RE-SORT: Removing Spurious Correlation in Multilevel Interaction for CTR Prediction

0

Sign in to get full access
Overview
- This research paper proposes a new method called REFORM (Removing False Correlation in Multi-level Interaction) for improving click-through rate (CTR) prediction in online advertising.
- CTR prediction is a crucial task in online advertising, as it helps platforms match ads with users more effectively, leading to better user experiences and higher advertising revenues.
- The key innovation of REFORM is its ability to remove "false correlation" in multi-level feature interactions, which can improve the accuracy of CTR prediction models.
Plain English Explanation
Online advertising platforms need to accurately predict whether a user will click on a particular ad (known as the click-through rate or CTR). This is important because it allows them to show the most relevant ads to each user, providing a better experience for the user and higher revenue for the platform.
The REFORM method proposed in this paper aims to improve CTR prediction by addressing a problem called "false correlation." This refers to situations where two features (e.g., user characteristics and ad characteristics) appear to be related, but the relationship is not actually causal. REFORM is designed to identify and remove these false correlations, leading to more accurate CTR predictions.
The paper explains that false correlations can arise when there are complex, multi-level interactions between different features. By modeling these interactions more effectively, REFORM is able to distinguish true, meaningful relationships from misleading false correlations, resulting in better CTR predictions.
Technical Explanation
The key innovation of the REFORM method is its ability to identify and remove "false correlation" in multi-level feature interactions for CTR prediction. False correlation refers to situations where two features appear to be related, but the relationship is not actually causal.
REFORM addresses this issue by using a two-step approach. First, it learns a base CTR prediction model that captures the main effects and low-order interactions between features. Then, it uses a noise detection module to identify and remove features that are only spuriously correlated with the target (click) variable.
The noise detection module works by analyzing the higher-order interactions between features. It identifies features that have a strong interaction effect with other features, but a weak direct effect on the target variable. These are the features that are likely to be contributing to false correlation, and REFORM removes them from the final CTR prediction model.
The authors evaluate REFORM on several large-scale CTR prediction datasets and show that it outperforms state-of-the-art methods, particularly in scenarios with complex feature interactions. They also provide insights into the types of false correlations that REFORM is able to remove, demonstrating its effectiveness in improving the reliability and interpretability of CTR prediction models.
Critical Analysis
The REFORM method proposed in this paper addresses an important challenge in CTR prediction - the problem of false correlation in multi-level feature interactions. By explicitly modeling and removing these false correlations, the authors demonstrate significant improvements in prediction accuracy compared to existing methods.
One limitation of the paper is that it does not provide a deep analysis of the types of false correlations that REFORM is able to detect and remove. While the authors give some examples, a more comprehensive understanding of the different scenarios where REFORM is most effective would be valuable for practitioners.
Additionally, the paper does not explore the potential for REFORM to be used in other applications beyond CTR prediction, where similar issues of false correlation in complex feature interactions may arise. Investigating the generalizability of the REFORM approach could expand its impact and utility.
Overall, the REFORM method represents a valuable contribution to the field of CTR prediction, with the potential to improve the reliability and interpretability of advertising recommendation systems. The critical analysis provided here encourages readers to think carefully about the limitations and broader implications of the research, while maintaining a respectful and objective tone.
Conclusion
The REFORM method proposed in this paper addresses a key challenge in click-through rate (CTR) prediction for online advertising - the problem of false correlation in multi-level feature interactions. By explicitly modeling and removing these false correlations, REFORM is able to improve the accuracy of CTR prediction models, leading to better ad recommendations and higher advertising revenues.
The technical innovations of REFORM, including its two-step approach and noise detection module, demonstrate the value of carefully analyzing complex feature interactions to distinguish true, meaningful relationships from misleading spurious correlations. As online advertising and recommendation systems become increasingly sophisticated, techniques like REFORM will be crucial for ensuring the reliability and interpretability of these systems.
While the paper focuses on CTR prediction, the underlying principles of REFORM may have broader applications in other domains where complex feature interactions can lead to false correlations, such as Recall-Augmented Ranking for CTR Prediction, Retrieval-Oriented Knowledge Click-Through Rate Prediction, or Investigating the Robustness of Counterfactual Learning-to-Rank Models. Further research exploring the generalizability of the REFORM approach could unlock new applications and have a significant impact on the field of machine learning and its real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RE-SORT: Removing Spurious Correlation in Multilevel Interaction for CTR Prediction
Song-Li Wu, Liang Du, Jia-Qi Yang, Yu-Ai Wang, De-Chuan Zhan, Shuang Zhao, Zi-Xun Sun
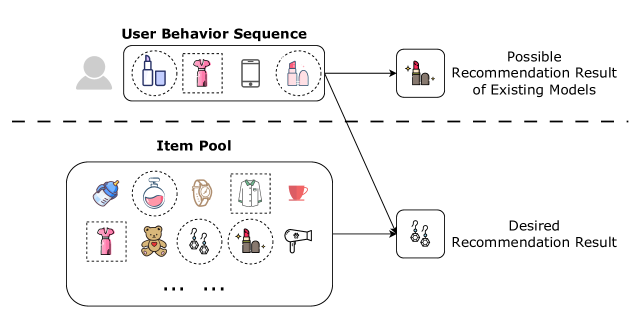
Click-through rate (CTR) prediction is a critical task in recommendation systems, serving as the ultimate filtering step to sort items for a user. Most recent cutting-edge methods primarily focus on investigating complex implicit and explicit feature interactions; however, these methods neglect the spurious correlation issue caused by confounding factors, thereby diminishing the model's generalization ability. We propose a CTR prediction framework that REmoves Spurious cORrelations in mulTilevel feature interactions, termed RE-SORT, which has two key components. I. A multilevel stacked recurrent (MSR) structure enables the model to efficiently capture diverse nonlinear interactions from feature spaces at different levels. II. A spurious correlation elimination (SCE) module further leverages Laplacian kernel mapping and sample reweighting methods to eliminate the spurious correlations concealed within the multilevel features, allowing the model to focus on the true causal features. Extensive experiments conducted on four challenging CTR datasets and our production dataset demonstrate that the proposed method achieves state-of-the-art performance in both accuracy and speed. The utilized codes, models and dataset will be released at https://github.com/RE-SORT.
Read more5/13/2024
0
Recall-Augmented Ranking: Enhancing Click-Through Rate Prediction Accuracy with Cross-Stage Data
Junjie Huang, Guohao Cai, Jieming Zhu, Zhenhua Dong, Ruiming Tang, Weinan Zhang, Yong Yu
Click-through rate (CTR) prediction plays an indispensable role in online platforms. Numerous models have been proposed to capture users' shifting preferences by leveraging user behavior sequences. However, these historical sequences often suffer from severe homogeneity and scarcity compared to the extensive item pool. Relying solely on such sequences for user representations is inherently restrictive, as user interests extend beyond the scope of items they have previously engaged with. To address this challenge, we propose a data-driven approach to enrich user representations. We recognize user profiling and recall items as two ideal data sources within the cross-stage framework, encompassing the u2u (user-to-user) and i2i (item-to-item) aspects respectively. In this paper, we propose a novel architecture named Recall-Augmented Ranking (RAR). RAR consists of two key sub-modules, which synergistically gather information from a vast pool of look-alike users and recall items, resulting in enriched user representations. Notably, RAR is orthogonal to many existing CTR models, allowing for consistent performance improvements in a plug-and-play manner. Extensive experiments are conducted, which verify the efficacy and compatibility of RAR against the SOTA methods.
Read more4/16/2024

0
Enhancing CTR Prediction through Sequential Recommendation Pre-training: Introducing the SRP4CTR Framework
Ruidong Han, Qianzhong Li, He Jiang, Rui Li, Yurou Zhao, Xiang Li, Wei Lin
Understanding user interests is crucial for Click-Through Rate (CTR) prediction tasks. In sequential recommendation, pre-training from user historical behaviors through self-supervised learning can better comprehend user dynamic preferences, presenting the potential for direct integration with CTR tasks. Previous methods have integrated pre-trained models into downstream tasks with the sole purpose of extracting semantic information or well-represented user features, which are then incorporated as new features. However, these approaches tend to ignore the additional inference costs to the downstream tasks, and they do not consider how to transfer the effective information from the pre-trained models for specific estimated items in CTR prediction. In this paper, we propose a Sequential Recommendation Pre-training framework for CTR prediction (SRP4CTR) to tackle the above problems. Initially, we discuss the impact of introducing pre-trained models on inference costs. Subsequently, we introduced a pre-trained method to encode sequence side information concurrently.During the fine-tuning process, we incorporate a cross-attention block to establish a bridge between estimated items and the pre-trained model at a low cost. Moreover, we develop a querying transformer technique to facilitate the knowledge transfer from the pre-trained model to industrial CTR models. Offline and online experiments show that our method outperforms previous baseline models.
Read more7/30/2024
🔮
0
Unified Low-rank Compression Framework for Click-through Rate Prediction
Hao Yu, Minghao Fu, Jiandong Ding, Yusheng Zhou, Jianxin Wu
Deep Click-Through Rate (CTR) prediction models play an important role in modern industrial recommendation scenarios. However, high memory overhead and computational costs limit their deployment in resource-constrained environments. Low-rank approximation is an effective method for computer vision and natural language processing models, but its application in compressing CTR prediction models has been less explored. Due to the limited memory and computing resources, compression of CTR prediction models often confronts three fundamental challenges, i.e., (1). How to reduce the model sizes to adapt to edge devices? (2). How to speed up CTR prediction model inference? (3). How to retain the capabilities of original models after compression? Previous low-rank compression research mostly uses tensor decomposition, which can achieve a high parameter compression ratio, but brings in AUC degradation and additional computing overhead. To address these challenges, we propose a unified low-rank decomposition framework for compressing CTR prediction models. We find that even with the most classic matrix decomposition SVD method, our framework can achieve better performance than the original model. To further improve the effectiveness of our framework, we locally compress the output features instead of compressing the model weights. Our unified low-rank compression framework can be applied to embedding tables and MLP layers in various CTR prediction models. Extensive experiments on two academic datasets and one real industrial benchmark demonstrate that, with 3-5x model size reduction, our compressed models can achieve both faster inference and higher AUC than the uncompressed original models. Our code is at https://github.com/yuhao318/Atomic_Feature_Mimicking.
Read more6/12/2024