MLAgentBench: Evaluating Language Agents on Machine Learning Experimentation
2310.03302
0
0
💬
Abstract
A central aspect of machine learning research is experimentation, the process of designing and running experiments, analyzing the results, and iterating towards some positive outcome (e.g., improving accuracy). Could agents driven by powerful language models perform machine learning experimentation effectively? To answer this question, we introduce MLAgentBench, a suite of 13 tasks ranging from improving model performance on CIFAR-10 to recent research problems like BabyLM. For each task, an agent can perform actions like reading/writing files, executing code, and inspecting outputs. We then construct an agent that can perform ML experimentation based on ReAct framework. We benchmark agents based on Claude v1.0, Claude v2.1, Claude v3 Opus, GPT-4, GPT-4-turbo, Gemini-Pro, and Mixtral and find that a Claude v3 Opus agent is the best in terms of success rate. It can build compelling ML models over many tasks in MLAgentBench with 37.5% average success rate. Our agents also display highly interpretable plans and actions. However, the success rates vary considerably; they span from 100% on well-established older datasets to as low as 0% on recent Kaggle challenges created potentially after the underlying LM was trained. Finally, we identify several key challenges for LM-based agents such as long-term planning and reducing hallucination. Our code is released at https://github.com/snap-stanford/MLAgentBench.
Create account to get full access
Overview
- This paper explores whether powerful language models (LMs) can effectively perform machine learning (ML) experimentation and research.
- The authors introduce MLAgentBench, a suite of 13 tasks ranging from improving CIFAR-10 performance to solving recent research problems like BabyLM.
- They construct an agent based on the ReAct framework that can perform ML experimentation by reading/writing files, executing code, and inspecting outputs.
- The agent is benchmarked against various LMs, with the Claude v3 Opus model performing the best, successfully building compelling ML models 37.5% of the time.
- However, the success rates vary greatly, from 100% on older datasets to 0% on recent Kaggle challenges.
- The authors identify key challenges for LM-based agents, such as long-term planning and reducing hallucination.
Plain English Explanation
The paper explores whether powerful language models (LMs) - the large AI systems that can understand and generate human-like text - can be effective at performing the process of machine learning (ML) experimentation.
ML experimentation is a core part of developing new AI models. It involves designing and running experiments, analyzing the results, and then improving the models based on what was learned. The researchers wanted to see if LMs could handle this whole process on their own, without needing a human in the loop.
To test this, the researchers created a set of 13 different ML tasks, ranging from simple image classification to more complex research problems. They built an AI agent that could read and write files, run code, and inspect the outputs - everything needed to do ML experimentation.
This agent was then tested on the 13 tasks using different LM systems, like the GPT-4 and Claude models. The Claude v3 Opus model performed the best, successfully solving the tasks 37.5% of the time on average.
However, the results varied a lot. The agent did very well (100% success) on older, more established datasets, but struggled (0% success) on more recent Kaggle challenge problems. The researchers identified some key challenges for these LM-based agents, like being able to plan and reason over the long term, and avoiding hallucinating false information.
Overall, the results show that while LMs have impressive language capabilities, there are still significant hurdles to overcome before they can match human-level performance on the full process of machine learning experimentation and research.
Technical Explanation
The paper introduces MLAgentBench, a suite of 13 machine learning tasks that an agent can perform to test its ability to conduct ML experimentation. The tasks range from improving performance on the classic CIFAR-10 image classification dataset to solving recent research problems like BabyLM.
The authors then construct an agent based on the ReAct framework that can interact with the MLAgentBench environment by reading and writing files, executing code, and inspecting outputs. This allows the agent to perform the full cycle of ML experimentation - designing experiments, running them, analyzing the results, and iterating to improve the models.
The agent is benchmarked against a range of large language models (LLMs), including Claude v1.0, Claude v2.1, Claude v3 Opus, GPT-4, GPT-4-turbo, Gemini-Pro, and Mixtral. The authors find that the Claude v3 Opus agent performs the best, achieving an average success rate of 37.5% across the 13 tasks in MLAgentBench.
The agents display highly interpretable plans and actions, allowing the researchers to analyze their decision-making process. However, the success rates vary greatly, spanning from 100% on well-established older datasets to as low as 0% on recent Kaggle challenges that were potentially created after the underlying LMs were trained.
The authors identify several key challenges for LM-based agents, including the ability to reason and plan over the long term, as well as the tendency to hallucinate false information. They suggest that addressing these limitations will be crucial for developing LMs that can effectively perform autonomous machine learning experimentation and research.
Critical Analysis
The paper presents an innovative approach to testing the capabilities of large language models (LLMs) in the context of machine learning (ML) experimentation and research. By introducing the MLAgentBench suite of tasks, the authors create a standardized framework for evaluating the performance of AI agents on a range of ML problems.
One strength of the study is the breadth of tasks included in MLAgentBench, which cover a diverse set of ML challenges, from classic benchmarks to more recent research problems. This allows the researchers to assess the agents' capabilities across a wide spectrum of difficulty levels and problem types.
However, the large variation in success rates observed across the different tasks raises some concerns. The fact that the agents performed significantly better on older datasets compared to more recent Kaggle challenges suggests that the LLMs may be limited in their ability to generalize and adapt to novel problems. This highlights the need for further research into improving the long-term reasoning and planning capabilities of these models.
Additionally, the authors' identification of hallucination as a key challenge for LLM-based agents is an important consideration. As these models become more advanced and are tasked with increasingly complex decision-making, the potential for them to generate false or misleading information becomes a significant concern. Developing robust methods for mitigating hallucination will be crucial for the safe and reliable deployment of these systems.
Overall, the MLAgentBench framework and the insights generated from this study represent an important contribution to the field of large language model-based game agents and autonomous agents. The findings serve as a valuable starting point for enhancing general agent capabilities using low-parameter LLMs, and highlight the need for continued research to address the limitations identified in this work.
Conclusion
This paper investigates the potential for powerful language models to effectively perform machine learning experimentation and research. The authors introduce the MLAgentBench suite of tasks and construct an agent that can interact with the environment to design and run experiments, analyze results, and iteratively improve models.
The benchmarking results show that the Claude v3 Opus LLM is the best performing agent, successfully building compelling ML models 37.5% of the time on average. However, the success rates vary greatly, ranging from 100% on well-established datasets to 0% on more recent Kaggle challenges.
The key challenges identified for LLM-based agents include long-term planning and reasoning, as well as the tendency to hallucinate false information. Addressing these limitations will be crucial for developing autonomous AI systems that can match human-level performance on the full process of machine learning research and experimentation.
Overall, this study represents an important step forward in exploring the capabilities of autonomous agents through the lens of large language models. The MLAgentBench framework and the insights generated from this work can help drive progress in enhancing general agent capabilities using low-parameter LLMs and advancing the field of large language model-based game agents.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
ML-Bench: Evaluating Large Language Models and Agents for Machine Learning Tasks on Repository-Level Code
Xiangru Tang, Yuliang Liu, Zefan Cai, Yanjun Shao, Junjie Lu, Yichi Zhang, Zexuan Deng, Helan Hu, Kaikai An, Ruijun Huang, Shuzheng Si, Sheng Chen, Haozhe Zhao, Liang Chen, Yan Wang, Tianyu Liu, Zhiwei Jiang, Baobao Chang, Yin Fang, Yujia Qin, Wangchunshu Zhou, Yilun Zhao, Arman Cohan, Mark Gerstein
0
0
Despite Large Language Models (LLMs) like GPT-4 achieving impressive results in function-level code generation, they struggle with repository-scale code understanding (e.g., coming up with the right arguments for calling routines), requiring a deeper comprehension of complex file interactions. Also, recently, people have developed LLM agents that attempt to interact with repository code (e.g., compiling and evaluating its execution), prompting the need to evaluate their performance. These gaps have motivated our development of ML-Bench, a benchmark rooted in real-world programming applications that leverage existing code repositories to perform tasks. Addressing the need for LLMs to interpret long code contexts and translate instructions into precise, executable scripts, ML-Bench encompasses annotated 9,641 examples across 18 GitHub repositories, challenging LLMs to accommodate user-specified arguments and documentation intricacies effectively. To evaluate both LLMs and AI agents, two setups are employed: ML-LLM-Bench for assessing LLMs' text-to-code conversion within a predefined deployment environment, and ML-Agent-Bench for testing autonomous agents in an end-to-end task execution within a Linux sandbox environment. Our findings indicate that while GPT-4o leads with a Pass@5 rate surpassing 50%, there remains significant scope for improvement, highlighted by issues such as hallucinated outputs and difficulties with bash script generation. Notably, in the more demanding ML-Agent-Bench, GPT-4o achieves a 76.47% success rate, reflecting the efficacy of iterative action and feedback in complex task resolution. Our code, dataset, and models are available at https://github.com/gersteinlab/ML-bench.
6/19/2024
Experiential Co-Learning of Software-Developing Agents
Chen Qian, Yufan Dang, Jiahao Li, Wei Liu, Zihao Xie, Yifei Wang, Weize Chen, Cheng Yang, Xin Cong, Xiaoyin Che, Zhiyuan Liu, Maosong Sun
0
0
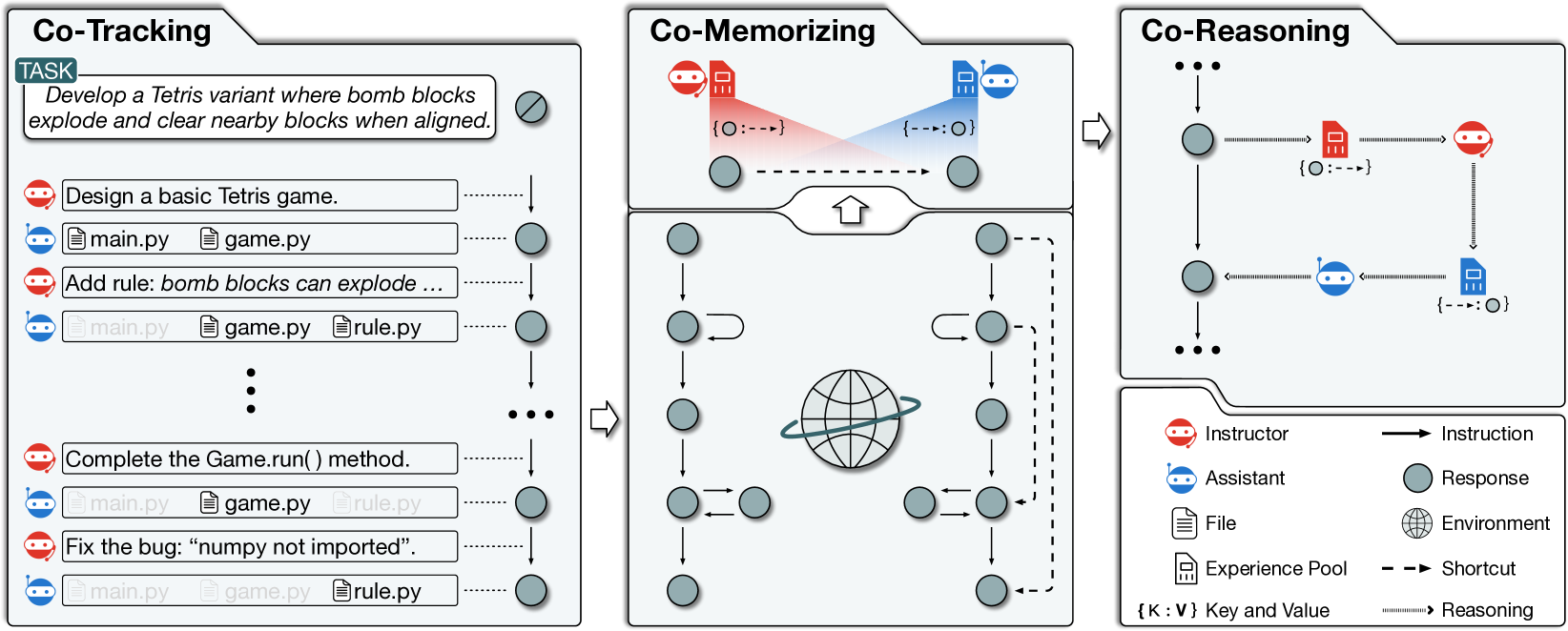
Recent advancements in large language models (LLMs) have brought significant changes to various domains, especially through LLM-driven autonomous agents. A representative scenario is in software development, where LLM agents demonstrate efficient collaboration, task division, and assurance of software quality, markedly reducing the need for manual involvement. However, these agents frequently perform a variety of tasks independently, without benefiting from past experiences, which leads to repeated mistakes and inefficient attempts in multi-step task execution. To this end, we introduce Experiential Co-Learning, a novel LLM-agent learning framework in which instructor and assistant agents gather shortcut-oriented experiences from their historical trajectories and use these past experiences for future task execution. The extensive experiments demonstrate that the framework enables agents to tackle unseen software-developing tasks more effectively. We anticipate that our insights will guide LLM agents towards enhanced autonomy and contribute to their evolutionary growth in cooperative learning. The code and data are available at https://github.com/OpenBMB/ChatDev.
6/6/2024

DS-Agent: Automated Data Science by Empowering Large Language Models with Case-Based Reasoning
Siyuan Guo, Cheng Deng, Ying Wen, Hechang Chen, Yi Chang, Jun Wang
0
0
In this work, we investigate the potential of large language models (LLMs) based agents to automate data science tasks, with the goal of comprehending task requirements, then building and training the best-fit machine learning models. Despite their widespread success, existing LLM agents are hindered by generating unreasonable experiment plans within this scenario. To this end, we present DS-Agent, a novel automatic framework that harnesses LLM agent and case-based reasoning (CBR). In the development stage, DS-Agent follows the CBR framework to structure an automatic iteration pipeline, which can flexibly capitalize on the expert knowledge from Kaggle, and facilitate consistent performance improvement through the feedback mechanism. Moreover, DS-Agent implements a low-resource deployment stage with a simplified CBR paradigm to adapt past successful solutions from the development stage for direct code generation, significantly reducing the demand on foundational capabilities of LLMs. Empirically, DS-Agent with GPT-4 achieves 100% success rate in the development stage, while attaining 36% improvement on average one pass rate across alternative LLMs in the deployment stage. In both stages, DS-Agent achieves the best rank in performance, costing $1.60 and $0.13 per run with GPT-4, respectively. Our data and code are open-sourced at https://github.com/guosyjlu/DS-Agent.
5/29/2024
A Survey on Large Language Model-Based Game Agents
Sihao Hu, Tiansheng Huang, Fatih Ilhan, Selim Tekin, Gaowen Liu, Ramana Kompella, Ling Liu
0
0
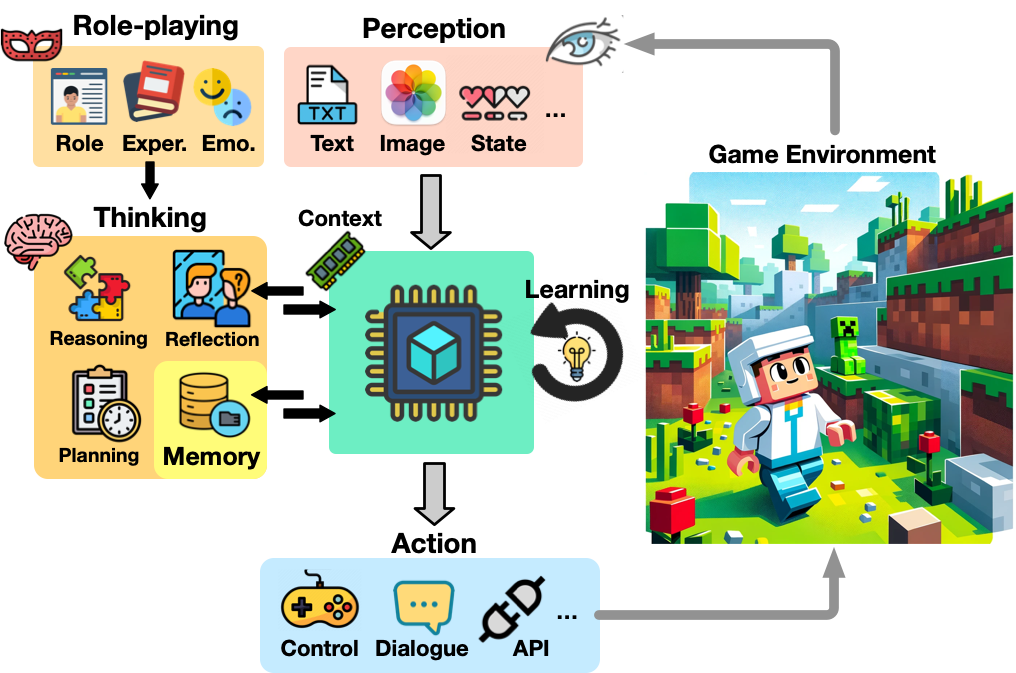
The development of game agents holds a critical role in advancing towards Artificial General Intelligence (AGI). The progress of LLMs and their multimodal counterparts (MLLMs) offers an unprecedented opportunity to evolve and empower game agents with human-like decision-making capabilities in complex computer game environments. This paper provides a comprehensive overview of LLM-based game agents from a holistic viewpoint. First, we introduce the conceptual architecture of LLM-based game agents, centered around six essential functional components: perception, memory, thinking, role-playing, action, and learning. Second, we survey existing representative LLM-based game agents documented in the literature with respect to methodologies and adaptation agility across six genres of games, including adventure, communication, competition, cooperation, simulation, and crafting & exploration games. Finally, we present an outlook of future research and development directions in this burgeoning field. A curated list of relevant papers is maintained and made accessible at: https://github.com/git-disl/awesome-LLM-game-agent-papers.
4/3/2024