MLAAN: Scaling Supervised Local Learning with Multilaminar Leap Augmented Auxiliary Network

0
👨🏫
Sign in to get full access
Overview
- This paper presents a novel deep learning architecture called GLCAN (Global-Local Collaborative Auxiliary Network) for improving image classification performance.
- It proposes a collaborative learning approach that combines global and local features to overcome the limitations of traditional global or local-based methods.
- The paper also introduces an end-to-end solution to counter mainstream bias in image datasets, as well as a cooperative meta-learning algorithm for efficient neural architecture search.
Plain English Explanation
The provided paper focuses on improving image classification, which is the task of identifying what an image depicts. Traditional approaches often rely on either global features (the overall image) or local features (specific details), but the researchers behind this work believed that combining the two could lead to better performance.
Their GLCAN model uses a collaborative learning strategy, where the network learns to leverage both global and local information to make more accurate predictions. This helps overcome the limitations of using only global or local features in isolation.
Additionally, the paper proposes an end-to-end solution to address the problem of mainstream bias in image datasets, where certain groups or categories may be underrepresented. This is an important issue, as image AI systems can inadvertently discriminate if the training data is not diverse enough.
The researchers also introduce a cooperative meta-learning algorithm that can efficiently search for the best neural network architecture for a given task, without requiring extensive manual tuning.
Technical Explanation
The GLCAN model consists of a global feature extractor and a local feature extractor, which work together to learn complementary representations. These features are then combined and passed through a collaborative classifier to make the final predictions.
The end-to-end solution for addressing mainstream bias involves training the model with a novel loss function that encourages it to learn more balanced representations, reducing the impact of biases in the training data.
The cooperative meta-learning algorithm uses a gradient-based approach to efficiently search for the optimal neural architecture, without the need for time-consuming trial-and-error procedures.
The researchers evaluated their methods on several image classification benchmarks and found that they outperformed state-of-the-art approaches, demonstrating the effectiveness of their collaborative and bias-reducing techniques.
Critical Analysis
The paper presents a well-designed set of experiments to validate the performance of the proposed methods. However, the researchers acknowledge that the GLCAN model may have difficulty capturing long-range dependencies in complex images, and suggest further investigation into this area.
Additionally, the end-to-end solution for countering mainstream bias relies on the availability of demographic information about the image subjects, which may not always be present or easily obtainable in real-world datasets.
The cooperative meta-learning algorithm is an intriguing approach, but its performance may be sensitive to the choice of hyperparameters and the specific task at hand. Further empirical studies would be necessary to fully understand its broader applicability.
Overall, the paper makes valuable contributions to the field of image classification, with a focus on improving model performance, addressing dataset bias, and optimizing neural architectures. However, as with any research, there are opportunities for further refinement and exploration of the proposed techniques.
Conclusion
This paper presents a suite of innovative deep learning methods that tackle important challenges in image classification. The GLCAN model demonstrates the benefits of combining global and local features, the end-to-end bias correction approach helps reduce the impact of dataset imbalances, and the cooperative meta-learning algorithm streamlines the process of finding optimal network architectures.
These advancements have the potential to significantly improve the performance, fairness, and efficiency of image AI systems, ultimately leading to more accurate and inclusive computer vision applications. As the field of deep learning continues to evolve, research like this will play a crucial role in driving progress and addressing real-world challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👨🏫
0
MLAAN: Scaling Supervised Local Learning with Multilaminar Leap Augmented Auxiliary Network
Yuming Zhang, Shouxin Zhang, Peizhe Wang, Feiyu Zhu, Dongzhi Guan, Junhao Su, Jiabin Liu, Changpeng Cai
Deep neural networks (DNNs) typically employ an end-to-end (E2E) training paradigm which presents several challenges, including high GPU memory consumption, inefficiency, and difficulties in model parallelization during training. Recent research has sought to address these issues, with one promising approach being local learning. This method involves partitioning the backbone network into gradient-isolated modules and manually designing auxiliary networks to train these local modules. Existing methods often neglect the interaction of information between local modules, leading to myopic issues and a performance gap compared to E2E training. To address these limitations, we propose the Multilaminar Leap Augmented Auxiliary Network (MLAAN). Specifically, MLAAN comprises Multilaminar Local Modules (MLM) and Leap Augmented Modules (LAM). MLM captures both local and global features through independent and cascaded auxiliary networks, alleviating performance issues caused by insufficient global features. However, overly simplistic auxiliary networks can impede MLM's ability to capture global information. To address this, we further design LAM, an enhanced auxiliary network that uses the Exponential Moving Average (EMA) method to facilitate information exchange between local modules, thereby mitigating the shortsightedness resulting from inadequate interaction. The synergy between MLM and LAM has demonstrated excellent performance. Our experiments on the CIFAR-10, STL-10, SVHN, and ImageNet datasets show that MLAAN can be seamlessly integrated into existing local learning frameworks, significantly enhancing their performance and even surpassing end-to-end (E2E) training methods, while also reducing GPU memory consumption.
Read more8/16/2024

0
GLCAN: Global-Local Collaborative Auxiliary Network for Local Learning
Feiyu Zhu, Yuming Zhang, Changpeng Cai, Guinan Guo, Jiao Li, Xiuyuan Guo, Quanwei Zhang, Peizhe Wang, Chenghao He, Junhao Su
Traditional deep neural networks typically use end-to-end backpropagation, which often places a big burden on GPU memory. Another promising training method is local learning, which involves splitting the network into blocks and training them in parallel with the help of an auxiliary network. Local learning has been widely studied and applied to image classification tasks, and its performance is comparable to that of end-to-end method. However, different image tasks often rely on different feature representations, which is difficult for typical auxiliary networks to adapt to. To solve this problem, we propose the construction method of Global-Local Collaborative Auxiliary Network (GLCAN), which provides a macroscopic design approach for auxiliary networks. This is the first demonstration that local learning methods can be successfully applied to other tasks such as object detection and super-resolution. GLCAN not only saves a lot of GPU memory, but also has comparable performance to an end-to-end approach on data sets for multiple different tasks.
Read more6/4/2024
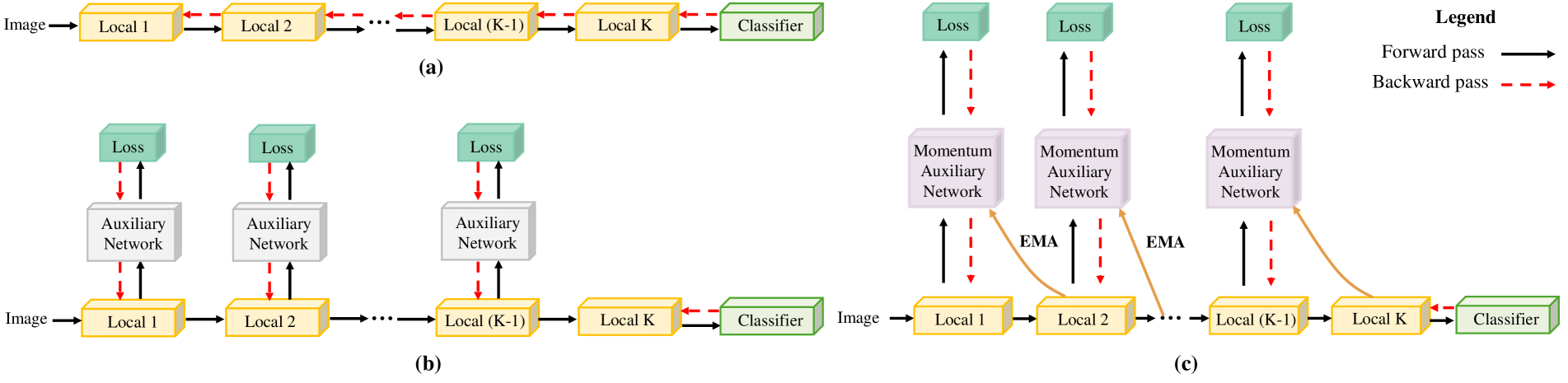
0
Momentum Auxiliary Network for Supervised Local Learning
Junhao Su, Changpeng Cai, Feiyu Zhu, Chenghao He, Xiaojie Xu, Dongzhi Guan, Chenyang Si
Deep neural networks conventionally employ end-to-end backpropagation for their training process, which lacks biological credibility and triggers a locking dilemma during network parameter updates, leading to significant GPU memory use. Supervised local learning, which segments the network into multiple local blocks updated by independent auxiliary networks. However, these methods cannot replace end-to-end training due to lower accuracy, as gradients only propagate within their local block, creating a lack of information exchange between blocks. To address this issue and establish information transfer across blocks, we propose a Momentum Auxiliary Network (MAN) that establishes a dynamic interaction mechanism. The MAN leverages an exponential moving average (EMA) of the parameters from adjacent local blocks to enhance information flow. This auxiliary network, updated through EMA, helps bridge the informational gap between blocks. Nevertheless, we observe that directly applying EMA parameters has certain limitations due to feature discrepancies among local blocks. To overcome this, we introduce learnable biases, further boosting performance. We have validated our method on four image classification datasets (CIFAR-10, STL-10, SVHN, ImageNet), attaining superior performance and substantial memory savings. Notably, our method can reduce GPU memory usage by more than 45% on the ImageNet dataset compared to end-to-end training, while achieving higher performance. The Momentum Auxiliary Network thus offers a new perspective for supervised local learning. Our code is available at: https://github.com/JunhaoSu0/MAN.
Read more8/13/2024

0
LLaMA-NAS: Efficient Neural Architecture Search for Large Language Models
Anthony Sarah, Sharath Nittur Sridhar, Maciej Szankin, Sairam Sundaresan
The abilities of modern large language models (LLMs) in solving natural language processing, complex reasoning, sentiment analysis and other tasks have been extraordinary which has prompted their extensive adoption. Unfortunately, these abilities come with very high memory and computational costs which precludes the use of LLMs on most hardware platforms. To mitigate this, we propose an effective method of finding Pareto-optimal network architectures based on LLaMA2-7B using one-shot NAS. In particular, we fine-tune LLaMA2-7B only once and then apply genetic algorithm-based search to find smaller, less computationally complex network architectures. We show that, for certain standard benchmark tasks, the pre-trained LLaMA2-7B network is unnecessarily large and complex. More specifically, we demonstrate a 1.5x reduction in model size and 1.3x speedup in throughput for certain tasks with negligible drop in accuracy. In addition to finding smaller, higher-performing network architectures, our method does so more effectively and efficiently than certain pruning or sparsification techniques. Finally, we demonstrate how quantization is complementary to our method and that the size and complexity of the networks we find can be further decreased using quantization. We believe that our work provides a way to automatically create LLMs which can be used on less expensive and more readily available hardware platforms.
Read more5/29/2024