Human-Aware 3D Scene Generation with Spatially-constrained Diffusion Models
2406.18159
0
0
Abstract
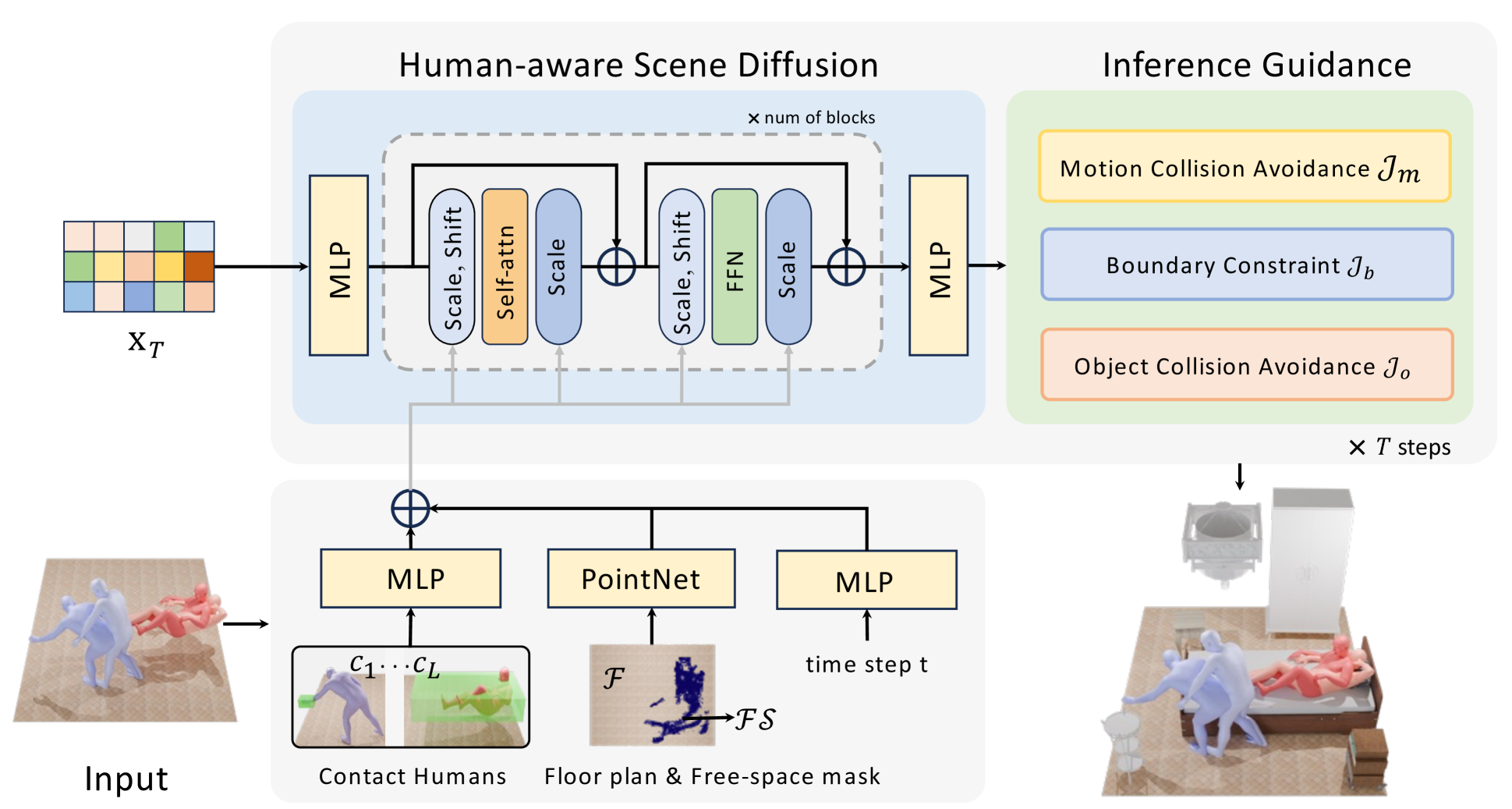
Generating 3D scenes from human motion sequences supports numerous applications, including virtual reality and architectural design. However, previous auto-regression-based human-aware 3D scene generation methods have struggled to accurately capture the joint distribution of multiple objects and input humans, often resulting in overlapping object generation in the same space. To address this limitation, we explore the potential of diffusion models that simultaneously consider all input humans and the floor plan to generate plausible 3D scenes. Our approach not only satisfies all input human interactions but also adheres to spatial constraints with the floor plan. Furthermore, we introduce two spatial collision guidance mechanisms: human-object collision avoidance and object-room boundary constraints. These mechanisms help avoid generating scenes that conflict with human motions while respecting layout constraints. To enhance the diversity and accuracy of human-guided scene generation, we have developed an automated pipeline that improves the variety and plausibility of human-object interactions in the existing 3D FRONT HUMAN dataset. Extensive experiments on both synthetic and real-world datasets demonstrate that our framework can generate more natural and plausible 3D scenes with precise human-scene interactions, while significantly reducing human-object collisions compared to previous state-of-the-art methods. Our code and data will be made publicly available upon publication of this work.
Create account to get full access
Overview
- This paper introduces a novel approach to generating 3D indoor scenes that are aware of human presence and spatial constraints.
- The proposed method uses a spatially-constrained diffusion model to generate 3D scene layouts that accommodate human agents and their spatial requirements.
- The model is trained on a dataset of real-world 3D scenes, and can generate new scenes that are plausible and tailored to human users.
Plain English Explanation
The paper describes a new way to create 3D indoor scenes that take into account the presence and needs of people. The researchers developed a machine learning model that can generate 3D layouts for rooms and buildings that are designed with human users in mind.
Typically, 3D scene generation models focus on creating realistic-looking environments, but don't necessarily consider how people will interact with and use the space. This new approach aims to generate scenes that are not only visually appealing, but also practical and comfortable for human occupants.
The model is trained on a large dataset of real-world 3D scenes. It then uses a technique called "diffusion modeling" to create new scenes that are spatially constrained to accommodate human agents and their requirements, such as needing clear pathways, sufficient personal space, and accessibility. The generated scenes are designed to be realistic and functional for human use.
This could have applications in areas like interior design, architecture, and virtual environments, where creating human-centric 3D spaces is important. By considering the human element upfront, the model can generate scenes that are more intuitive and usable for the people who will ultimately inhabit them.
Technical Explanation
The paper introduces a novel approach to human-aware 3D scene generation using spatially-constrained diffusion models. The key idea is to incorporate human spatial constraints and preferences directly into the scene generation process, in contrast to prior work that generates scenes without explicit consideration of human factors.
The proposed method builds on recent advancements in diffusion models for 3D indoor scene synthesis. However, instead of generating scenes in an unconstrained manner, the authors introduce spatial conditioning to ensure the generated scenes are suitable for human inhabitation.
Specifically, the model learns to generate 3D scene layouts that accommodate human agents and their spatial requirements, such as clear pathways, personal space, and accessibility. This is achieved by training the diffusion model on a dataset of 3D scenes annotated with human agent information, and incorporating spatial constraints during the scene generation process.
The human-centric scene generation approach allows the model to infer the unseen human dynamics and generate 3D layouts that are tailored to human users. The authors demonstrate the effectiveness of their method through extensive experiments, showing that the generated scenes are both visually plausible and spatially suitable for human interaction and motion.
Critical Analysis
The paper presents a promising approach to generating 3D indoor scenes that are designed with human users in mind. By incorporating spatial constraints and human agent information into the scene generation process, the model is able to create layouts that are more practical and comfortable for people to inhabit.
One potential limitation of the research is the reliance on a pre-annotated dataset of 3D scenes. While this allows the model to learn the necessary human-centric spatial relationships, it may limit the model's ability to generalize to novel environments or scenarios not represented in the training data.
Additionally, the paper does not fully explore the potential limitations or edge cases of the spatially-constrained diffusion model. For example, it's unclear how the model would handle complex spatial arrangements or scenarios with conflicting human preferences.
Further research could investigate ways to make the model more adaptable and robust, such as by incorporating additional contextual information or exploring alternative scene generation approaches. Exploring the model's performance on a wider range of 3D environments and human-centric tasks would also help to validate the broader applicability of the approach.
Conclusion
This paper introduces a novel method for generating 3D indoor scenes that are tailored to the needs and preferences of human users. By incorporating spatial constraints and human agent information into a diffusion-based scene generation model, the researchers have developed a system that can create visually plausible and functionally suitable 3D environments.
The human-aware scene generation approach has the potential to significantly improve the relevance and usability of 3D virtual environments in a wide range of applications, from interior design and architecture to gaming and simulation. By prioritizing the human element in the scene creation process, this research represents an important step towards developing more intuitive and user-centric 3D experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Physics-based Scene Layout Generation from Human Motion
Jianan Li, Tao Huang, Qingxu Zhu, Tien-Tsin Wong
0
0
Creating scenes for captured motions that achieve realistic human-scene interaction is crucial for 3D animation in movies or video games. As character motion is often captured in a blue-screened studio without real furniture or objects in place, there may be a discrepancy between the planned motion and the captured one. This gives rise to the need for automatic scene layout generation to relieve the burdens of selecting and positioning furniture and objects. Previous approaches cannot avoid artifacts like penetration and floating due to the lack of physical constraints. Furthermore, some heavily rely on specific data to learn the contact affordances, restricting the generalization ability to different motions. In this work, we present a physics-based approach that simultaneously optimizes a scene layout generator and simulates a moving human in a physics simulator. To attain plausible and realistic interaction motions, our method explicitly introduces physical constraints. To automatically recover and generate the scene layout, we minimize the motion tracking errors to identify the objects that can afford interaction. We use reinforcement learning to perform a dual-optimization of both the character motion imitation controller and the scene layout generator. To facilitate the optimization, we reshape the tracking rewards and devise pose prior guidance obtained from our estimated pseudo-contact labels. We evaluate our method using motions from SAMP and PROX, and demonstrate physically plausible scene layout reconstruction compared with the previous kinematics-based method.
5/22/2024

Human 3Diffusion: Realistic Avatar Creation via Explicit 3D Consistent Diffusion Models
Yuxuan Xue, Xianghui Xie, Riccardo Marin, Gerard Pons-Moll
0
0
Creating realistic avatars from a single RGB image is an attractive yet challenging problem. Due to its ill-posed nature, recent works leverage powerful prior from 2D diffusion models pretrained on large datasets. Although 2D diffusion models demonstrate strong generalization capability, they cannot provide multi-view shape priors with guaranteed 3D consistency. We propose Human 3Diffusion: Realistic Avatar Creation via Explicit 3D Consistent Diffusion. Our key insight is that 2D multi-view diffusion and 3D reconstruction models provide complementary information for each other, and by coupling them in a tight manner, we can fully leverage the potential of both models. We introduce a novel image-conditioned generative 3D Gaussian Splats reconstruction model that leverages the priors from 2D multi-view diffusion models, and provides an explicit 3D representation, which further guides the 2D reverse sampling process to have better 3D consistency. Experiments show that our proposed framework outperforms state-of-the-art methods and enables the creation of realistic avatars from a single RGB image, achieving high-fidelity in both geometry and appearance. Extensive ablations also validate the efficacy of our design, (1) multi-view 2D priors conditioning in generative 3D reconstruction and (2) consistency refinement of sampling trajectory via the explicit 3D representation. Our code and models will be released on https://yuxuan-xue.com/human-3diffusion.
6/13/2024
Mixed Diffusion for 3D Indoor Scene Synthesis
Siyi Hu, Diego Martin Arroyo, Stephanie Debats, Fabian Manhardt, Luca Carlone, Federico Tombari
0
0
Realistic conditional 3D scene synthesis significantly enhances and accelerates the creation of virtual environments, which can also provide extensive training data for computer vision and robotics research among other applications. Diffusion models have shown great performance in related applications, e.g., making precise arrangements of unordered sets. However, these models have not been fully explored in floor-conditioned scene synthesis problems. We present MiDiffusion, a novel mixed discrete-continuous diffusion model architecture, designed to synthesize plausible 3D indoor scenes from given room types, floor plans, and potentially pre-existing objects. We represent a scene layout by a 2D floor plan and a set of objects, each defined by its category, location, size, and orientation. Our approach uniquely implements structured corruption across the mixed discrete semantic and continuous geometric domains, resulting in a better conditioned problem for the reverse denoising step. We evaluate our approach on the 3D-FRONT dataset. Our experimental results demonstrate that MiDiffusion substantially outperforms state-of-the-art autoregressive and diffusion models in floor-conditioned 3D scene synthesis. In addition, our models can handle partial object constraints via a corruption-and-masking strategy without task specific training. We show MiDiffusion maintains clear advantages over existing approaches in scene completion and furniture arrangement experiments.
6/3/2024

Guess The Unseen: Dynamic 3D Scene Reconstruction from Partial 2D Glimpses
Inhee Lee, Byungjun Kim, Hanbyul Joo
0
0
In this paper, we present a method to reconstruct the world and multiple dynamic humans in 3D from a monocular video input. As a key idea, we represent both the world and multiple humans via the recently emerging 3D Gaussian Splatting (3D-GS) representation, enabling to conveniently and efficiently compose and render them together. In particular, we address the scenarios with severely limited and sparse observations in 3D human reconstruction, a common challenge encountered in the real world. To tackle this challenge, we introduce a novel approach to optimize the 3D-GS representation in a canonical space by fusing the sparse cues in the common space, where we leverage a pre-trained 2D diffusion model to synthesize unseen views while keeping the consistency with the observed 2D appearances. We demonstrate our method can reconstruct high-quality animatable 3D humans in various challenging examples, in the presence of occlusion, image crops, few-shot, and extremely sparse observations. After reconstruction, our method is capable of not only rendering the scene in any novel views at arbitrary time instances, but also editing the 3D scene by removing individual humans or applying different motions for each human. Through various experiments, we demonstrate the quality and efficiency of our methods over alternative existing approaches.
4/23/2024