EmoMix-3L: A Code-Mixed Dataset for Bangla-English-Hindi Emotion Detection

0
Sign in to get full access
Overview
- Presents a new dataset called EmoMix-3L for emotion detection in code-mixed Bangla-English-Hindi text
- Explores the challenges of analyzing emotions in code-mixed data, which combines multiple languages in the same text
- Provides a comprehensive dataset and benchmarks for evaluating emotion classification models on this task
Plain English Explanation
The paper describes the creation of a new dataset called EmoMix-3L, which is designed to help develop and test machine learning models for detecting emotions in code-mixed text. Code-mixing is a common linguistic phenomenon where people mix multiple languages within the same conversation or written passage.
For example, a person might write a social media post that contains a mix of Bangla, English, and Hindi words and phrases. Analyzing the emotions expressed in this kind of code-mixed text is challenging for AI systems, which are typically trained on data in a single language.
The EmoMix-3L dataset provides a large collection of code-mixed text samples from social media, each labeled with one of several emotion categories (e.g. joy, anger, sadness). By making this dataset publicly available, the researchers hope to spur the development of more robust emotion detection models that can handle the complexities of code-mixing. This could have applications in areas like customer service, mental health monitoring, and content moderation.
Technical Explanation
The paper first reviews prior work on emotion detection in monolingual and code-mixed text, noting the lack of publicly available datasets for the latter task.
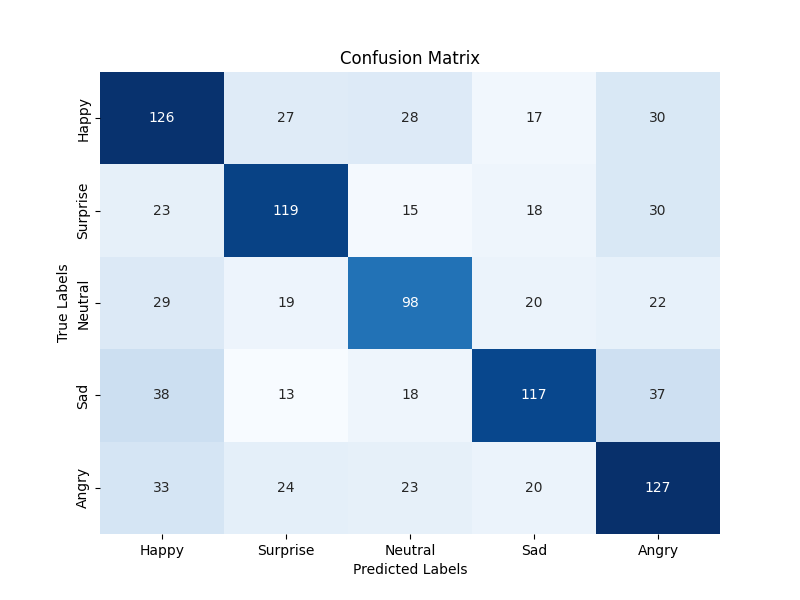
To address this gap, the authors created the EmoMix-3L dataset, which contains over 50,000 code-mixed social media posts in Bangla, English, and Hindi. The data was collected from various online sources and manually annotated with one of seven emotion labels: joy, anger, sadness, fear, disgust, surprise, and neutral.
The authors benchmark several machine learning models on the EmoMix-3L dataset, including transformer-based architectures and code-mixed probes. They find that the code-mixed nature of the data presents significant challenges, with classification performance lagging behind what is typically achievable on monolingual emotion datasets.
Critical Analysis
The paper provides a valuable contribution by introducing the EmoMix-3L dataset, which can help drive progress in zero-shot and few-shot emotion classification for code-mixed text. However, the authors acknowledge several limitations of the current work:
- The dataset is focused on a specific language combination (Bangla-English-Hindi), so its applicability to other code-mixed scenarios is unclear.
- The emotion labels were assigned by human annotators, which can introduce subjectivity and inconsistencies.
- The benchmarked models still have significant room for improvement in classification accuracy, suggesting the need for more advanced techniques.
Future research could explore ways to further improve the quality and diversity of the dataset, as well as investigate model architectures and training strategies that are better suited for the code-mixing challenges.
Conclusion
The EmoMix-3L dataset and benchmarks presented in this paper represent an important step forward in the field of emotion detection for code-mixed text. By making this resource publicly available, the authors have opened up new avenues for research and development in this area. As models become more capable of accurately interpreting the nuanced emotions expressed in code-mixed language, this could lead to significant advancements in applications ranging from social media analysis to mental health support.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
EmoMix-3L: A Code-Mixed Dataset for Bangla-English-Hindi Emotion Detection
Nishat Raihan, Dhiman Goswami, Antara Mahmud, Antonios Anastasopoulos, Marcos Zampieri
Code-mixing is a well-studied linguistic phenomenon that occurs when two or more languages are mixed in text or speech. Several studies have been conducted on building datasets and performing downstream NLP tasks on code-mixed data. Although it is not uncommon to observe code-mixing of three or more languages, most available datasets in this domain contain code-mixed data from only two languages. In this paper, we introduce EmoMix-3L, a novel multi-label emotion detection dataset containing code-mixed data from three different languages. We experiment with several models on EmoMix-3L and we report that MuRIL outperforms other models on this dataset.
Read more5/14/2024

0
BnSentMix: A Diverse Bengali-English Code-Mixed Dataset for Sentiment Analysis
Sadia Alam, Md Farhan Ishmam, Navid Hasin Alvee, Md Shahnewaz Siddique, Md Azam Hossain, Abu Raihan Mostofa Kamal
The widespread availability of code-mixed data can provide valuable insights into low-resource languages like Bengali, which have limited datasets. Sentiment analysis has been a fundamental text classification task across several languages for code-mixed data. However, there has yet to be a large-scale and diverse sentiment analysis dataset on code-mixed Bengali. We address this limitation by introducing BnSentMix, a sentiment analysis dataset on code-mixed Bengali consisting of 20,000 samples with $4$ sentiment labels from Facebook, YouTube, and e-commerce sites. We ensure diversity in data sources to replicate realistic code-mixed scenarios. Additionally, we propose $14$ baseline methods including novel transformer encoders further pre-trained on code-mixed Bengali-English, achieving an overall accuracy of $69.8%$ and an F1 score of $69.1%$ on sentiment classification tasks. Detailed analyses reveal variations in performance across different sentiment labels and text types, highlighting areas for future improvement.
Read more8/20/2024
🔮
0
Code-mixed Sentiment and Hate-speech Prediction
Anjali Yadav, Tanya Garg, Matej Klemen, Matej Ulcar, Basant Agarwal, Marko Robnik Sikonja
Code-mixed discourse combines multiple languages in a single text. It is commonly used in informal discourse in countries with several official languages, but also in many other countries in combination with English or neighboring languages. As recently large language models have dominated most natural language processing tasks, we investigated their performance in code-mixed settings for relevant tasks. We first created four new bilingual pre-trained masked language models for English-Hindi and English-Slovene languages, specifically aimed to support informal language. Then we performed an evaluation of monolingual, bilingual, few-lingual, and massively multilingual models on several languages, using two tasks that frequently contain code-mixed text, in particular, sentiment analysis and offensive language detection in social media texts. The results show that the most successful classifiers are fine-tuned bilingual models and multilingual models, specialized for social media texts, followed by non-specialized massively multilingual and monolingual models, while huge generative models are not competitive. For our affective problems, the models mostly perform slightly better on code-mixed data compared to non-code-mixed data.
Read more5/22/2024
🔎
0
Improving code-mixed hate detection by native sample mixing: A case study for Hindi-English code-mixed scenario
Debajyoti Mazumder, Aakash Kumar, Jasabanta Patro
Hate detection has long been a challenging task for the NLP community. The task becomes complex in a code-mixed environment because the models must understand the context and the hate expressed through language alteration. Compared to the monolingual setup, we see very less work on code-mixed hate as large-scale annotated hate corpora are unavailable to make the study. To overcome this bottleneck, we propose using native language hate samples. We hypothesise that in the era of multilingual language models (MLMs), hate in code-mixed settings can be detected by majorly relying on the native language samples. Even though the NLP literature reports the effectiveness of MLMs on hate detection in many cross-lingual settings, their extensive evaluation in a code-mixed scenario is yet to be done. This paper attempts to fill this gap through rigorous empirical experiments. We considered the Hindi-English code-mixed setup as a case study as we have the linguistic expertise for the same. Some of the interesting observations we got are: (i) adding native hate samples in the code-mixed training set, even in small quantity, improved the performance of MLMs for code-mixed hate detection, (ii) MLMs trained with native samples alone observed to be detecting code-mixed hate to a large extent, (iii) The visualisation of attention scores revealed that, when native samples were included in training, MLMs could better focus on the hate emitting words in the code-mixed context, and (iv) finally, when hate is subjective or sarcastic, naively mixing native samples doesn't help much to detect code-mixed hate. We will release the data and code repository to reproduce the reported results.
Read more6/3/2024