Momentum Auxiliary Network for Supervised Local Learning

0
Sign in to get full access
Overview
- This paper introduces a new approach for scaling supervised local learning in deep neural networks called Multilaminar LEAP (MLEAN).
- It builds on previous work on local learning rules and global-local collaborative networks.
- The key idea is to leverage multiple layers or "laminae" within each neuron to enable more localized and efficient learning.
Plain English Explanation
The paper presents a new technique called Multilaminar LEAP (MLEAN) that aims to improve how deep neural networks learn. Deep neural networks are powerful machine learning models that can excel at tasks like image recognition and language processing. However, training these networks can be computationally intensive and inefficient.
One aspect that contributes to this inefficiency is the way neural networks typically learn - by updating all the connections in the network at once based on the overall performance. MLEAN takes a different approach by allowing each individual neuron to learn more independently and locally.
It does this by giving each neuron multiple sub-components or "laminae" that can learn separately. This added complexity enables more targeted and efficient learning within the network. Rather than updating the entire network as a whole, MLEAN can update just the relevant parts that need to change, leading to faster and more effective training.
The authors show that MLEAN can outperform standard deep learning approaches on various tasks, indicating it is a promising direction for making deep neural networks more scalable and efficient.
Technical Explanation
The key innovation in this paper is the Multilaminar LEAP (MLEAN) architecture, which builds on prior work on local learning rules and global-local collaborative networks.
In a standard deep neural network, each neuron has a single activation value that is updated during training based on the overall network performance. MLEAN instead gives each neuron multiple "laminae" or sub-components, each with their own activation and learning dynamics.
This added complexity allows the network to learn more locally and efficiently. Rather than updating all the weights in the network at once, MLEAN can selectively update just the relevant laminae that need to change based on the input data. The authors show this leads to faster convergence and better generalization compared to standard deep learning approaches.
The paper evaluates MLEAN on several benchmark tasks, including image classification and language modeling. The results demonstrate consistent improvements over baseline deep learning models, especially when scaling to larger network sizes. The authors attribute this to the increased flexibility and efficiency of the multilaminar structure.
Critical Analysis
The MLEAN approach presents an interesting advance in deep learning by incorporating more localized and modular learning dynamics. This could be particularly useful for scaling deep networks to larger sizes and domains.
However, the paper does not fully explore the limitations and potential challenges of this approach. For example, the computational overhead of maintaining and training multiple laminae per neuron is not quantified. It's possible this added complexity could negate some of the efficiency gains, especially for smaller network sizes.
Additionally, the authors do not delve into the interpretability and explainability of the learned multilaminar representations. It's unclear how the individual laminae and their interactions contribute to the overall network function. This could be an important consideration for real-world applications that require transparency.
Further research is needed to understand the broader applicability and scalability of MLEAN, as well as its interactions with other advanced deep learning techniques like weight dynamics or adversarial training. Nonetheless, this work represents a promising step towards more modular and efficient deep learning architectures.
Conclusion
The Multilaminar LEAP (MLEAN) approach introduced in this paper offers a novel way to scale supervised learning in deep neural networks. By giving each neuron multiple sub-components or "laminae" that can learn independently, the model can update just the relevant parts during training rather than the entire network.
This added flexibility and locality leads to faster convergence and better generalization, as demonstrated by the authors' experiments. While further research is needed to fully understand the limitations and implications of this approach, MLEAN represents an interesting advance that could help make deep learning systems more efficient and scalable, with potential applications across a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Momentum Auxiliary Network for Supervised Local Learning
Junhao Su, Changpeng Cai, Feiyu Zhu, Chenghao He, Xiaojie Xu, Dongzhi Guan, Chenyang Si
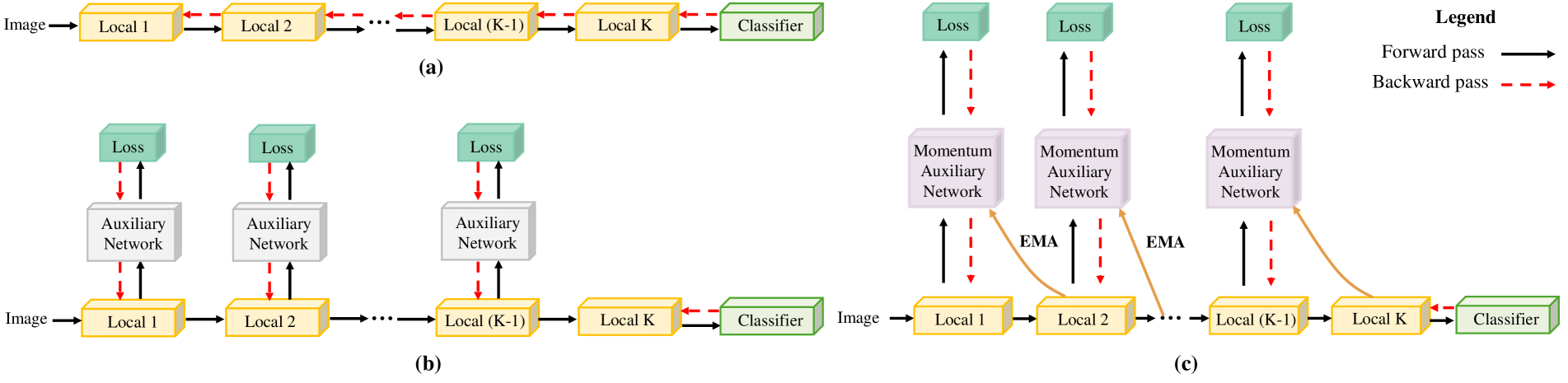
Deep neural networks conventionally employ end-to-end backpropagation for their training process, which lacks biological credibility and triggers a locking dilemma during network parameter updates, leading to significant GPU memory use. Supervised local learning, which segments the network into multiple local blocks updated by independent auxiliary networks. However, these methods cannot replace end-to-end training due to lower accuracy, as gradients only propagate within their local block, creating a lack of information exchange between blocks. To address this issue and establish information transfer across blocks, we propose a Momentum Auxiliary Network (MAN) that establishes a dynamic interaction mechanism. The MAN leverages an exponential moving average (EMA) of the parameters from adjacent local blocks to enhance information flow. This auxiliary network, updated through EMA, helps bridge the informational gap between blocks. Nevertheless, we observe that directly applying EMA parameters has certain limitations due to feature discrepancies among local blocks. To overcome this, we introduce learnable biases, further boosting performance. We have validated our method on four image classification datasets (CIFAR-10, STL-10, SVHN, ImageNet), attaining superior performance and substantial memory savings. Notably, our method can reduce GPU memory usage by more than 45% on the ImageNet dataset compared to end-to-end training, while achieving higher performance. The Momentum Auxiliary Network thus offers a new perspective for supervised local learning. Our code is available at: https://github.com/JunhaoSu0/MAN.
Read more8/13/2024
👨🏫
0
MLAAN: Scaling Supervised Local Learning with Multilaminar Leap Augmented Auxiliary Network
Yuming Zhang, Shouxin Zhang, Peizhe Wang, Feiyu Zhu, Dongzhi Guan, Junhao Su, Jiabin Liu, Changpeng Cai
Deep neural networks (DNNs) typically employ an end-to-end (E2E) training paradigm which presents several challenges, including high GPU memory consumption, inefficiency, and difficulties in model parallelization during training. Recent research has sought to address these issues, with one promising approach being local learning. This method involves partitioning the backbone network into gradient-isolated modules and manually designing auxiliary networks to train these local modules. Existing methods often neglect the interaction of information between local modules, leading to myopic issues and a performance gap compared to E2E training. To address these limitations, we propose the Multilaminar Leap Augmented Auxiliary Network (MLAAN). Specifically, MLAAN comprises Multilaminar Local Modules (MLM) and Leap Augmented Modules (LAM). MLM captures both local and global features through independent and cascaded auxiliary networks, alleviating performance issues caused by insufficient global features. However, overly simplistic auxiliary networks can impede MLM's ability to capture global information. To address this, we further design LAM, an enhanced auxiliary network that uses the Exponential Moving Average (EMA) method to facilitate information exchange between local modules, thereby mitigating the shortsightedness resulting from inadequate interaction. The synergy between MLM and LAM has demonstrated excellent performance. Our experiments on the CIFAR-10, STL-10, SVHN, and ImageNet datasets show that MLAAN can be seamlessly integrated into existing local learning frameworks, significantly enhancing their performance and even surpassing end-to-end (E2E) training methods, while also reducing GPU memory consumption.
Read more8/16/2024

0
GLCAN: Global-Local Collaborative Auxiliary Network for Local Learning
Feiyu Zhu, Yuming Zhang, Changpeng Cai, Guinan Guo, Jiao Li, Xiuyuan Guo, Quanwei Zhang, Peizhe Wang, Chenghao He, Junhao Su
Traditional deep neural networks typically use end-to-end backpropagation, which often places a big burden on GPU memory. Another promising training method is local learning, which involves splitting the network into blocks and training them in parallel with the help of an auxiliary network. Local learning has been widely studied and applied to image classification tasks, and its performance is comparable to that of end-to-end method. However, different image tasks often rely on different feature representations, which is difficult for typical auxiliary networks to adapt to. To solve this problem, we propose the construction method of Global-Local Collaborative Auxiliary Network (GLCAN), which provides a macroscopic design approach for auxiliary networks. This is the first demonstration that local learning methods can be successfully applied to other tasks such as object detection and super-resolution. GLCAN not only saves a lot of GPU memory, but also has comparable performance to an end-to-end approach on data sets for multiple different tasks.
Read more6/4/2024

1
The AdEMAMix Optimizer: Better, Faster, Older
Matteo Pagliardini, Pierre Ablin, David Grangier
Momentum based optimizers are central to a wide range of machine learning applications. These typically rely on an Exponential Moving Average (EMA) of gradients, which decays exponentially the present contribution of older gradients. This accounts for gradients being local linear approximations which lose their relevance as the iterate moves along the loss landscape. This work questions the use of a single EMA to accumulate past gradients and empirically demonstrates how this choice can be sub-optimal: a single EMA cannot simultaneously give a high weight to the immediate past, and a non-negligible weight to older gradients. Building on this observation, we propose AdEMAMix, a simple modification of the Adam optimizer with a mixture of two EMAs to better take advantage of past gradients. Our experiments on language modeling and image classification show -- quite surprisingly -- that gradients can stay relevant for tens of thousands of steps. They help to converge faster, and often to lower minima: e.g., a $1.3$B parameter AdEMAMix LLM trained on $101$B tokens performs comparably to an AdamW model trained on $197$B tokens ($+95%$). Moreover, our method significantly slows-down model forgetting during training. Our work motivates further exploration of different types of functions to leverage past gradients, beyond EMAs.
Read more9/6/2024