Mixed Semi-Supervised Generalized-Linear-Regression with applications to Deep-Learning and Interpolators

0
📉
Sign in to get full access
Overview
- Presents a method for using unlabeled data to improve the performance of supervised learning models for regression tasks.
- Focuses on Generalized Linear Models (GLM) and linear interpolators, analyzing how to best integrate unlabeled data.
- Proves that incorporating unlabeled data with a non-zero mixing ratio α>0 always improves predictive performance.
- Provides a framework to estimate the optimal mixing ratio α* for best predictive performance.
- Demonstrates substantial improvements over standard supervised models through extensive simulations.
- Applies the methodology to enhance more complex models like deep neural networks for real-world regression tasks.
Plain English Explanation
The paper presents a way to use unlabeled data, or data without known correct answers, to improve the performance of supervised learning models for regression tasks. Regression is the process of predicting a continuous numerical value, like the price of a house, based on input features.
The key idea is to design different mechanisms for incorporating the unlabeled data, each with a mixing parameter α that controls how much weight is given to the unlabeled data. The researchers focus on two specific types of models: Generalized Linear Models (GLMs) and linear interpolators.
After analyzing these different mixing mechanisms, the researchers prove that it is always beneficial to include the unlabeled data with a non-zero mixing ratio α>0. This means the unlabeled data should always be given some weight, rather than being ignored entirely.
Furthermore, the researchers provide a way to estimate the
Through extensive simulations, the researchers demonstrate that their methodology can substantially improve prediction accuracy compared to standard supervised learning models. They also show how the approach can be applied to enhance more complex models like deep neural networks in real-world regression tasks.
Technical Explanation
The paper proposes a methodology for leveraging unlabeled data to design semi-supervised learning (SSL) methods that enhance the predictive performance of supervised learning for regression tasks. The key focus is on Generalized Linear Models (GLMs) and linear interpolators.
The main idea is to incorporate the unlabeled data through different mixing mechanisms, each with a parameter α that controls the weight given to the unlabeled data. The researchers analyze the characteristics of these mixing mechanisms and prove that including the unlabeled data with a non-zero mixing ratio α>0 is always beneficial for predictive performance.
Furthermore, the paper provides a rigorous framework to estimate the optimal mixing ratio α* that delivers the best predictive performance, given the labeled and unlabeled data available.
The effectiveness of the proposed methodology is demonstrated through extensive simulations, which show substantial improvements over standard supervised learning models. The researchers also apply the approach, with intuitive modifications, to enhance the performance of more complex models like deep neural networks in real-world regression tasks.
Critical Analysis
The paper provides a robust theoretical analysis and empirical validation of the benefits of incorporating unlabeled data into supervised learning models for regression tasks. The researchers' proof that a non-zero mixing ratio α>0 is always beneficial is a strong contribution.
However, the paper does not address potential limitations or caveats of the proposed methodology. For example, it is unclear how sensitive the performance improvements are to the quality and distribution of the unlabeled data, or how the methodology would scale to extremely large datasets. Additionally, the researchers do not discuss potential challenges in applying the approach to more complex models like deep neural networks beyond the "intuitive modifications" mentioned.
Further research could explore the robustness of the method to different data characteristics, as well as its scalability and applicability to a wider range of machine learning models. Investigating potential tradeoffs or limitations of the approach would also help provide a more comprehensive understanding of its strengths and weaknesses.
Conclusion
This paper presents a novel methodology for leveraging unlabeled data to improve the predictive performance of supervised learning models for regression tasks. By designing mixing mechanisms that integrate the unlabeled data with a tunable parameter α, the researchers prove that incorporating the unlabeled data is always beneficial and provide a framework to estimate the optimal mixing ratio α*.
The empirical results demonstrate substantial improvements over standard supervised models, and the researchers successfully apply the approach to enhance more complex architectures like deep neural networks. This work highlights the potential of semi-supervised learning techniques to unlock the value of unlabeled data and boost the performance of regression models in a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
0
Mixed Semi-Supervised Generalized-Linear-Regression with applications to Deep-Learning and Interpolators
Oren Yuval, Saharon Rosset
We present a methodology for using unlabeled data to design semi supervised learning (SSL) methods that improve the prediction performance of supervised learning for regression tasks. The main idea is to design different mechanisms for integrating the unlabeled data, and include in each of them a mixing parameter $alpha$, controlling the weight given to the unlabeled data. Focusing on Generalized Linear Models (GLM) and linear interpolators classes of models, we analyze the characteristics of different mixing mechanisms, and prove that in all cases, it is invariably beneficial to integrate the unlabeled data with some nonzero mixing ratio $alpha>0$, in terms of predictive performance. Moreover, we provide a rigorous framework to estimate the best mixing ratio $alpha^*$ where mixed SSL delivers the best predictive performance, while using the labeled and unlabeled data on hand. The effectiveness of our methodology in delivering substantial improvement compared to the standard supervised models, in a variety of settings, is demonstrated empirically through extensive simulation, in a manner that supports the theoretical analysis. We also demonstrate the applicability of our methodology (with some intuitive modifications) to improve more complex models, such as deep neural networks, in real-world regression tasks.
Read more5/29/2024

0
Semi-Supervised Sparse Gaussian Classification: Provable Benefits of Unlabeled Data
Eyar Azar, Boaz Nadler
The premise of semi-supervised learning (SSL) is that combining labeled and unlabeled data yields significantly more accurate models. Despite empirical successes, the theoretical understanding of SSL is still far from complete. In this work, we study SSL for high dimensional sparse Gaussian classification. To construct an accurate classifier a key task is feature selection, detecting the few variables that separate the two classes. % For this SSL setting, we analyze information theoretic lower bounds for accurate feature selection as well as computational lower bounds, assuming the low-degree likelihood hardness conjecture. % Our key contribution is the identification of a regime in the problem parameters (dimension, sparsity, number of labeled and unlabeled samples) where SSL is guaranteed to be advantageous for classification. Specifically, there is a regime where it is possible to construct in polynomial time an accurate SSL classifier. However, % any computationally efficient supervised or unsupervised learning schemes, that separately use only the labeled or unlabeled data would fail. Our work highlights the provable benefits of combining labeled and unlabeled data for {classification and} feature selection in high dimensions. We present simulations that complement our theoretical analysis.
Read more9/6/2024
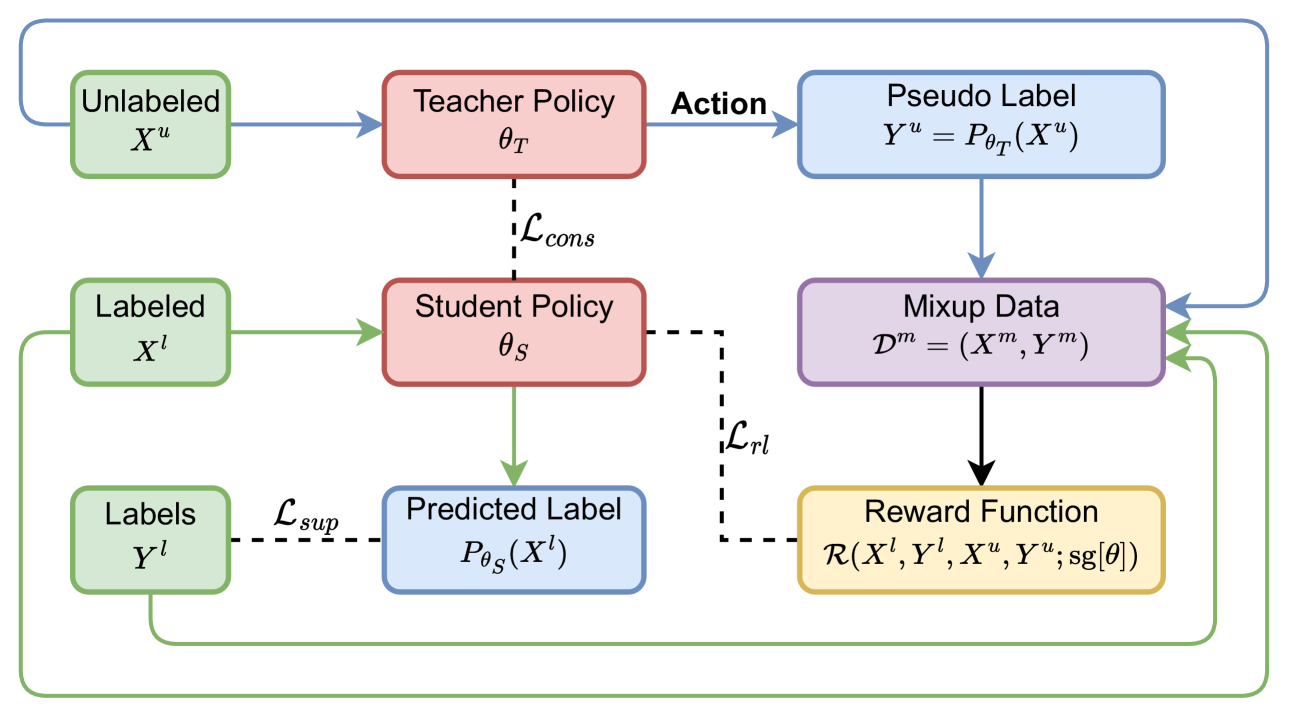
0
Reinforcement Learning-Guided Semi-Supervised Learning
Marzi Heidari, Hanping Zhang, Yuhong Guo
In recent years, semi-supervised learning (SSL) has gained significant attention due to its ability to leverage both labeled and unlabeled data to improve model performance, especially when labeled data is scarce. However, most current SSL methods rely on heuristics or predefined rules for generating pseudo-labels and leveraging unlabeled data. They are limited to exploiting loss functions and regularization methods within the standard norm. In this paper, we propose a novel Reinforcement Learning (RL) Guided SSL method, RLGSSL, that formulates SSL as a one-armed bandit problem and deploys an innovative RL loss based on weighted reward to adaptively guide the learning process of the prediction model. RLGSSL incorporates a carefully designed reward function that balances the use of labeled and unlabeled data to enhance generalization performance. A semi-supervised teacher-student framework is further deployed to increase the learning stability. We demonstrate the effectiveness of RLGSSL through extensive experiments on several benchmark datasets and show that our approach achieves consistent superior performance compared to state-of-the-art SSL methods.
Read more5/6/2024

0
Domain-Guided Weight Modulation for Semi-Supervised Domain Generalization
Chamuditha Jayanaga Galappaththige, Zachary Izzo, Xilin He, Honglu Zhou, Muhammad Haris Khan
Unarguably, deep learning models capable of generalizing to unseen domain data while leveraging a few labels are of great practical significance due to low developmental costs. In search of this endeavor, we study the challenging problem of semi-supervised domain generalization (SSDG), where the goal is to learn a domain-generalizable model while using only a small fraction of labeled data and a relatively large fraction of unlabeled data. Domain generalization (DG) methods show subpar performance under the SSDG setting, whereas semi-supervised learning (SSL) methods demonstrate relatively better performance, however, they are considerably poor compared to the fully-supervised DG methods. Towards handling this new, but challenging problem of SSDG, we propose a novel method that can facilitate the generation of accurate pseudo-labels under various domain shifts. This is accomplished by retaining the domain-level specialism in the classifier during training corresponding to each source domain. Specifically, we first create domain-level information vectors on the fly which are then utilized to learn a domain-aware mask for modulating the classifier's weights. We provide a mathematical interpretation for the effect of this modulation procedure on both pseudo-labeling and model training. Our method is plug-and-play and can be readily applied to different SSL baselines for SSDG. Extensive experiments on six challenging datasets in two different SSDG settings show that our method provides visible gains over the various strong SSL-based SSDG baselines.
Read more9/6/2024