Mitigating Memorization In Language Models

1
Sign in to get full access
Overview
- Addresses the issue of language models memorizing and reproducing sensitive or private information from their training data
- Proposes techniques to mitigate this undesirable memorization and improve the safety and reliability of language models
- Covers key concepts around memorization in language models, methods for detecting and measuring it, and strategies for reducing it
Plain English Explanation
Language models, which are AI systems trained on vast amounts of text data, have become incredibly powerful at generating human-like language. However, this power comes with a potential downside - these models can sometimes memorize and reproduce sensitive information from their training data, such as personal details, copyrighted text, or other private information.
This can be a significant issue, as it raises privacy concerns and could lead to the unintended release of sensitive data. The paper addresses this problem by exploring techniques to mitigate the memorization of language models. Some of the key ideas include:
- Detecting and measuring memorization: Developing methods to identify when a language model has memorized specific pieces of information from its training data.
- Reducing memorization: Exploring strategies to modify the training process or architecture of language models to make them less prone to memorization, while still maintaining their impressive language generation capabilities.
By tackling the issue of memorization, the researchers aim to make language models more safe, reliable, and trustworthy for a wide range of applications, from chatbots to content generation.
Technical Explanation
The paper begins by discussing the phenomenon of memorization in language models, where these AI systems can inadvertently learn to reproduce specific pieces of text from their training data. This can be problematic, as it can lead to the unintended release of sensitive or private information.
To address this issue, the researchers propose several techniques for detecting and measuring memorization in language models. One approach involves searching for exact matches between the model's outputs and the training data, while another looks for near-duplicate outputs that closely resemble specific training examples.
The paper then explores strategies for reducing memorization in language models. These include modifying the training process, such as by introducing noise or adversarial examples, as well as architectural changes to the language model itself, like adding memory-based components or constraining the model's capacity.
Through a series of experiments, the researchers demonstrate the effectiveness of these techniques in mitigating memorization while preserving the language generation capabilities of the models. They also discuss potential limitations and areas for future research, such as the need to address more complex forms of memorization and the potential trade-offs between reducing memorization and model performance.
Critical Analysis
The paper provides a comprehensive overview of the issue of memorization in language models and offers valuable insights into addressing this challenge. The proposed techniques for detecting and reducing memorization are well-designed and show promising results in the experiments.
However, the researchers acknowledge that their work is not a complete solution to the memorization problem. There may be more complex forms of memorization that are not easily detected by the current methods, and the trade-offs between reducing memorization and maintaining model performance require further investigation.
Additionally, the paper does not delve into the broader ethical and societal implications of language model memorization, such as the potential misuse of sensitive information or the impact on individual privacy. These are important considerations that could be explored in future research.
Overall, the paper makes a significant contribution to the field of language model safety and reliability, and the techniques it presents are likely to be valuable tools for researchers and developers working to build more trustworthy and responsible AI systems.
Conclusion
This paper addresses the critical issue of memorization in language models, where these AI systems can inadvertently learn to reproduce sensitive or private information from their training data. The researchers propose effective techniques for detecting and measuring memorization, as well as strategies for reducing it through modifications to the training process and model architecture.
By tackling the problem of memorization, the researchers aim to make language models more safe, reliable, and trustworthy for a wide range of applications. While the work presented here is not a complete solution, it represents an important step forward in ensuring the responsible development and deployment of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
New!Mitigating Memorization In Language Models
Mansi Sakarvadia, Aswathy Ajith, Arham Khan, Nathaniel Hudson, Caleb Geniesse, Kyle Chard, Yaoqing Yang, Ian Foster, Michael W. Mahoney
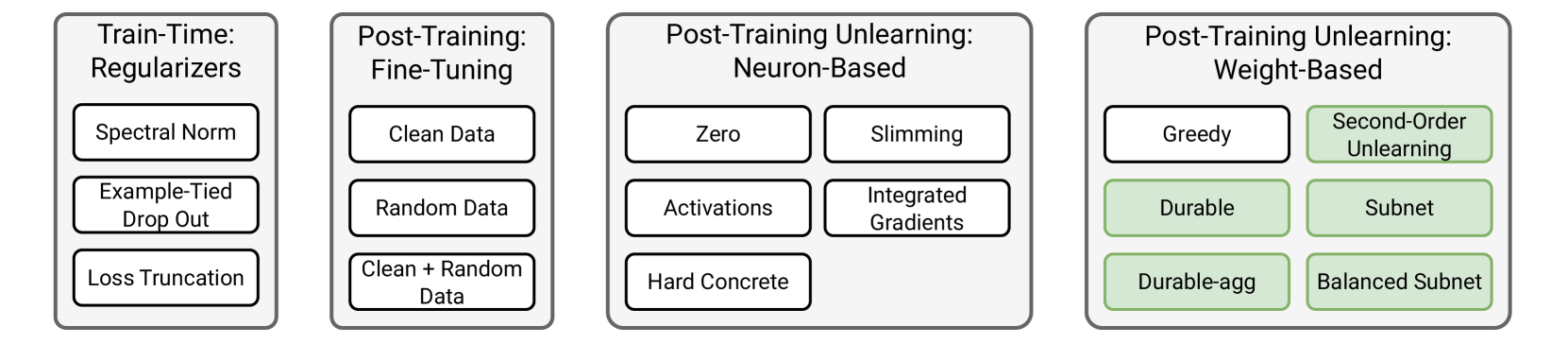
Language models (LMs) can memorize information, i.e., encode training data in their weights in such a way that inference-time queries can lead to verbatim regurgitation of that data. This ability to extract training data can be problematic, for example, when data are private or sensitive. In this work, we investigate methods to mitigate memorization: three regularizer-based, three finetuning-based, and eleven machine unlearning-based methods, with five of the latter being new methods that we introduce. We also introduce TinyMem, a suite of small, computationally-efficient LMs for the rapid development and evaluation of memorization-mitigation methods. We demonstrate that the mitigation methods that we develop using TinyMem can successfully be applied to production-grade LMs, and we determine via experiment that: regularizer-based mitigation methods are slow and ineffective at curbing memorization; fine-tuning-based methods are effective at curbing memorization, but overly expensive, especially for retaining higher accuracies; and unlearning-based methods are faster and more effective, allowing for the precise localization and removal of memorized information from LM weights prior to inference. We show, in particular, that our proposed unlearning method BalancedSubnet outperforms other mitigation methods at removing memorized information while preserving performance on target tasks.
Read more10/4/2024

0
New!Undesirable Memorization in Large Language Models: A Survey
Ali Satvaty, Suzan Verberne, Fatih Turkmen
While recent research increasingly showcases the remarkable capabilities of Large Language Models (LLMs), it's vital to confront their hidden pitfalls. Among these challenges, the issue of memorization stands out, posing significant ethical and legal risks. In this paper, we presents a Systematization of Knowledge (SoK) on the topic of memorization in LLMs. Memorization is the effect that a model tends to store and reproduce phrases or passages from the training data and has been shown to be the fundamental issue to various privacy and security attacks against LLMs. We begin by providing an overview of the literature on the memorization, exploring it across five key dimensions: intentionality, degree, retrievability, abstraction, and transparency. Next, we discuss the metrics and methods used to measure memorization, followed by an analysis of the factors that contribute to memorization phenomenon. We then examine how memorization manifests itself in specific model architectures and explore strategies for mitigating these effects. We conclude our overview by identifying potential research topics for the near future: to develop methods for balancing performance and privacy in LLMs, and the analysis of memorization in specific contexts, including conversational agents, retrieval-augmented generation, multilingual language models, and diffusion language models.
Read more10/4/2024
💬
0
To Each (Textual Sequence) Its Own: Improving Memorized-Data Unlearning in Large Language Models
George-Octavian Barbulescu, Peter Triantafillou
LLMs have been found to memorize training textual sequences and regurgitate verbatim said sequences during text generation time. This fact is known to be the cause of privacy and related (e.g., copyright) problems. Unlearning in LLMs then takes the form of devising new algorithms that will properly deal with these side-effects of memorized data, while not hurting the model's utility. We offer a fresh perspective towards this goal, namely, that each textual sequence to be forgotten should be treated differently when being unlearned based on its degree of memorization within the LLM. We contribute a new metric for measuring unlearning quality, an adversarial attack showing that SOTA algorithms lacking this perspective fail for privacy, and two new unlearning methods based on Gradient Ascent and Task Arithmetic, respectively. A comprehensive performance evaluation across an extensive suite of NLP tasks then mapped the solution space, identifying the best solutions under different scales in model capacities and forget set sizes and quantified the gains of the new approaches.
Read more5/7/2024

0
Be like a Goldfish, Don't Memorize! Mitigating Memorization in Generative LLMs
Abhimanyu Hans, Yuxin Wen, Neel Jain, John Kirchenbauer, Hamid Kazemi, Prajwal Singhania, Siddharth Singh, Gowthami Somepalli, Jonas Geiping, Abhinav Bhatele, Tom Goldstein
Large language models can memorize and repeat their training data, causing privacy and copyright risks. To mitigate memorization, we introduce a subtle modification to the next-token training objective that we call the goldfish loss. During training, a randomly sampled subset of tokens are excluded from the loss computation. These dropped tokens are not memorized by the model, which prevents verbatim reproduction of a complete chain of tokens from the training set. We run extensive experiments training billion-scale Llama-2 models, both pre-trained and trained from scratch, and demonstrate significant reductions in extractable memorization with little to no impact on downstream benchmarks.
Read more6/17/2024