Mixat: A Data Set of Bilingual Emirati-English Speech

0
📊
Sign in to get full access
Overview
- This paper introduces a dataset called Mixat, which contains Emirati speech that is code-mixed with English.
- The dataset was developed to address the limitations of existing speech recognition resources when applied to Emirati speech, particularly for bilingual Emirati speakers who often switch between their local dialect and English.
- The dataset consists of 15 hours of speech from two public podcasts featuring native Emirati speakers, including conversations between a host and a guest.
- The paper describes the data collection and annotation process, as well as the features and statistics of the resulting dataset.
- The authors also evaluate the performance of pre-trained Arabic and multilingual automatic speech recognition (ASR) systems on their dataset, demonstrating the challenges of recognizing code-switching in ASR.
Plain English Explanation
This research paper introduces a new dataset called Mixat, which contains recordings of Emirati speech that is mixed with English. The researchers created this dataset to address the limitations of existing speech recognition tools when used on Emirati speech, especially for bilingual Emirati speakers who often switch back and forth between their local dialect and English.
The Mixat dataset includes 15 hours of speech recordings from two public podcasts featuring native Emirati speakers. Some of the recordings are conversations between a host and a guest, which provides examples of Emirati-English code-switching in both formal and natural conversational settings.
The paper explains how the researchers collected and annotated the data, and provides details about the characteristics and statistics of the dataset. Additionally, the researchers evaluated how well some existing Arabic and multilingual speech recognition models perform on the Mixat dataset. Their results show that these pre-trained models struggle to accurately recognize the code-switching present in the Emirati speech.
Technical Explanation
The Mixat dataset was developed to address the shortcomings of current speech recognition resources when applied to Emirati speech, particularly for bilingual Emirati speakers who often mix and switch between their local dialect and English. The dataset consists of 15 hours of speech derived from two public podcasts featuring native Emirati speakers, including conversations between a host and a guest.
The researchers describe the data collection and annotation process in detail. They explain that the dataset contains examples of Emirati-English code-switching in both formal and natural conversational contexts. The paper also provides an analysis of the features and statistics of the resulting dataset.
To evaluate the performance of existing models on the Mixat dataset, the researchers tested pre-trained Arabic and multilingual automatic speech recognition (ASR) systems. Their results demonstrate the challenges of recognizing code-switching in ASR, as the pre-trained models struggled to accurately transcribe the Emirati speech which blended the local dialect with English.
Critical Analysis
The researchers acknowledge that the Mixat dataset is relatively small in size, with only 15 hours of speech recordings. This may limit the dataset's usefulness for training large-scale speech recognition models. Additionally, the dataset is focused on a specific regional dialect of Arabic (Emirati), which could restrict its applicability to other Arabic-speaking regions.
While the paper highlights the challenges of recognizing code-switching in ASR, it does not provide a comprehensive solution to this problem. The researchers note that further research is needed to develop more robust speech recognition models capable of handling code-switching in low-resource dialectal Arabic contexts.
It would also be valuable for the researchers to explore the potential biases or demographic skews present in the dataset, as the podcasts used as the data source may not be fully representative of the Emirati population. Expanding the dataset to include a more diverse range of speakers and conversational contexts could enhance its usefulness for the research community.
Conclusion
This paper introduces the Mixat dataset, a collection of Emirati speech that is code-mixed with English. The dataset was created to address the limitations of existing speech recognition resources when applied to Emirati speech, particularly for bilingual speakers who often switch between their local dialect and English.
The Mixat dataset provides a valuable resource for researchers working on speech recognition challenges in low-resource dialectal Arabic contexts. The paper's evaluation of pre-trained models on the dataset highlights the need for more advanced techniques to handle code-switching in ASR.
While the dataset has some limitations, such as its small size and regional focus, it represents an important step towards improving speech recognition capabilities for diverse language communities. The researchers' commitment to making Mixat publicly available for research use is a commendable contribution to the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Mixat: A Data Set of Bilingual Emirati-English Speech
Maryam Al Ali, Hanan Aldarmaki
This paper introduces Mixat: a dataset of Emirati speech code-mixed with English. Mixat was developed to address the shortcomings of current speech recognition resources when applied to Emirati speech, and in particular, to bilignual Emirati speakers who often mix and switch between their local dialect and English. The data set consists of 15 hours of speech derived from two public podcasts featuring native Emirati speakers, one of which is in the form of conversations between the host and a guest. Therefore, the collection contains examples of Emirati-English code-switching in both formal and natural conversational contexts. In this paper, we describe the process of data collection and annotation, and describe some of the features and statistics of the resulting data set. In addition, we evaluate the performance of pre-trained Arabic and multi-lingual ASR systems on our dataset, demonstrating the shortcomings of existing models on this low-resource dialectal Arabic, and the additional challenge of recognizing code-switching in ASR. The dataset will be made publicly available for research use.
Read more5/7/2024
0
ArzEn-LLM: Code-Switched Egyptian Arabic-English Translation and Speech Recognition Using LLMs
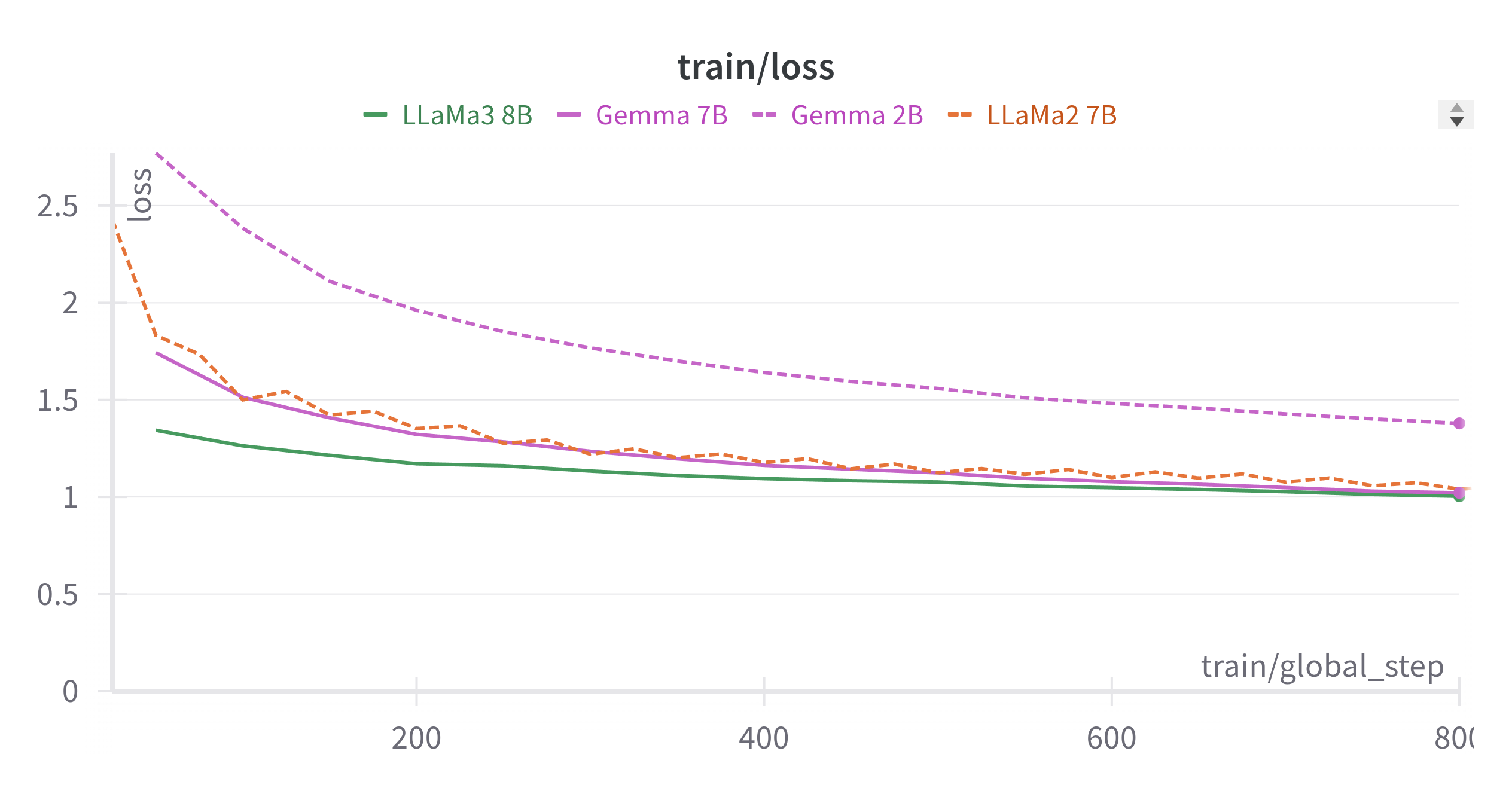
Ahmed Heakl, Youssef Zaghloul, Mennatullah Ali, Rania Hossam, Walid Gomaa
Motivated by the widespread increase in the phenomenon of code-switching between Egyptian Arabic and English in recent times, this paper explores the intricacies of machine translation (MT) and automatic speech recognition (ASR) systems, focusing on translating code-switched Egyptian Arabic-English to either English or Egyptian Arabic. Our goal is to present the methodologies employed in developing these systems, utilizing large language models such as LLama and Gemma. In the field of ASR, we explore the utilization of the Whisper model for code-switched Egyptian Arabic recognition, detailing our experimental procedures including data preprocessing and training techniques. Through the implementation of a consecutive speech-to-text translation system that integrates ASR with MT, we aim to overcome challenges posed by limited resources and the unique characteristics of the Egyptian Arabic dialect. Evaluation against established metrics showcases promising results, with our methodologies yielding a significant improvement of $56%$ in English translation over the state-of-the-art and $9.3%$ in Arabic translation. Since code-switching is deeply inherent in spoken languages, it is crucial that ASR systems can effectively handle this phenomenon. This capability is crucial for enabling seamless interaction in various domains, including business negotiations, cultural exchanges, and academic discourse. Our models and code are available as open-source resources. Code: url{http://github.com/ahmedheakl/arazn-llm}}, Models: url{http://huggingface.co/collections/ahmedheakl/arazn-llm-662ceaf12777656607b9524e}.
Read more7/16/2024
0
EmoMix-3L: A Code-Mixed Dataset for Bangla-English-Hindi Emotion Detection
Nishat Raihan, Dhiman Goswami, Antara Mahmud, Antonios Anastasopoulos, Marcos Zampieri
Code-mixing is a well-studied linguistic phenomenon that occurs when two or more languages are mixed in text or speech. Several studies have been conducted on building datasets and performing downstream NLP tasks on code-mixed data. Although it is not uncommon to observe code-mixing of three or more languages, most available datasets in this domain contain code-mixed data from only two languages. In this paper, we introduce EmoMix-3L, a novel multi-label emotion detection dataset containing code-mixed data from three different languages. We experiment with several models on EmoMix-3L and we report that MuRIL outperforms other models on this dataset.
Read more5/14/2024

0
ManaTTS Persian: a recipe for creating TTS datasets for lower resource languages
Mahta Fetrat Qharabagh, Zahra Dehghanian, Hamid R. Rabiee
In this study, we introduce ManaTTS, the most extensive publicly accessible single-speaker Persian corpus, and a comprehensive framework for collecting transcribed speech datasets for the Persian language. ManaTTS, released under the open CC-0 license, comprises approximately 86 hours of audio with a sampling rate of 44.1 kHz. Alongside ManaTTS, we also generated the VirgoolInformal dataset to evaluate Persian speech recognition models used for forced alignment, extending over 5 hours of audio. The datasets are supported by a fully transparent, MIT-licensed pipeline, a testament to innovation in the field. It includes unique tools for sentence tokenization, bounded audio segmentation, and a novel forced alignment method. This alignment technique is specifically designed for low-resource languages, addressing a crucial need in the field. With this dataset, we trained a Tacotron2-based TTS model, achieving a Mean Opinion Score (MOS) of 3.76, which is remarkably close to the MOS of 3.86 for the utterances generated by the same vocoder and natural spectrogram, and the MOS of 4.01 for the natural waveform, demonstrating the exceptional quality and effectiveness of the corpus.
Read more9/12/2024