MLP: Motion Label Prior for Temporal Sentence Localization in Untrimmed 3D Human Motions

0

Sign in to get full access
Overview
- This paper introduces a new method called "Motion Label Prior" (MLP) for temporal sentence localization in untrimmed 3D human motion data.
- The goal is to enable systems to automatically identify the time intervals within 3D motion sequences that correspond to natural language descriptions.
- This could have applications in areas like human-robot interaction, video understanding, and generating human interactions from text.
Plain English Explanation
The paper tackles the problem of aligning natural language descriptions with specific time periods within 3D motion data of people moving around. Imagine you have a video of someone acting out different actions, and you want to be able to automatically find the parts of the video that match up with sentences like "the person is waving their arms" or "the person is jumping up and down."
The key idea behind the MLP method is to leverage the fact that certain motion labels (like "waving," "jumping," etc.) are more likely to occur during certain parts of the motion sequence. By modeling these motion priors, the system can better identify which parts of the motion data correspond to the given language descriptions. This can be particularly helpful when dealing with longer, unedited motion recordings that contain multiple actions.
The authors show that MLP outperforms previous approaches on benchmark datasets, demonstrating the potential of this technique for applications that require aligning language and 3D human motion data, such as human-robot interaction and video understanding.
Technical Explanation
The core of the MLP method is a neural network architecture that takes as input a sequence of 3D human poses and a natural language description, and outputs a temporal localization of the description within the motion sequence.
The key innovation is the Motion Label Prior (MLP) module, which learns to predict the probability distribution of motion labels (e.g., "walking," "jumping") over the course of the motion sequence. This prior distribution is then used to guide the alignment between the language and motion data, helping the model focus on the most relevant parts of the motion.
The authors evaluate MLP on two benchmark datasets for temporal sentence localization in 3D human motions. They show that MLP outperforms previous state-of-the-art methods, particularly on longer, more complex motion sequences. This demonstrates the value of modeling the temporal dynamics of human motion to improve language-motion alignment.
Critical Analysis
The paper makes a compelling case for the MLP approach, but there are a few potential limitations and areas for further research:
- The experiments are conducted on relatively constrained datasets with predefined motion labels. It would be interesting to see how well MLP generalizes to more open-ended, real-world motion data and language descriptions.
- The authors note that MLP relies on accurate 3D pose estimation, which can be challenging in practical settings. Investigating the robustness of MLP to noisy or incomplete motion data would be valuable.
- While MLP outperforms prior methods, there is still room for improvement in the overall accuracy of language-motion alignment. Exploring ways to further refine the MLP module or combine it with complementary techniques could lead to even stronger performance.
Overall, the MLP method represents an interesting advance in the field of multimodal learning for human motion and could have important applications in areas like human-robot interaction and video understanding. Further research and real-world testing will be important to fully realize the potential of this approach.
Conclusion
The MLP method introduced in this paper offers a novel way to align natural language descriptions with 3D human motion data, by leveraging the temporal dynamics of human movement. This could enable more advanced applications in areas like human-robot interaction and video understanding, where systems need to understand the connections between language and human actions.
While the current results are promising, there is room for further refinement and real-world testing of the MLP approach. Overcoming challenges like noisy motion data and expanding to more open-ended scenarios will be important next steps. Overall, this work represents an interesting contribution to the growing field of multimodal learning for human motion and its practical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MLP: Motion Label Prior for Temporal Sentence Localization in Untrimmed 3D Human Motions
Sheng Yan, Mengyuan Liu, Yong Wang, Yang Liu, Chen Chen, Hong Liu
In this paper, we address the unexplored question of temporal sentence localization in human motions (TSLM), aiming to locate a target moment from a 3D human motion that semantically corresponds to a text query. Considering that 3D human motions are captured using specialized motion capture devices, motions with only a few joints lack complex scene information like objects and lighting. Due to this character, motion data has low contextual richness and semantic ambiguity between frames, which limits the accuracy of predictions made by current video localization frameworks extended to TSLM to only a rough level. To refine this, we devise two novel label-prior-assisted training schemes: one embed prior knowledge of foreground and background to highlight the localization chances of target moments, and the other forces the originally rough predictions to overlap with the more accurate predictions obtained from the flipped start/end prior label sequences during recovery training. We show that injecting label-prior knowledge into the model is crucial for improving performance at high IoU. In our constructed TSLM benchmark, our model termed MLP achieves a recall of 44.13 at [email protected] on the BABEL dataset and 71.17 on HumanML3D (Restore), outperforming prior works. Finally, we showcase the potential of our approach in corpus-level moment retrieval. Our source code is openly accessible at https://github.com/eanson023/mlp.
Read more4/23/2024
🛸
0
T2LM: Long-Term 3D Human Motion Generation from Multiple Sentences
Taeryung Lee, Fabien Baradel, Thomas Lucas, Kyoung Mu Lee, Gregory Rogez
In this paper, we address the challenging problem of long-term 3D human motion generation. Specifically, we aim to generate a long sequence of smoothly connected actions from a stream of multiple sentences (i.e., paragraph). Previous long-term motion generating approaches were mostly based on recurrent methods, using previously generated motion chunks as input for the next step. However, this approach has two drawbacks: 1) it relies on sequential datasets, which are expensive; 2) these methods yield unrealistic gaps between motions generated at each step. To address these issues, we introduce simple yet effective T2LM, a continuous long-term generation framework that can be trained without sequential data. T2LM comprises two components: a 1D-convolutional VQVAE, trained to compress motion to sequences of latent vectors, and a Transformer-based Text Encoder that predicts a latent sequence given an input text. At inference, a sequence of sentences is translated into a continuous stream of latent vectors. This is then decoded into a motion by the VQVAE decoder; the use of 1D convolutions with a local temporal receptive field avoids temporal inconsistencies between training and generated sequences. This simple constraint on the VQ-VAE allows it to be trained with short sequences only and produces smoother transitions. T2LM outperforms prior long-term generation models while overcoming the constraint of requiring sequential data; it is also competitive with SOTA single-action generation models.
Read more6/4/2024
🔮
0
Multimodal Sense-Informed Prediction of 3D Human Motions
Zhenyu Lou, Qiongjie Cui, Haofan Wang, Xu Tang, Hong Zhou
Predicting future human pose is a fundamental application for machine intelligence, which drives robots to plan their behavior and paths ahead of time to seamlessly accomplish human-robot collaboration in real-world 3D scenarios. Despite encouraging results, existing approaches rarely consider the effects of the external scene on the motion sequence, leading to pronounced artifacts and physical implausibilities in the predictions. To address this limitation, this work introduces a novel multi-modal sense-informed motion prediction approach, which conditions high-fidelity generation on two modal information: external 3D scene, and internal human gaze, and is able to recognize their salience for future human activity. Furthermore, the gaze information is regarded as the human intention, and combined with both motion and scene features, we construct a ternary intention-aware attention to supervise the generation to match where the human wants to reach. Meanwhile, we introduce semantic coherence-aware attention to explicitly distinguish the salient point clouds and the underlying ones, to ensure a reasonable interaction of the generated sequence with the 3D scene. On two real-world benchmarks, the proposed method achieves state-of-the-art performance both in 3D human pose and trajectory prediction.
Read more5/7/2024
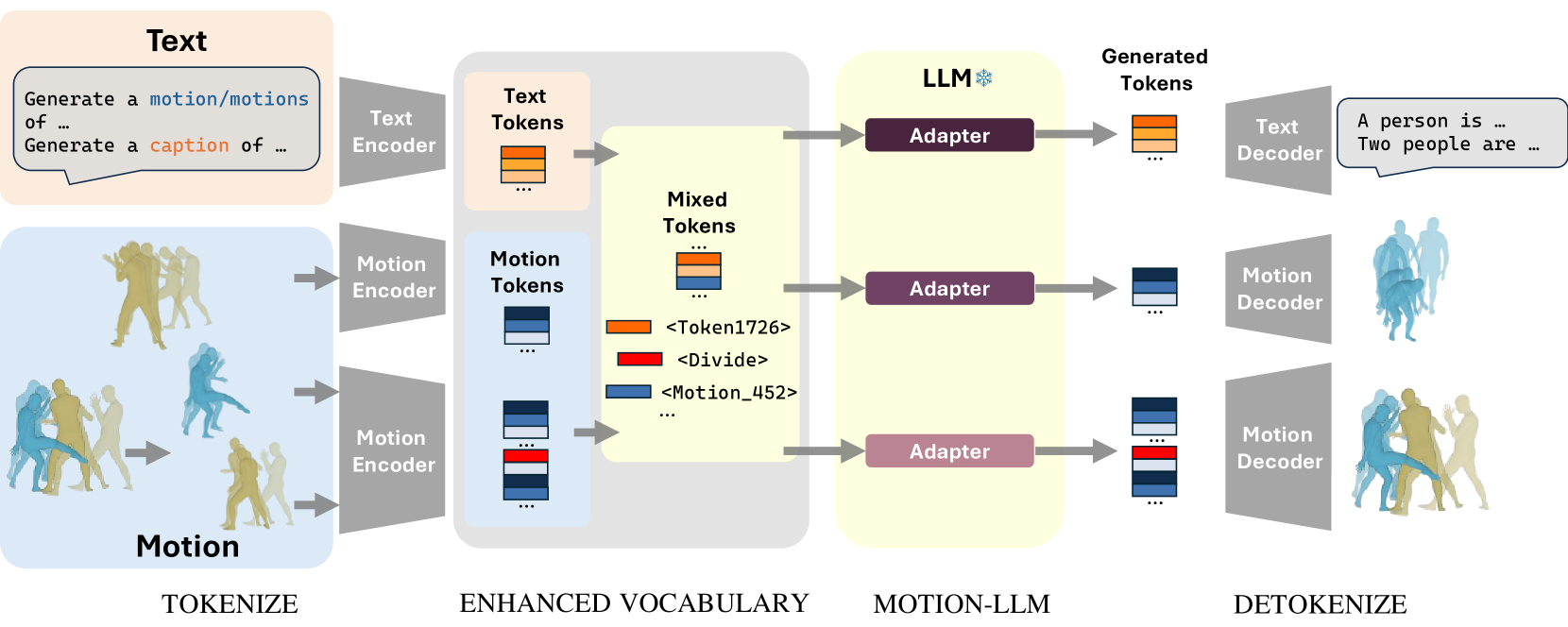
0
MotionLLM: Multimodal Motion-Language Learning with Large Language Models
Qi Wu, Yubo Zhao, Yifan Wang, Yu-Wing Tai, Chi-Keung Tang
Recent advancements in Multimodal Large Language Models (MM-LLMs) have demonstrated promising potential in terms of generalization and robustness when applied to different modalities. While previous works have already achieved 3D human motion generation using various approaches including language modeling, they mostly % are mostly carefully designed use specialized architecture and are restricted to single-human motion generation. Inspired by the success of MM-LLMs, we propose MotionLLM, a simple and general framework that can achieve single-human, multi-human motion generation, and motion captioning by fine-tuning pre-trained LLMs. Specifically, we encode and quantize motions into discrete LLM-understandable tokens, which results in a unified vocabulary consisting of both motion and text tokens. With only 1--3% parameters of the LLMs trained by using adapters, our single-human motion generation achieves comparable results to those diffusion models and other trained-from-scratch transformer-based models. Additionally, we show that our approach is scalable and flexible, allowing easy extension to multi-human motion generation through autoregressive generation of single-human motions. Project page: https://knoxzhao.github.io/MotionLLM
Read more5/29/2024