Mixtures of Unsupervised Lexicon Classification

0
🤷
Sign in to get full access
Overview
- Presents a method for unsupervised lexicon classification using a mixture model approach
- Introduces the Bayesian Lexicon (BayesLex) model, which combines multiple unsupervised classification methods
- Demonstrates how BayesLex can outperform individual unsupervised classification techniques on various datasets
Plain English Explanation
This paper describes a new way to automatically classify words or "lexicons" into different categories without any prior training data. The key idea is to combine multiple unsupervised classification methods, each of which looks for different patterns in the data, into a single "mixture model."
The Bayesian Lexicon (BayesLex) model works by first using several unsupervised techniques to independently classify words. It then looks at how these different classifications agree or disagree, and learns a combined model that best explains all the observations.
This mixture approach allows BayesLex to be more accurate than any single unsupervised method on its own. For example, one technique might be good at finding words related to a certain topic, while another is better at identifying words with similar grammatical roles. BayesLex can leverage the strengths of each to make more reliable classifications.
The paper demonstrates that BayesLex outperforms individual unsupervised classifiers on a variety of datasets, including ones for determining the sentiment of words and identifying keyphrases in text. This suggests the mixture modeling approach could be a useful tool for automatically organizing and understanding large vocabularies of words.
Technical Explanation
The core of the BayesLex model is a Dirichlet process mixture, which allows it to learn the optimal number of latent word classes from the data. Each word is then assigned to one or more of these classes based on the observed features.
The features used for classification include traditional bag-of-words representations as well as more sophisticated contextual embeddings. BayesLex combines the outputs of multiple unsupervised algorithms that operate on these different feature sets, effectively ensembling their predictions.
Experiments on sentiment analysis and keyphrase extraction tasks show BayesLex outperforming individual unsupervised baselines by a substantial margin. The authors attribute this to the mixture model's ability to capture diverse lexical patterns that no single method can detect on its own.
Critical Analysis
One limitation of the BayesLex approach is its computational complexity, as training the full Dirichlet process mixture model can be slow, especially on large vocabularies. The authors mention plans to explore more efficient inference techniques in future work.
Additionally, while the paper demonstrates BayesLex's advantages on specific benchmark tasks, it would be valuable to see how the model performs in real-world applications where the lexical categories are less clearly defined. The reliance on predefined evaluation metrics may not fully capture the nuances of unsupervised lexicon classification in practice.
Overall, the mixture modeling approach presented in this paper is a promising direction for unsupervised lexicon analysis. Further research is needed to address the computational scalability and real-world applicability of the BayesLex framework.
Conclusion
This paper introduces the Bayesian Lexicon (BayesLex) model, a novel unsupervised approach to classifying words into semantic categories. By combining multiple unsupervised classification techniques into a single mixture model, BayesLex is able to outperform individual methods on a variety of lexical analysis tasks.
The key insight is that leveraging the complementary strengths of different unsupervised algorithms can lead to more accurate and robust lexicon classifications. This suggests mixture modeling could be a valuable tool for organizing and understanding large vocabularies in an automated way, with potential applications in areas like sentiment analysis, topic modeling, and knowledge extraction.
While the computational complexity of BayesLex remains a challenge, the promising results presented in this paper indicate the mixture modeling approach is a fruitful direction for further research in unsupervised lexicon classification.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
0
Mixtures of Unsupervised Lexicon Classification
Peratham Wiriyathammabhum
This paper presents a mixture version of the method-of-moment unsupervised lexicon classification by an incorporation of a Dirichlet process.
Read more5/28/2024
🌿
0
Hierarchical mixture of discriminative Generalized Dirichlet classifiers
Elvis Togban, Djemel Ziou
This paper presents a discriminative classifier for compositional data. This classifier is based on the posterior distribution of the Generalized Dirichlet which is the discriminative counterpart of Generalized Dirichlet mixture model. Moreover, following the mixture of experts paradigm, we proposed a hierarchical mixture of this classifier. In order to learn the models parameters, we use a variational approximation by deriving an upper-bound for the Generalized Dirichlet mixture. To the best of our knownledge, this is the first time this bound is proposed in the literature. Experimental results are presented for spam detection and color space identification.
Read more5/6/2024

0
Unsupervised Outlier Detection using Random Subspace and Subsampling Ensembles of Dirichlet Process Mixtures
Dongwook Kim, Juyeon Park, Hee Cheol Chung, Seonghyun Jeong
Probabilistic mixture models are recognized as effective tools for unsupervised outlier detection owing to their interpretability and global characteristics. Among these, Dirichlet process mixture models stand out as a strong alternative to conventional finite mixture models for both clustering and outlier detection tasks. Unlike finite mixture models, Dirichlet process mixtures are infinite mixture models that automatically determine the number of mixture components based on the data. Despite their advantages, the adoption of Dirichlet process mixture models for unsupervised outlier detection has been limited by challenges related to computational inefficiency and sensitivity to outliers in the construction of outlier detectors. Additionally, Dirichlet process Gaussian mixtures struggle to effectively model non-Gaussian data with discrete or binary features. To address these challenges, we propose a novel outlier detection method that utilizes ensembles of Dirichlet process Gaussian mixtures. This unsupervised algorithm employs random subspace and subsampling ensembles to ensure efficient computation and improve the robustness of the outlier detector. The ensemble approach further improves the suitability of the proposed method for detecting outliers in non-Gaussian data. Furthermore, our method uses variational inference for Dirichlet process mixtures, which ensures both efficient and rapid computation. Empirical analyses using benchmark datasets demonstrate that our method outperforms existing approaches in unsupervised outlier detection.
Read more7/26/2024
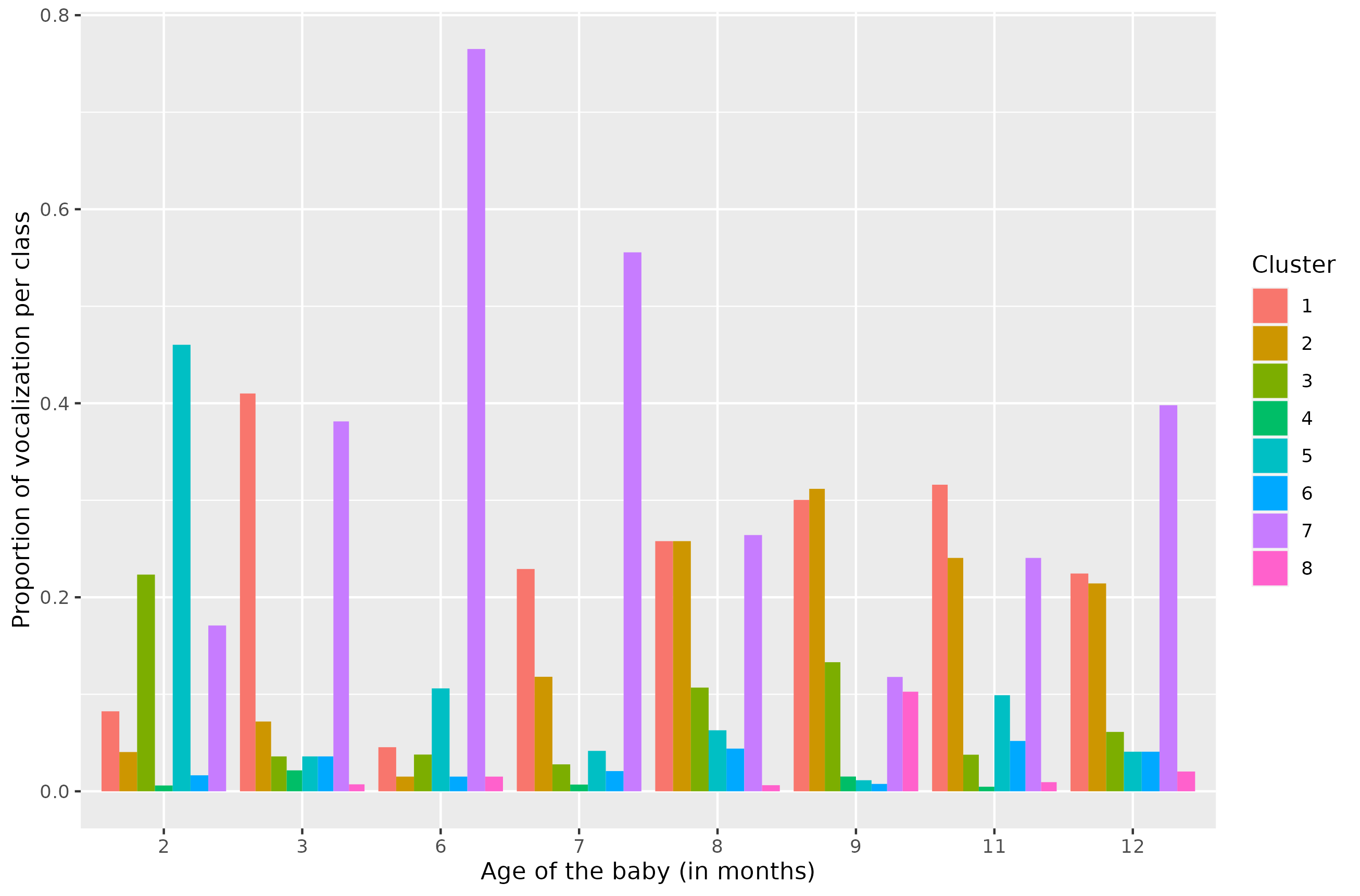
0
Dirichlet process mixture model based on topologically augmented signal representation for clustering infant vocalizations
Guillem Bonafos, Clara Bourot, Pierre Pudlo, Jean-Marc Freyermuth, Laurence Reboul, Samuel Tronc{c}on, Arnaud Rey
Based on audio recordings made once a month during the first 12 months of a child's life, we propose a new method for clustering this set of vocalizations. We use a topologically augmented representation of the vocalizations, employing two persistence diagrams for each vocalization: one computed on the surface of its spectrogram and one on the Takens' embeddings of the vocalization. A synthetic persistent variable is derived for each diagram and added to the MFCCs (Mel-frequency cepstral coefficients). Using this representation, we fit a non-parametric Bayesian mixture model with a Dirichlet process prior to model the number of components. This procedure leads to a novel data-driven categorization of vocal productions. Our findings reveal the presence of 8 clusters of vocalizations, allowing us to compare their temporal distribution and acoustic profiles in the first 12 months of life.
Read more7/9/2024