ML-SUPERB 2.0: Benchmarking Multilingual Speech Models Across Modeling Constraints, Languages, and Datasets
2406.08641
0
0
🗣️
Abstract
ML-SUPERB evaluates self-supervised learning (SSL) models on the tasks of language identification and automatic speech recognition (ASR). This benchmark treats the models as feature extractors and uses a single shallow downstream model, which can be fine-tuned for a downstream task. However, real-world use cases may require different configurations. This paper presents ML-SUPERB~2.0, which is a new benchmark for evaluating pre-trained SSL and supervised speech models across downstream models, fine-tuning setups, and efficient model adaptation approaches. We find performance improvements over the setup of ML-SUPERB. However, performance depends on the downstream model design. Also, we find large performance differences between languages and datasets, suggesting the need for more targeted approaches to improve multilingual ASR performance.
Create account to get full access
Overview
- The paper introduces ML-SUPERB 2.0, a benchmark for evaluating multilingual speech models across different modeling constraints, languages, and datasets.
- It explores the performance of various multilingual speech models, including mHuBERT, SSHR, and Towards Supervised Performance, on diverse tasks and settings.
- The benchmark aims to provide a comprehensive understanding of the capabilities and limitations of current multilingual speech models.
Plain English Explanation
The paper introduces a new tool called ML-SUPERB 2.0 that allows researchers to test and compare different speech models designed to work across multiple languages. This is important because many real-world applications, like voice assistants or translation services, need to handle a variety of languages.
The researchers used ML-SUPERB 2.0 to evaluate several existing speech models, including mHuBERT, SSHR, and Towards Supervised Performance. They looked at how well these models performed on different tasks, like transcribing speech or identifying speakers, and how they handled various constraints, like having limited training data or needing to work with many languages at once.
The goal was to get a better understanding of the strengths and weaknesses of current multilingual speech models, so that researchers and developers can build even better systems in the future. By having a standardized way to test these models, the researchers hope to accelerate progress in this important area of artificial intelligence.
Technical Explanation
The paper introduces ML-SUPERB 2.0, a benchmark for evaluating multilingual speech models across different modeling constraints, languages, and datasets. The benchmark builds upon the original SUPERB benchmark, which focused on monolingual speech models, and aims to provide a more comprehensive evaluation of multilingual speech systems.
The researchers used ML-SUPERB 2.0 to assess the performance of several state-of-the-art multilingual speech models, including mHuBERT, SSHR, and Towards Supervised Performance. These models were evaluated on a diverse set of tasks, such as speech recognition, speaker identification, and emotion recognition, using datasets covering over 30 languages.
The benchmark also explored the models' performance under various constraints, such as having limited training data or needing to handle a large number of languages simultaneously. This allowed the researchers to gain insights into the strengths, weaknesses, and trade-offs of different multilingual speech modeling approaches.
Critical Analysis
The paper provides a comprehensive and rigorous evaluation of multilingual speech models, which is crucial for understanding the current state of the art and guiding future research. However, the authors acknowledge several limitations and areas for further investigation.
One notable limitation is the reliance on relatively small and unbalanced datasets, which may not fully capture the complexity and diversity of real-world multilingual speech data. The authors suggest that expanding the benchmark to include larger, more representative datasets would be a valuable direction for future work.
Additionally, the paper focuses primarily on the performance of the models on specific tasks and does not delve deeply into the underlying factors that contribute to their successes or failures. Exploring the model architectures, training strategies, and other design choices in more detail could shed light on the key drivers of multilingual speech performance.
Finally, the paper does not address the broader implications and societal impact of the evaluated models, such as their potential to enable more accessible and inclusive speech technologies, especially for underserved or marginalized language communities. Incorporating these considerations into future research and benchmarking efforts would be an important step forward.
Conclusion
The ML-SUPERB 2.0 benchmark introduced in this paper represents a significant advancement in the field of multilingual speech modeling. By providing a standardized framework for evaluating the performance of various models across a wide range of tasks and constraints, the authors have laid the groundwork for more systematic and insightful comparisons of the state of the art.
The findings from this study offer valuable insights into the current capabilities and limitations of multilingual speech models, which can inform the development of more robust and versatile systems in the future. As the field continues to evolve, the ML-SUPERB 2.0 benchmark can serve as a valuable tool for driving progress and ensuring that advancements in multilingual speech technology benefit diverse communities around the world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Seamless Language Expansion: Enhancing Multilingual Mastery in Self-Supervised Models
Jing Xu, Minglin Wu, Xixin Wu, Helen Meng
0
0
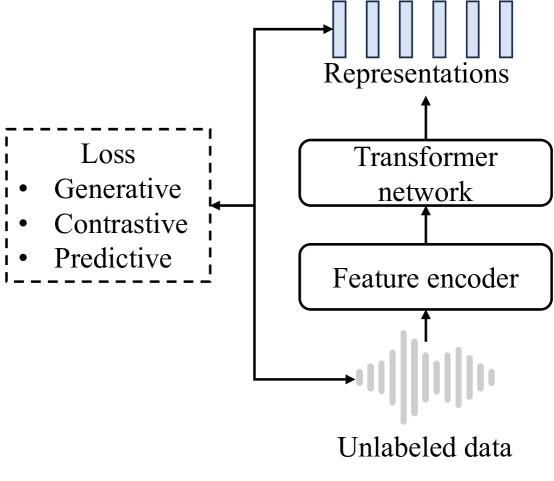
Self-supervised (SSL) models have shown great performance in various downstream tasks. However, they are typically developed for limited languages, and may encounter new languages in real-world. Developing a SSL model for each new language is costly. Thus, it is vital to figure out how to efficiently adapt existed SSL models to a new language without impairing its original abilities. We propose adaptation methods which integrate LoRA to existed SSL models to extend new language. We also develop preservation strategies which include data combination and re-clustering to retain abilities on existed languages. Applied to mHuBERT, we investigate their effectiveness on speech re-synthesis task. Experiments show that our adaptation methods enable mHuBERT to be applied to a new language (Mandarin) with MOS value increased about 1.6 and the relative value of WER reduced up to 61.72%. Also, our preservation strategies ensure that the performance on both existed and new languages remains intact.
6/21/2024

mHuBERT-147: A Compact Multilingual HuBERT Model
Marcely Zanon Boito, Vivek Iyer, Nikolaos Lagos, Laurent Besacier, Ioan Calapodescu
0
0
We present mHuBERT-147, the first general-purpose massively multilingual HuBERT speech representation model trained on 90K hours of clean, open-license data. To scale up the multi-iteration HuBERT approach, we use faiss-based clustering, achieving 5.2x faster label assignment than the original method. We also apply a new multilingual batching up-sampling strategy, leveraging both language and dataset diversity. After 3 training iterations, our compact 95M parameter mHuBERT-147 outperforms larger models trained on substantially more data. We rank second and first on the ML-SUPERB 10min and 1h leaderboards, with SOTA scores for 3 tasks. Across ASR/LID tasks, our model consistently surpasses XLS-R (300M params; 436K hours) and demonstrates strong competitiveness against the much larger MMS (1B params; 491K hours). Our findings indicate that mHuBERT-147 is a promising model for multilingual speech tasks, offering an unprecedented balance between high performance and parameter efficiency.
6/28/2024
🗣️
SSHR: Leveraging Self-supervised Hierarchical Representations for Multilingual Automatic Speech Recognition
Hongfei Xue, Qijie Shao, Kaixun Huang, Peikun Chen, Jie Liu, Lei Xie
0
0
Multilingual automatic speech recognition (ASR) systems have garnered attention for their potential to extend language coverage globally. While self-supervised learning (SSL) models, like MMS, have demonstrated their effectiveness in multilingual ASR, it is worth noting that various layers' representations potentially contain distinct information that has not been fully leveraged. In this study, we propose a novel method that leverages self-supervised hierarchical representations (SSHR) to fine-tune the MMS model. We first analyze the different layers of MMS and show that the middle layers capture language-related information, and the high layers encode content-related information, which gradually decreases in the final layers. Then, we extract a language-related frame from correlated middle layers and guide specific language extraction through self-attention mechanisms. Additionally, we steer the model toward acquiring more content-related information in the final layers using our proposed Cross-CTC. We evaluate SSHR on two multilingual datasets, Common Voice and ML-SUPERB, and the experimental results demonstrate that our method achieves state-of-the-art performance.
4/30/2024
A dual task learning approach to fine-tune a multilingual semantic speech encoder for Spoken Language Understanding
Gaelle Laperri`ere, Sahar Ghannay, Bassam Jabaian, Yannick Est`eve
0
0
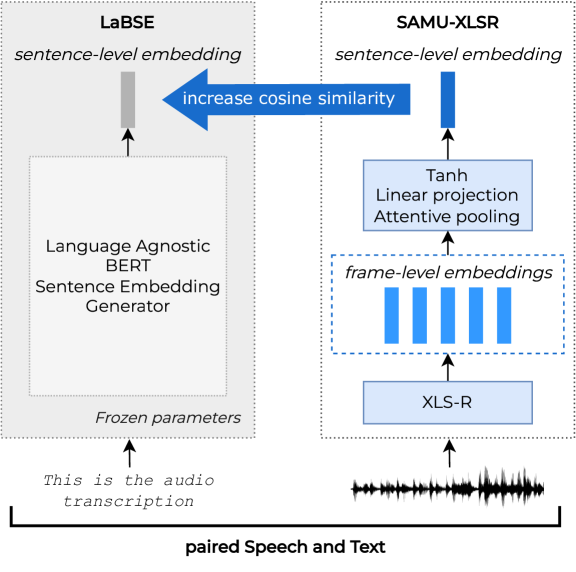
Self-Supervised Learning is vastly used to efficiently represent speech for Spoken Language Understanding, gradually replacing conventional approaches. Meanwhile, textual SSL models are proposed to encode language-agnostic semantics. SAMU-XLSR framework employed this semantic information to enrich multilingual speech representations. A recent study investigated SAMU-XLSR in-domain semantic enrichment by specializing it on downstream transcriptions, leading to state-of-the-art results on a challenging SLU task. This study's interest lies in the loss of multilingual performances and lack of specific-semantics training induced by such specialization in close languages without any SLU implication. We also consider SAMU-XLSR's loss of initial cross-lingual abilities due to a separate SLU fine-tuning. Therefore, this paper proposes a dual task learning approach to improve SAMU-XLSR semantic enrichment while considering distant languages for multilingual and language portability experiments.
6/19/2024