ML-SemReg: Boosting Point Cloud Registration with Multi-level Semantic Consistency

0

Sign in to get full access
Overview
- This paper introduces ML-SemReg, a novel approach to boosting point cloud registration by incorporating multi-level semantic consistency.
- The key innovation is leveraging semantic information at different levels to guide the registration process, improving accuracy and robustness.
- The proposed method outperforms state-of-the-art point cloud registration techniques on various datasets and tasks.
Plain English Explanation
Point cloud registration is the process of aligning and combining multiple 3D point cloud scans into a unified model. This is an important task in fields like robotics, augmented reality, and 3D reconstruction. However, traditional registration methods can struggle with challenging scenarios like partial overlap, outliers, and noisy data.
The ML-SemReg approach introduced in this paper aims to address these limitations by incorporating semantic information into the registration process. Semantic information refers to the high-level meaning or context of the data, such as identifying the type of object (e.g., chair, table, wall) that a point cloud represents.
The key idea is to use this semantic information at multiple levels - from the individual points up to larger structures - to guide the alignment of the point clouds. This multi-level semantic consistency helps the registration algorithm better understand the underlying scene and make more accurate decisions about how to combine the scans.
For example, if the system knows that certain points represent a table leg, it can use that semantic knowledge to ensure the table legs are properly aligned, even if the overall point cloud data is noisy or incomplete. This semantic-aware approach builds on previous work and helps make the registration more robust and effective.
Technical Explanation
The ML-SemReg framework consists of three main components:
-
Semantic Embedding Extraction: The input point clouds are first processed to extract semantic information at multiple levels, including individual points, local patches, and global structures. This is done using deep learning models trained on labeled 3D data.
-
Multi-level Semantic Consistency Regularization: During the registration optimization, ML-SemReg incorporates regularization terms that encourage alignment of the semantic information across the point clouds at different scales. This helps guide the registration process towards semantically coherent solutions.
-
Iterative Refinement: The registration is performed in an iterative manner, alternating between optimizing the rigid transformation and updating the semantic embeddings. This allows the system to progressively refine the alignment while incorporating the latest semantic insights.
The authors evaluate ML-SemReg on several standard point cloud registration benchmarks, including KITTI, 3DMatch, and ModelNet40. They demonstrate significant improvements over state-of-the-art methods, particularly in challenging scenarios with partial overlap, clutter, and noise.
Critical Analysis
The ML-SemReg paper presents a compelling approach to improving point cloud registration by leveraging semantic information. The key strength of the method is its ability to guide the registration process using high-level contextual cues, which helps overcome the limitations of purely geometric techniques.
One potential limitation is the reliance on accurate semantic segmentation, which can be challenging to obtain, especially for complex real-world scenes. The authors acknowledge this and suggest further research into semi-supervised or self-supervised semantic extraction methods to address this challenge.
Additionally, the iterative refinement process, while effective, may increase the computational complexity of the algorithm compared to single-stage registration approaches. The authors could explore ways to balance the trade-off between accuracy and efficiency, perhaps by introducing adaptive strategies or parallelization techniques.
Overall, the ML-SemReg method represents a significant advancement in the field of point cloud registration and demonstrates the potential benefits of incorporating semantic understanding into 3D data processing tasks. As the authors suggest, this work could inspire further research into the intersection of geometry, semantics, and machine learning for a wide range of 3D perception and reconstruction applications.
Conclusion
The ML-SemReg paper introduces a novel point cloud registration approach that leverages multi-level semantic consistency to boost accuracy and robustness. By incorporating semantic information at different scales, the method can better understand the underlying structure of the 3D data and guide the registration process accordingly.
The proposed framework outperforms state-of-the-art techniques on various benchmarks, showcasing the benefits of this semantic-aware registration strategy. While the method has some limitations, such as the reliance on accurate semantic segmentation, the core idea of integrating high-level contextual cues into 3D data processing tasks holds great promise for advancing the state of the art in areas like robotics, augmented reality, and 3D reconstruction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ML-SemReg: Boosting Point Cloud Registration with Multi-level Semantic Consistency
Shaocheng Yan, Pengcheng Shi, Jiayuan Li
Recent advances in point cloud registration mostly leverage geometric information. Although these methods have yielded promising results, they still struggle with problems of low overlap, thus limiting their practical usage. In this paper, we propose ML-SemReg, a plug-and-play point cloud registration framework that fully exploits semantic information. Our key insight is that mismatches can be categorized into two types, i.e., inter- and intra-class, after rendering semantic clues, and can be well addressed by utilizing multi-level semantic consistency. We first propose a Group Matching module to address inter-class mismatching, outputting multiple matching groups that inherently satisfy Local Semantic Consistency. For each group, a Mask Matching module based on Scene Semantic Consistency is then introduced to suppress intra-class mismatching. Benefit from those two modules, ML-SemReg generates correspondences with a high inlier ratio. Extensive experiments demonstrate excellent performance and robustness of ML-SemReg, e.g., in hard-cases of the KITTI dataset, the Registration Recall of MAC increases by almost 34 percentage points when our ML-SemReg is equipped. Code is available at url{https://github.com/Laka-3DV/ML-SemReg}
Read more7/16/2024

0
SGOR: Outlier Removal by Leveraging Semantic and Geometric Information for Robust Point Cloud Registration
Guiyu Zhao, Zhentao Guo, Hongbin Ma
In this paper, we introduce a new outlier removal method that fully leverages geometric and semantic information, to achieve robust registration. Current semantic-based registration methods only use semantics for point-to-point or instance semantic correspondence generation, which has two problems. First, these methods are highly dependent on the correctness of semantics. They perform poorly in scenarios with incorrect semantics and sparse semantics. Second, the use of semantics is limited only to the correspondence generation, resulting in bad performance in the weak geometry scene. To solve these problems, on the one hand, we propose secondary ground segmentation and loose semantic consistency based on regional voting. It improves the robustness to semantic correctness by reducing the dependence on single-point semantics. On the other hand, we propose semantic-geometric consistency for outlier removal, which makes full use of semantic information and significantly improves the quality of correspondences. In addition, a two-stage hypothesis verification is proposed, which solves the problem of incorrect transformation selection in the weak geometry scene. In the outdoor dataset, our method demonstrates superior performance, boosting a 22.5 percentage points improvement in registration recall and achieving better robustness under various conditions. Our code is available.
Read more7/10/2024
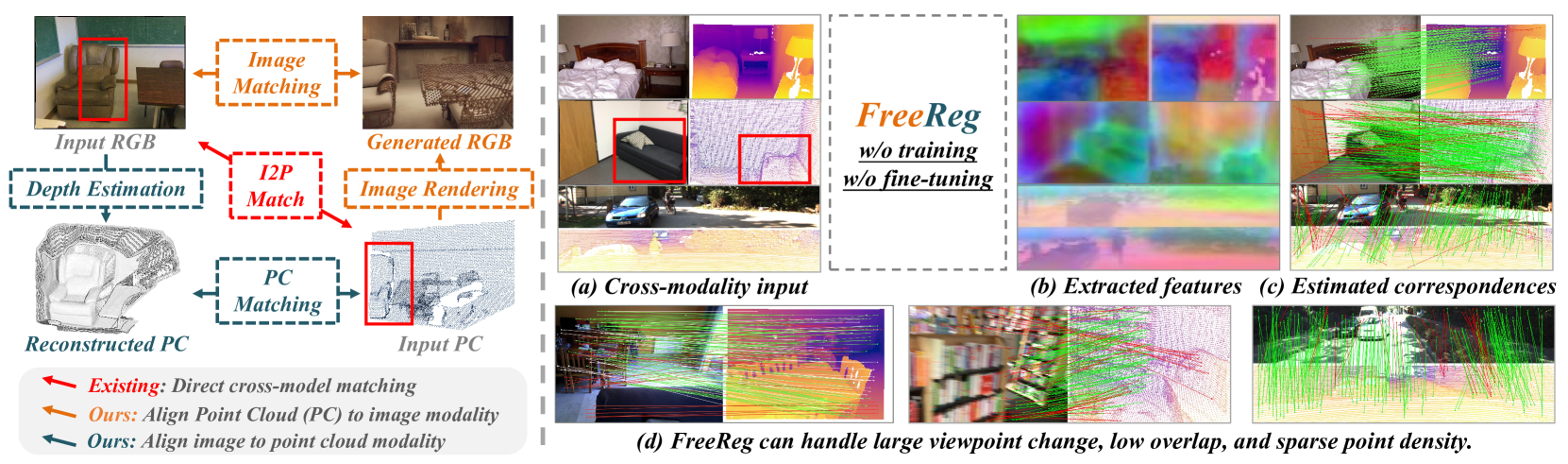
0
FreeReg: Image-to-Point Cloud Registration Leveraging Pretrained Diffusion Models and Monocular Depth Estimators
Haiping Wang, Yuan Liu, Bing Wang, Yujing Sun, Zhen Dong, Wenping Wang, Bisheng Yang
Matching cross-modality features between images and point clouds is a fundamental problem for image-to-point cloud registration. However, due to the modality difference between images and points, it is difficult to learn robust and discriminative cross-modality features by existing metric learning methods for feature matching. Instead of applying metric learning on cross-modality data, we propose to unify the modality between images and point clouds by pretrained large-scale models first, and then establish robust correspondence within the same modality. We show that the intermediate features, called diffusion features, extracted by depth-to-image diffusion models are semantically consistent between images and point clouds, which enables the building of coarse but robust cross-modality correspondences. We further extract geometric features on depth maps produced by the monocular depth estimator. By matching such geometric features, we significantly improve the accuracy of the coarse correspondences produced by diffusion features. Extensive experiments demonstrate that without any task-specific training, direct utilization of both features produces accurate image-to-point cloud registration. On three public indoor and outdoor benchmarks, the proposed method averagely achieves a 20.6 percent improvement in Inlier Ratio, a three-fold higher Inlier Number, and a 48.6 percent improvement in Registration Recall than existing state-of-the-arts.
Read more4/16/2024

0
Incremental Multiview Point Cloud Registration
Xiaoya Cheng, Yu Liu, Maojun Zhang, Shen Yan
In this paper, we present a novel approach for multiview point cloud registration. Different from previous researches that typically employ a global scheme for multiview registration, we propose to adopt an incremental pipeline to progressively align scans into a canonical coordinate system. Specifically, drawing inspiration from image-based 3D reconstruction, our approach first builds a sparse scan graph with scan retrieval and geometric verification. Then, we perform incremental registration via initialization, next scan selection and registration, Track create and continue, and Bundle Adjustment. Additionally, for detector-free matchers, we incorporate a Track refinement process. This process primarily constructs a coarse multiview registration and refines the model by adjusting the positions of the keypoints on the Track. Experiments demonstrate that the proposed framework outperforms existing multiview registration methods on three benchmark datasets. The code is available at https://github.com/Choyaa/IncreMVR.
Read more7/9/2024