Dirichlet process mixture model based on topologically augmented signal representation for clustering infant vocalizations

0
Sign in to get full access
Overview
- Dirichlet process mixture model for clustering infant vocalizations
- Uses topologically augmented signal representation to capture vocal tract dynamics
- Aims to improve on existing methods for analyzing and understanding early childhood vocalizations
Plain English Explanation
This research proposes a new machine learning model for analyzing and categorizing the vocalizations of infants and young children. The key idea is to represent the vocal signals in a way that captures the dynamic changes in the shape of the vocal tract over time. This "topological" representation is then used as input to a Dirichlet process mixture model, which can automatically identify different vocal patterns or "clusters" without needing to specify the number of categories in advance.
The researchers argue that this approach can provide deeper insights into the development of speech and language skills in early childhood, by uncovering the acoustic characteristics that distinguish different types of vocalizations. For example, it may help differentiate between playful babbling, distress cries, and early attempts at words. Understanding these patterns could inform efforts to enhance child vocalization classification using phonetically-tuned embeddings or analyze self-supervised speech models for children's speech.
Overall, the goal is to develop more sophisticated computational tools for studying vocal development in infants and young children, with potential applications in speech therapy, language assessment, and early childhood education.
Technical Explanation
The researchers propose a Dirichlet process mixture model (DPMM) for clustering infant vocalizations, using a topologically augmented signal representation as the input features. This representation captures the dynamic changes in the vocal tract shape over time, which the authors argue is crucial for accurately modeling infant vocalizations.
Specifically, they first extract a time-frequency spectrogram from the raw audio signal. They then apply a topological data analysis technique called persistent homology to this spectrogram, which extracts information about the "shape" of the signal as it evolves. This results in a set of topological features that are concatenated with the original spectrogram to form the final input representation.
This topologically augmented input is then fed into a Dirichlet process mixture model, which can automatically determine the number of distinct vocal clusters in the data. The DPMM learns a probabilistic model that associates each vocalization with one of the discovered clusters, without requiring the number of clusters to be specified in advance.
The researchers evaluate their approach on a dataset of infant vocalizations, and show that it outperforms several baseline methods in terms of clustering quality and interpretability of the discovered vocal patterns. They argue that this topologically-informed DPMM can provide useful insights into early vocal development that complement existing multimodal segmentation and unsupervised lexicon classification techniques.
Critical Analysis
One potential limitation of this approach is the reliance on the persistent homology technique to extract the topological features. While this method has been shown to capture important signal properties, it can also be sensitive to noise and may require careful parameter tuning. The authors acknowledge this issue and suggest exploring alternative topological representations as an area for future work.
Additionally, the evaluation is performed on a single dataset, so it's unclear how well the method would generalize to more diverse sets of infant vocalizations. Further testing on larger and more heterogeneous datasets would be helpful to assess the robustness and broader applicability of the proposed model.
Another consideration is the interpretability of the discovered vocal clusters. While the authors claim that the topological features can provide insights into the underlying vocal tract dynamics, it's not always clear how to directly translate these abstract representations into clinically meaningful categories. Incorporating more domain-specific knowledge or collaborating with speech and language experts may be beneficial for improving the interpretability of the results.
Despite these potential limitations, the overall approach of using topologically-informed Dirichlet process mixture models for analyzing infant vocalizations is a promising direction for advancing the state of the art in this important area of research.
Conclusion
This paper presents a novel machine learning model for clustering and analyzing infant vocalizations, using a topologically augmented signal representation as input to a Dirichlet process mixture model. The key innovation is the use of persistent homology to capture the dynamic changes in the vocal tract shape over time, which the authors argue is crucial for accurately modeling early vocal development.
The proposed method shows promising results in terms of clustering quality and the potential to provide insights into different types of vocalizations. While there are some open challenges around interpretability and generalizability, this research represents an important step forward in developing more sophisticated computational tools for studying speech and language acquisition in infants and young children. Further work in this direction could have significant implications for fields like speech therapy, language assessment, and early childhood education.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Dirichlet process mixture model based on topologically augmented signal representation for clustering infant vocalizations
Guillem Bonafos, Clara Bourot, Pierre Pudlo, Jean-Marc Freyermuth, Laurence Reboul, Samuel Tronc{c}on, Arnaud Rey
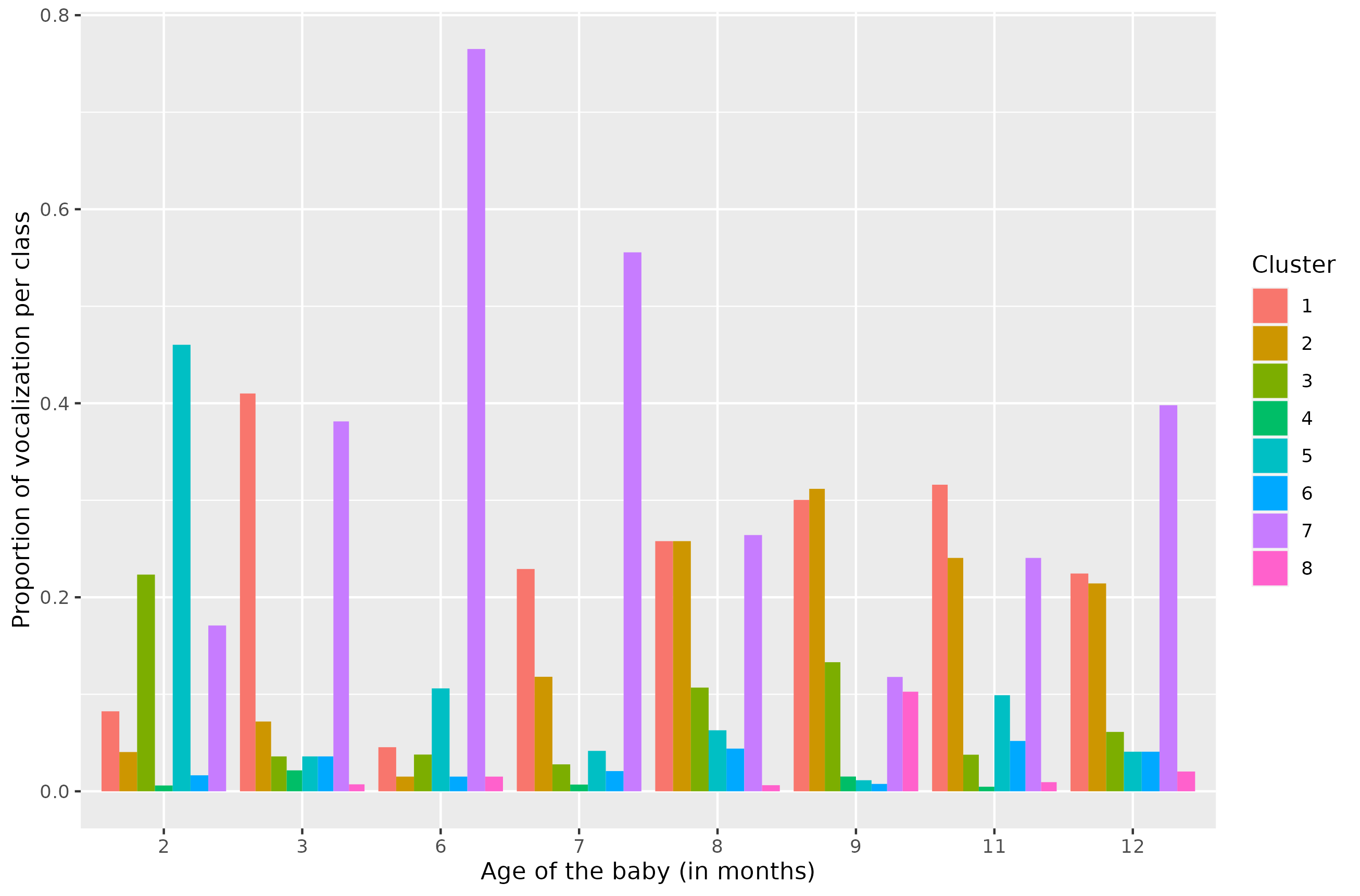
Based on audio recordings made once a month during the first 12 months of a child's life, we propose a new method for clustering this set of vocalizations. We use a topologically augmented representation of the vocalizations, employing two persistence diagrams for each vocalization: one computed on the surface of its spectrogram and one on the Takens' embeddings of the vocalization. A synthetic persistent variable is derived for each diagram and added to the MFCCs (Mel-frequency cepstral coefficients). Using this representation, we fit a non-parametric Bayesian mixture model with a Dirichlet process prior to model the number of components. This procedure leads to a novel data-driven categorization of vocal productions. Our findings reveal the presence of 8 clusters of vocalizations, allowing us to compare their temporal distribution and acoustic profiles in the first 12 months of life.
Read more7/9/2024
🌿
0
Hierarchical mixture of discriminative Generalized Dirichlet classifiers
Elvis Togban, Djemel Ziou
This paper presents a discriminative classifier for compositional data. This classifier is based on the posterior distribution of the Generalized Dirichlet which is the discriminative counterpart of Generalized Dirichlet mixture model. Moreover, following the mixture of experts paradigm, we proposed a hierarchical mixture of this classifier. In order to learn the models parameters, we use a variational approximation by deriving an upper-bound for the Generalized Dirichlet mixture. To the best of our knownledge, this is the first time this bound is proposed in the literature. Experimental results are presented for spam detection and color space identification.
Read more5/6/2024
🏷️
0
Enhancing Child Vocalization Classification with Phonetically-Tuned Embeddings for Assisting Autism Diagnosis
Jialu Li, Mark Hasegawa-Johnson, Karrie Karahalios
The assessment of children at risk of autism typically involves a clinician observing, taking notes, and rating children's behaviors. A machine learning model that can label adult and child audio may largely save labor in coding children's behaviors, helping clinicians capture critical events and better communicate with parents. In this study, we leverage Wav2Vec 2.0 (W2V2), pre-trained on 4300-hour of home audio of children under 5 years old, to build a unified system for tasks of clinician-child speaker diarization and vocalization classification (VC). To enhance children's VC, we build a W2V2 phoneme recognition system for children under 4 years old, and we incorporate its phonetically-tuned embeddings as auxiliary features or recognize pseudo phonetic transcripts as an auxiliary task. We test our method on two corpora (Rapid-ABC and BabbleCor) and obtain consistent improvements. Additionally, we outperform the state-of-the-art performance on the reproducible subset of BabbleCor. Code available at https://huggingface.co/lijialudew
Read more6/7/2024