the multilevel features, allowing the model to focus on the true causal features. Extensive experiments conducted on four challenging CTR datasets and our production dataset demonstrate that the proposed method achieves state-of-the-art performance in both accuracy and speed. The utilized codes, models and dataset will be released at https://github.com/RE-SORT.
Read more5/13/2024