Mixed Diffusion for 3D Indoor Scene Synthesis
2405.21066
0
0
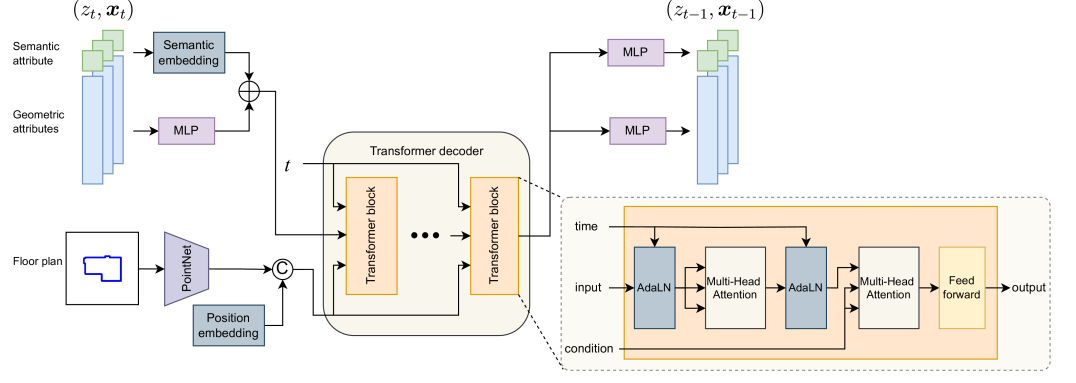
Abstract
Realistic conditional 3D scene synthesis significantly enhances and accelerates the creation of virtual environments, which can also provide extensive training data for computer vision and robotics research among other applications. Diffusion models have shown great performance in related applications, e.g., making precise arrangements of unordered sets. However, these models have not been fully explored in floor-conditioned scene synthesis problems. We present MiDiffusion, a novel mixed discrete-continuous diffusion model architecture, designed to synthesize plausible 3D indoor scenes from given room types, floor plans, and potentially pre-existing objects. We represent a scene layout by a 2D floor plan and a set of objects, each defined by its category, location, size, and orientation. Our approach uniquely implements structured corruption across the mixed discrete semantic and continuous geometric domains, resulting in a better conditioned problem for the reverse denoising step. We evaluate our approach on the 3D-FRONT dataset. Our experimental results demonstrate that MiDiffusion substantially outperforms state-of-the-art autoregressive and diffusion models in floor-conditioned 3D scene synthesis. In addition, our models can handle partial object constraints via a corruption-and-masking strategy without task specific training. We show MiDiffusion maintains clear advantages over existing approaches in scene completion and furniture arrangement experiments.
Create account to get full access
Overview
- This paper introduces a novel diffusion-based approach for generating 3D indoor scenes, called "Mixed Diffusion".
- The method combines multiple diffusion models to generate diverse and realistic 3D scenes, leveraging both high-level scene structure and low-level object details.
- The authors demonstrate that their Mixed Diffusion model outperforms previous state-of-the-art 3D scene generation methods on various benchmarks.
Plain English Explanation
The paper presents a new way to generate 3D indoor scenes using a machine learning technique called "diffusion". Diffusion models work by gradually adding noise to an image or 3D scene, then learning to reverse that process to generate new content.
The key insight of this work is to combine multiple diffusion models - one that focuses on the overall structure and layout of the scene, and another that handles the details of individual objects. By blending these two diffusion processes, the researchers are able to create 3D indoor scenes that are both coherent at a high level and realistic in their small-scale details.
This approach outperforms previous 3D scene generation methods, producing scenes that look more natural and plausible. It could have applications in areas like video game development, architectural design, and virtual environment creation, where generating realistic 3D spaces is important.
Technical Explanation
The paper introduces a "Mixed Diffusion" model for 3D indoor scene synthesis. The core idea is to combine diffusion models for both the overall scene structure and individual object details.
Specifically, the authors use one diffusion model to generate a coarse scene layout, capturing the high-level arrangement of major scene elements like furniture and walls. They then use a second diffusion model to add fine-grained object-level details, such as the shape and appearance of individual chairs, tables, etc. By mixing the outputs of these two diffusion processes, the final 3D scenes exhibit both coherent structure and realistic local details.
The researchers demonstrate the effectiveness of their Mixed Diffusion approach through extensive experiments on several 3D scene generation benchmarks. They show that their model outperforms previous state-of-the-art methods like MVDiff, MoveAnything, and MVDiffusion in terms of both visual quality and diversity of the generated 3D scenes.
Critical Analysis
The paper makes a compelling case for the Mixed Diffusion approach, providing thorough experiments and comparisons to prior work. However, a few potential limitations are worth noting:
- The authors focus mainly on indoor scenes and it's unclear how well the method would generalize to more diverse 3D environments like outdoor scenes or complex multi-story buildings.
- The computational complexity of running two separate diffusion models in parallel may limit the scalability of the approach, especially for real-time applications.
- While the generated scenes look realistic, the paper does not explore the semantic plausibility or functional coherence of the layouts - for example, whether the furniture is arranged in a way that makes sense for how the space would actually be used.
Further research could investigate ways to address these challenges, such as exploring more efficient diffusion model architectures or incorporating additional constraints to ensure the generated scenes are not just visually appealing but also functionally meaningful. Additionally, DifFlow3D provides a relevant approach for reasoning about the 3D scene dynamics.
Conclusion
The Mixed Diffusion model presented in this paper represents a significant advance in the field of 3D indoor scene synthesis. By combining complementary diffusion processes for scene structure and object details, the researchers have developed a method that can generate highly realistic and diverse 3D environments. This work has the potential to impact a wide range of applications, from video game development to architectural design, where the ability to create convincing virtual 3D spaces is crucial.
While the paper highlights the strengths of the Mixed Diffusion approach, it also suggests opportunities for further refinement and expansion. Addressing the potential limitations around generalization, efficiency, and semantic coherence could lead to even more powerful 3D scene generation capabilities in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
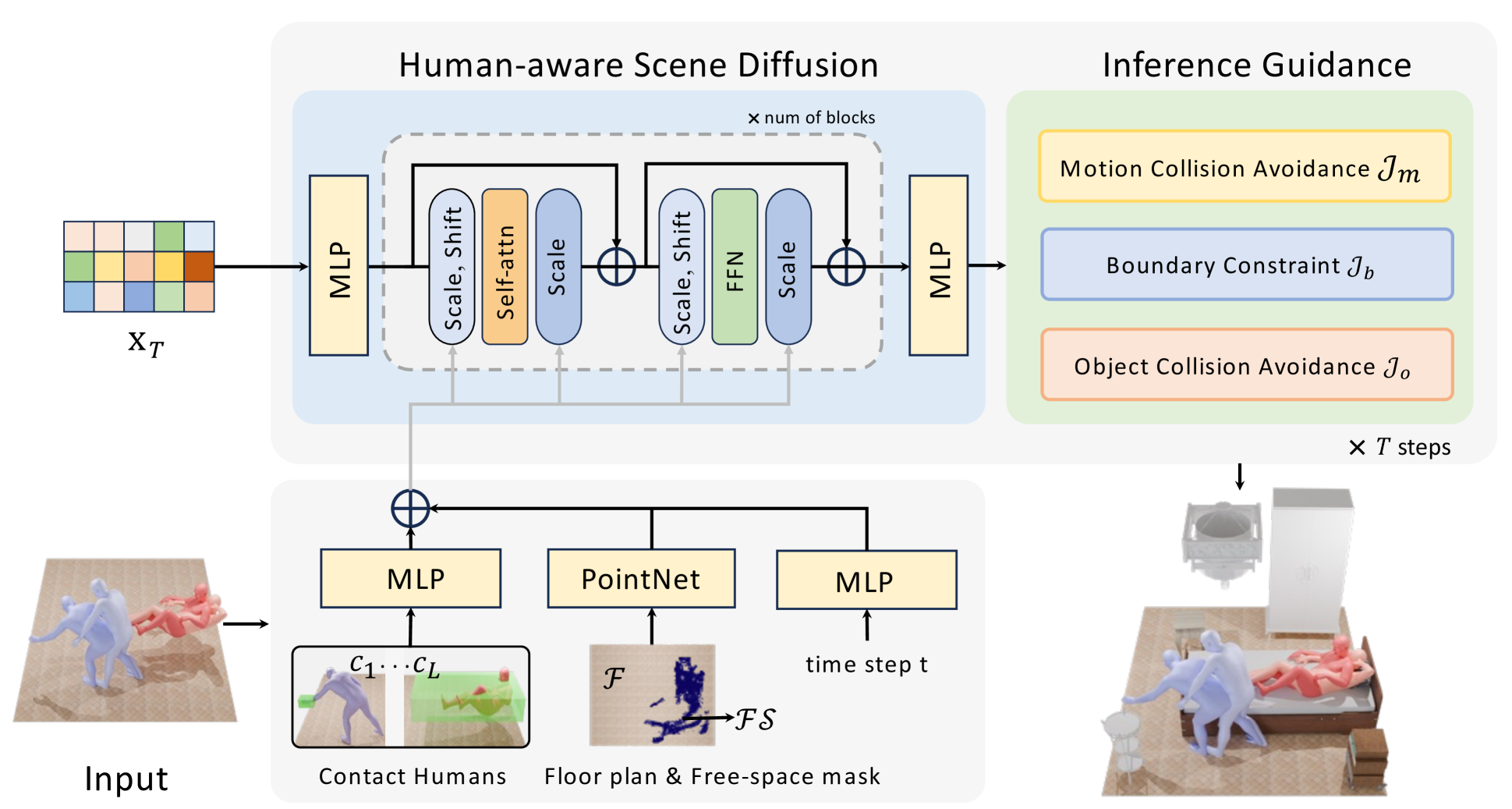
Human-Aware 3D Scene Generation with Spatially-constrained Diffusion Models
Xiaolin Hong, Hongwei Yi, Fazhi He, Qiong Cao
0
0
Generating 3D scenes from human motion sequences supports numerous applications, including virtual reality and architectural design. However, previous auto-regression-based human-aware 3D scene generation methods have struggled to accurately capture the joint distribution of multiple objects and input humans, often resulting in overlapping object generation in the same space. To address this limitation, we explore the potential of diffusion models that simultaneously consider all input humans and the floor plan to generate plausible 3D scenes. Our approach not only satisfies all input human interactions but also adheres to spatial constraints with the floor plan. Furthermore, we introduce two spatial collision guidance mechanisms: human-object collision avoidance and object-room boundary constraints. These mechanisms help avoid generating scenes that conflict with human motions while respecting layout constraints. To enhance the diversity and accuracy of human-guided scene generation, we have developed an automated pipeline that improves the variety and plausibility of human-object interactions in the existing 3D FRONT HUMAN dataset. Extensive experiments on both synthetic and real-world datasets demonstrate that our framework can generate more natural and plausible 3D scenes with precise human-scene interactions, while significantly reducing human-object collisions compared to previous state-of-the-art methods. Our code and data will be made publicly available upon publication of this work.
6/27/2024

Diffusion$^2$: Dynamic 3D Content Generation via Score Composition of Orthogonal Diffusion Models
Zeyu Yang, Zijie Pan, Chun Gu, Li Zhang
0
0
Recent advancements in 3D generation are predominantly propelled by improvements in 3D-aware image diffusion models which are pretrained on Internet-scale image data and fine-tuned on massive 3D data, offering the capability of producing highly consistent multi-view images. However, due to the scarcity of synchronized multi-view video data, it is impractical to adapt this paradigm to 4D generation directly. Despite that, the available video and 3D data are adequate for training video and multi-view diffusion models separately that can provide satisfactory dynamic and geometric priors respectively. To take advantage of both, this paper present Diffusion$^2$, a novel framework for dynamic 3D content creation that reconciles the knowledge about geometric consistency and temporal smoothness from these models to directly sample dense multi-view multi-frame images which can be employed to optimize continuous 4D representation. Specifically, we design a simple yet effective denoising strategy via score composition of pretrained video and multi-view diffusion models based on the probability structure of the target image array. Owing to the high parallelism of the proposed image generation process and the efficiency of the modern 4D reconstruction pipeline, our framework can generate 4D content within few minutes. Additionally, our method circumvents the reliance on 4D data, thereby having the potential to benefit from the scaling of the foundation video and multi-view diffusion models. Extensive experiments demonstrate the efficacy of our proposed framework and its ability to flexibly handle various types of prompts.
5/24/2024

MVDiff: Scalable and Flexible Multi-View Diffusion for 3D Object Reconstruction from Single-View
Emmanuelle Bourigault, Pauline Bourigault
0
0
Generating consistent multiple views for 3D reconstruction tasks is still a challenge to existing image-to-3D diffusion models. Generally, incorporating 3D representations into diffusion model decrease the model's speed as well as generalizability and quality. This paper proposes a general framework to generate consistent multi-view images from single image or leveraging scene representation transformer and view-conditioned diffusion model. In the model, we introduce epipolar geometry constraints and multi-view attention to enforce 3D consistency. From as few as one image input, our model is able to generate 3D meshes surpassing baselines methods in evaluation metrics, including PSNR, SSIM and LPIPS.
6/14/2024

Move Anything with Layered Scene Diffusion
Jiawei Ren, Mengmeng Xu, Jui-Chieh Wu, Ziwei Liu, Tao Xiang, Antoine Toisoul
0
0
Diffusion models generate images with an unprecedented level of quality, but how can we freely rearrange image layouts? Recent works generate controllable scenes via learning spatially disentangled latent codes, but these methods do not apply to diffusion models due to their fixed forward process. In this work, we propose SceneDiffusion to optimize a layered scene representation during the diffusion sampling process. Our key insight is that spatial disentanglement can be obtained by jointly denoising scene renderings at different spatial layouts. Our generated scenes support a wide range of spatial editing operations, including moving, resizing, cloning, and layer-wise appearance editing operations, including object restyling and replacing. Moreover, a scene can be generated conditioned on a reference image, thus enabling object moving for in-the-wild images. Notably, this approach is training-free, compatible with general text-to-image diffusion models, and responsive in less than a second.
4/11/2024