Mitigating LLM Hallucinations via Conformal Abstention
2405.01563
1
0
🚀
Abstract
We develop a principled procedure for determining when a large language model (LLM) should abstain from responding (e.g., by saying I don't know) in a general domain, instead of resorting to possibly hallucinating a non-sensical or incorrect answer. Building on earlier approaches that use self-consistency as a more reliable measure of model confidence, we propose using the LLM itself to self-evaluate the similarity between each of its sampled responses for a given query. We then further leverage conformal prediction techniques to develop an abstention procedure that benefits from rigorous theoretical guarantees on the hallucination rate (error rate). Experimentally, our resulting conformal abstention method reliably bounds the hallucination rate on various closed-book, open-domain generative question answering datasets, while also maintaining a significantly less conservative abstention rate on a dataset with long responses (Temporal Sequences) compared to baselines using log-probability scores to quantify uncertainty, while achieveing comparable performance on a dataset with short answers (TriviaQA). To evaluate the experiments automatically, one needs to determine if two responses are equivalent given a question. Following standard practice, we use a thresholded similarity function to determine if two responses match, but also provide a method for calibrating the threshold based on conformal prediction, with theoretical guarantees on the accuracy of the match prediction, which might be of independent interest.
Create account to get full access
Overview
- Researchers develop a method to help large language models (LLMs) determine when they should abstain from responding to a query, rather than potentially generating nonsensical or incorrect answers.
- The method uses the LLM's own self-evaluation of the similarity between its sampled responses to assess its confidence in the answer.
- Conformal prediction techniques are used to provide theoretical guarantees on the error rate or "hallucination" rate when the model chooses to provide a response.
- The approach is tested on various question-answering datasets and shown to reliably bound the hallucination rate while maintaining a lower abstention rate than baseline methods.
- The researchers also provide a method for calibrating the threshold used to determine if two responses are equivalent, with theoretical guarantees on the accuracy of the match prediction.
Plain English Explanation
Large language models (LLMs) like GPT-3 are incredibly powerful, but they can sometimes generate responses that don't make sense or are factually incorrect. This is called "hallucination." The researchers in this paper develop a principled procedure for determining when a large language model (LLM) should abstain from responding (e.g., by saying "I don't know") instead of potentially hallucinating.
The key idea is to have the LLM self-evaluate the similarity between each of its sampled responses for a given query. If the responses are very different, that's a sign the model is unsure, and it should abstain. The researchers also use conformal prediction techniques to provide strong mathematical guarantees on the maximum rate of hallucination when the model does provide a response.
They test this approach on various question-answering datasets and show that it can reliably bound the hallucination rate while maintaining a lower abstention rate than baseline methods that just use the model's confidence scores. They also provide a way to calibrate the threshold used to determine if two responses are equivalent, with theoretical guarantees on the accuracy of the match prediction.
Technical Explanation
The researchers propose a method to determine when a large language model (LLM) should abstain from responding instead of potentially hallucinating an incorrect answer. Building on earlier work that used self-consistency as a measure of model confidence, they use the LLM itself to evaluate the similarity between its sampled responses for a given query.
They then leverage conformal prediction techniques to develop an abstention procedure that provides rigorous theoretical guarantees on the hallucination or error rate. Experimentally, they show that their "conformal abstention" method reliably bounds the hallucination rate on various question-answering datasets, while maintaining a lower abstention rate than baselines that use log-probability scores to quantify uncertainty.
To evaluate the experiments, the researchers need to determine if two responses are equivalent given a question. They use a thresholded similarity function, and also provide a method for calibrating the threshold based on conformal prediction, with theoretical guarantees on the accuracy of the match prediction.
Critical Analysis
The researchers provide a rigorous and principled approach for determining when a large language model should abstain from responding, which is an important problem for the safe and reliable deployment of these models. The use of conformal prediction techniques to provide theoretical guarantees on the hallucination rate is a strength of the work.
However, the paper does not address the potential limitations of the self-consistency metric used to assess model confidence. It's possible that this metric could be manipulated or gamed by the model in adversarial settings. Additionally, the calibration of the threshold for determining equivalent responses is an interesting contribution, but its real-world effectiveness may depend on the specific use case and dataset.
Further research could explore alternative confidence metrics or methods for determining when to abstain, and investigate the robustness of the approach to different types of hallucination or adversarial attacks. Ultimately, while this work represents an important step forward, there is still much to be done to ensure the safety and reliability of large language models.
Conclusion
This paper presents a principled approach for helping large language models determine when to abstain from responding to avoid potential hallucination. By leveraging the model's own self-evaluation of response similarity and using conformal prediction techniques, the researchers are able to reliably bound the hallucination rate while maintaining a lower abstention rate than baseline methods.
This work represents an important step towards enhancing the safety and reliability of large language models and could have significant implications for the real-world deployment of these powerful AI systems. By helping to reduce human hallucination, this research contributes to the broader goal of building more trustworthy and accountable AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Conformal Language Modeling
Victor Quach, Adam Fisch, Tal Schuster, Adam Yala, Jae Ho Sohn, Tommi S. Jaakkola, Regina Barzilay
0
0
We propose a novel approach to conformal prediction for generative language models (LMs). Standard conformal prediction produces prediction sets -- in place of single predictions -- that have rigorous, statistical performance guarantees. LM responses are typically sampled from the model's predicted distribution over the large, combinatorial output space of natural language. Translating this process to conformal prediction, we calibrate a stopping rule for sampling different outputs from the LM that get added to a growing set of candidates until we are confident that the output set is sufficient. Since some samples may be low-quality, we also simultaneously calibrate and apply a rejection rule for removing candidates from the output set to reduce noise. Similar to conformal prediction, we prove that the sampled set returned by our procedure contains at least one acceptable answer with high probability, while still being empirically precise (i.e., small) on average. Furthermore, within this set of candidate responses, we show that we can also accurately identify subsets of individual components -- such as phrases or sentences -- that are each independently correct (e.g., that are not hallucinations), again with statistical guarantees. We demonstrate the promise of our approach on multiple tasks in open-domain question answering, text summarization, and radiology report generation using different LM variants.
6/4/2024

To Believe or Not to Believe Your LLM
Yasin Abbasi Yadkori, Ilja Kuzborskij, Andr'as Gyorgy, Csaba Szepesv'ari
0
0
We explore uncertainty quantification in large language models (LLMs), with the goal to identify when uncertainty in responses given a query is large. We simultaneously consider both epistemic and aleatoric uncertainties, where the former comes from the lack of knowledge about the ground truth (such as about facts or the language), and the latter comes from irreducible randomness (such as multiple possible answers). In particular, we derive an information-theoretic metric that allows to reliably detect when only epistemic uncertainty is large, in which case the output of the model is unreliable. This condition can be computed based solely on the output of the model obtained simply by some special iterative prompting based on the previous responses. Such quantification, for instance, allows to detect hallucinations (cases when epistemic uncertainty is high) in both single- and multi-answer responses. This is in contrast to many standard uncertainty quantification strategies (such as thresholding the log-likelihood of a response) where hallucinations in the multi-answer case cannot be detected. We conduct a series of experiments which demonstrate the advantage of our formulation. Further, our investigations shed some light on how the probabilities assigned to a given output by an LLM can be amplified by iterative prompting, which might be of independent interest.
6/5/2024

Characterizing LLM Abstention Behavior in Science QA with Context Perturbations
Bingbing Wen, Bill Howe, Lucy Lu Wang
0
0
The correct model response in the face of uncertainty is to abstain from answering a question so as not to mislead the user. In this work, we study the ability of LLMs to abstain from answering context-dependent science questions when provided insufficient or incorrect context. We probe model sensitivity in several settings: removing gold context, replacing gold context with irrelevant context, and providing additional context beyond what is given. In experiments on four QA datasets with four LLMs, we show that performance varies greatly across models, across the type of context provided, and also by question type; in particular, many LLMs seem unable to abstain from answering boolean questions using standard QA prompts. Our analysis also highlights the unexpected impact of abstention performance on QA task accuracy. Counter-intuitively, in some settings, replacing gold context with irrelevant context or adding irrelevant context to gold context can improve abstention performance in a way that results in improvements in task performance. Our results imply that changes are needed in QA dataset design and evaluation to more effectively assess the correctness and downstream impacts of model abstention.
4/22/2024
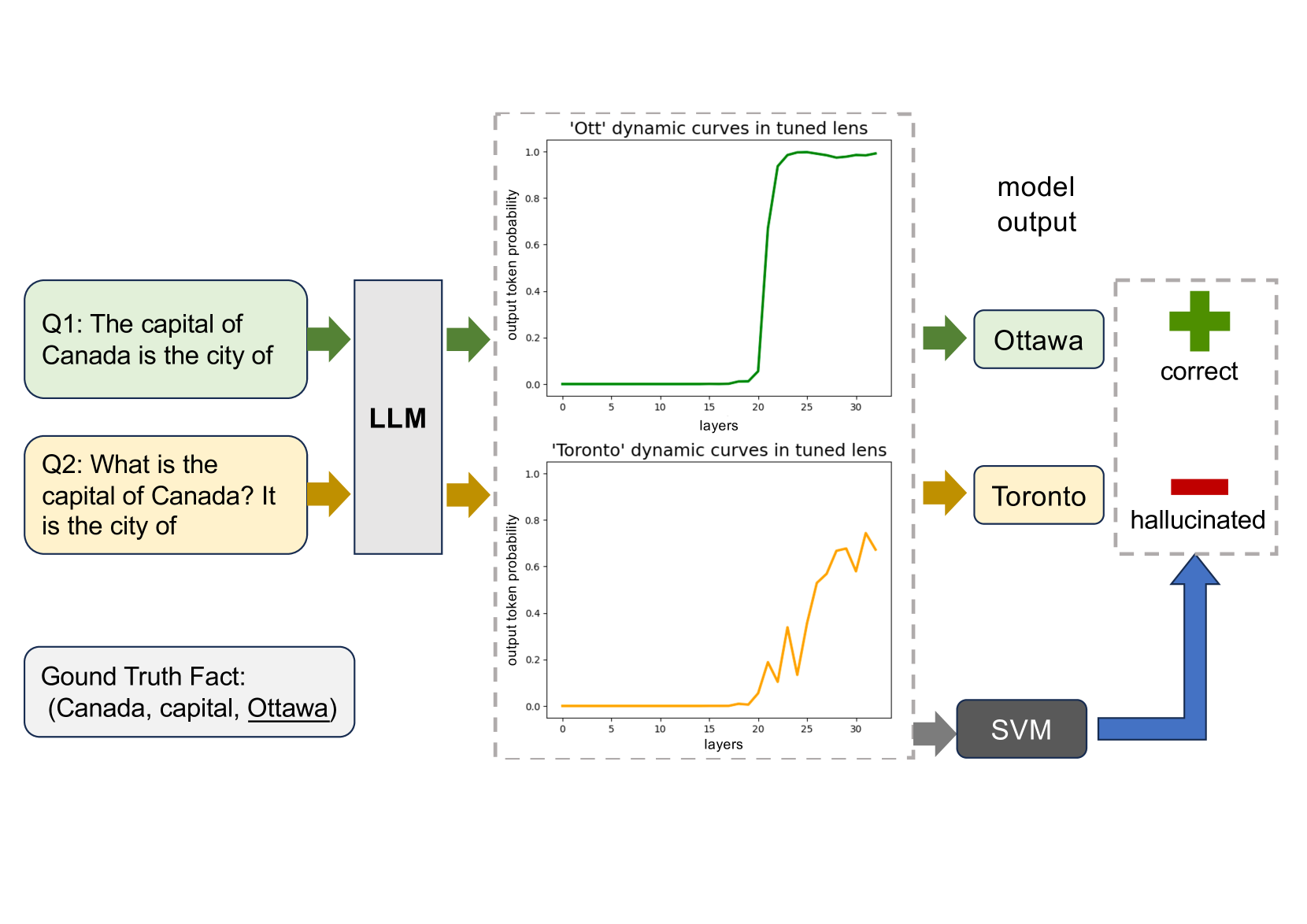
On Large Language Models' Hallucination with Regard to Known Facts
Che Jiang, Biqing Qi, Xiangyu Hong, Dayuan Fu, Yang Cheng, Fandong Meng, Mo Yu, Bowen Zhou, Jie Zhou
0
0
Large language models are successful in answering factoid questions but are also prone to hallucination.We investigate the phenomenon of LLMs possessing correct answer knowledge yet still hallucinating from the perspective of inference dynamics, an area not previously covered in studies on hallucinations.We are able to conduct this analysis via two key ideas.First, we identify the factual questions that query the same triplet knowledge but result in different answers. The difference between the model behaviors on the correct and incorrect outputs hence suggests the patterns when hallucinations happen. Second, to measure the pattern, we utilize mappings from the residual streams to vocabulary space. We reveal the different dynamics of the output token probabilities along the depths of layers between the correct and hallucinated cases. In hallucinated cases, the output token's information rarely demonstrates abrupt increases and consistent superiority in the later stages of the model. Leveraging the dynamic curve as a feature, we build a classifier capable of accurately detecting hallucinatory predictions with an 88% success rate. Our study shed light on understanding the reasons for LLMs' hallucinations on their known facts, and more importantly, on accurately predicting when they are hallucinating.
4/1/2024