TripletMix: Triplet Data Augmentation for 3D Understanding

0

Sign in to get full access
Overview
- Introduces a novel data augmentation technique called "TripletMix" for 3D understanding tasks
- Combines three 3D point cloud samples in a unique way to create new training samples
- Shown to improve performance on various 3D perception benchmarks
Plain English Explanation
"TripletMix" is a new way to make more training data for 3D machine learning models. The key idea is to take three 3D point cloud samples (which represent real-world objects or scenes) and combine them in a special way to create a new, synthetic training sample. This helps the model learn better representations of 3D data, which can then be applied to tasks like 3D object detection or scene understanding. The authors show that this technique consistently improves performance on various 3D benchmarks, suggesting it's a valuable addition to the data-efficient 3D learning toolkit.
Technical Explanation
The core of the TripletMix approach is to combine three 3D point cloud samples in a specific way to create a new, augmented training sample. First, the three samples are randomly selected and scaled to a common size. Then, the points from the three samples are interleaved to create a single point cloud. This interleaving is done in a way that preserves the relative spatial relationships between points within each original sample.
The authors show that this technique is effective at improving performance on a variety of 3D perception tasks, including object classification, part segmentation, and scene segmentation. They attribute this to the ability of TripletMix to introduce useful variations in the training data, helping the model learn more robust and generalizable representations of 3D structures.
Critical Analysis
The authors provide a thorough evaluation of TripletMix, demonstrating its benefits across multiple benchmark datasets and tasks. However, the paper does not address certain limitations or potential issues. For example, it's unclear how TripletMix would perform on highly occluded or incomplete 3D scans, which are common in real-world scenarios. Additionally, the authors do not explore the computational overhead of the technique or its impact on training time.
Further research could investigate ways to adapt TripletMix for online data augmentation during training, rather than as a pre-processing step. This could help make the technique more scalable and efficient for larger datasets. Exploring task-specific variants of TripletMix that optimize the interleaving process for particular 3D perception problems could also be a fruitful direction.
Conclusion
The TripletMix data augmentation technique represents a promising approach for improving the performance of 3D machine learning models. By combining multiple point cloud samples in a unique way, the method introduces useful variations in the training data, leading to better learned representations. While the paper demonstrates the effectiveness of TripletMix, further research is needed to explore its limitations and potential extensions to make it more robust and practical for real-world 3D perception tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TripletMix: Triplet Data Augmentation for 3D Understanding
Jiaze Wang, Yi Wang, Ziyu Guo, Renrui Zhang, Donghao Zhou, Guangyong Chen, Anfeng Liu, Pheng-Ann Heng
We introduce MM-Mixing, a multi-modal mixing alignment framework for 3D understanding. MM-Mixing applies mixing-based methods to multi-modal data, preserving and optimizing cross-modal connections while enhancing diversity and improving alignment across modalities. Our proposed two-stage training pipeline combines feature-level and input-level mixing to optimize the 3D encoder. The first stage employs feature-level mixing with contrastive learning to align 3D features with their corresponding modalities. The second stage incorporates both feature-level and input-level mixing, introducing mixed point cloud inputs to further refine 3D feature representations. MM-Mixing enhances intermodality relationships, promotes generalization, and ensures feature consistency while providing diverse and realistic training samples. We demonstrate that MM-Mixing significantly improves baseline performance across various learning scenarios, including zero-shot 3D classification, linear probing 3D classification, and cross-modal 3D shape retrieval. Notably, we improved the zero-shot classification accuracy on ScanObjectNN from 51.3% to 61.9%, and on Objaverse-LVIS from 46.8% to 51.4%. Our findings highlight the potential of multi-modal mixing-based alignment to significantly advance 3D object recognition and understanding while remaining straightforward to implement and integrate into existing frameworks.
Read more8/20/2024

0
3D-VirtFusion: Synthetic 3D Data Augmentation through Generative Diffusion Models and Controllable Editing
Shichao Dong, Ze Yang, Guosheng Lin
Data augmentation plays a crucial role in deep learning, enhancing the generalization and robustness of learning-based models. Standard approaches involve simple transformations like rotations and flips for generating extra data. However, these augmentations are limited by their initial dataset, lacking high-level diversity. Recently, large models such as language models and diffusion models have shown exceptional capabilities in perception and content generation. In this work, we propose a new paradigm to automatically generate 3D labeled training data by harnessing the power of pretrained large foundation models. For each target semantic class, we first generate 2D images of a single object in various structure and appearance via diffusion models and chatGPT generated text prompts. Beyond texture augmentation, we propose a method to automatically alter the shape of objects within 2D images. Subsequently, we transform these augmented images into 3D objects and construct virtual scenes by random composition. This method can automatically produce a substantial amount of 3D scene data without the need of real data, providing significant benefits in addressing few-shot learning challenges and mitigating long-tailed class imbalances. By providing a flexible augmentation approach, our work contributes to enhancing 3D data diversity and advancing model capabilities in scene understanding tasks.
Read more8/27/2024
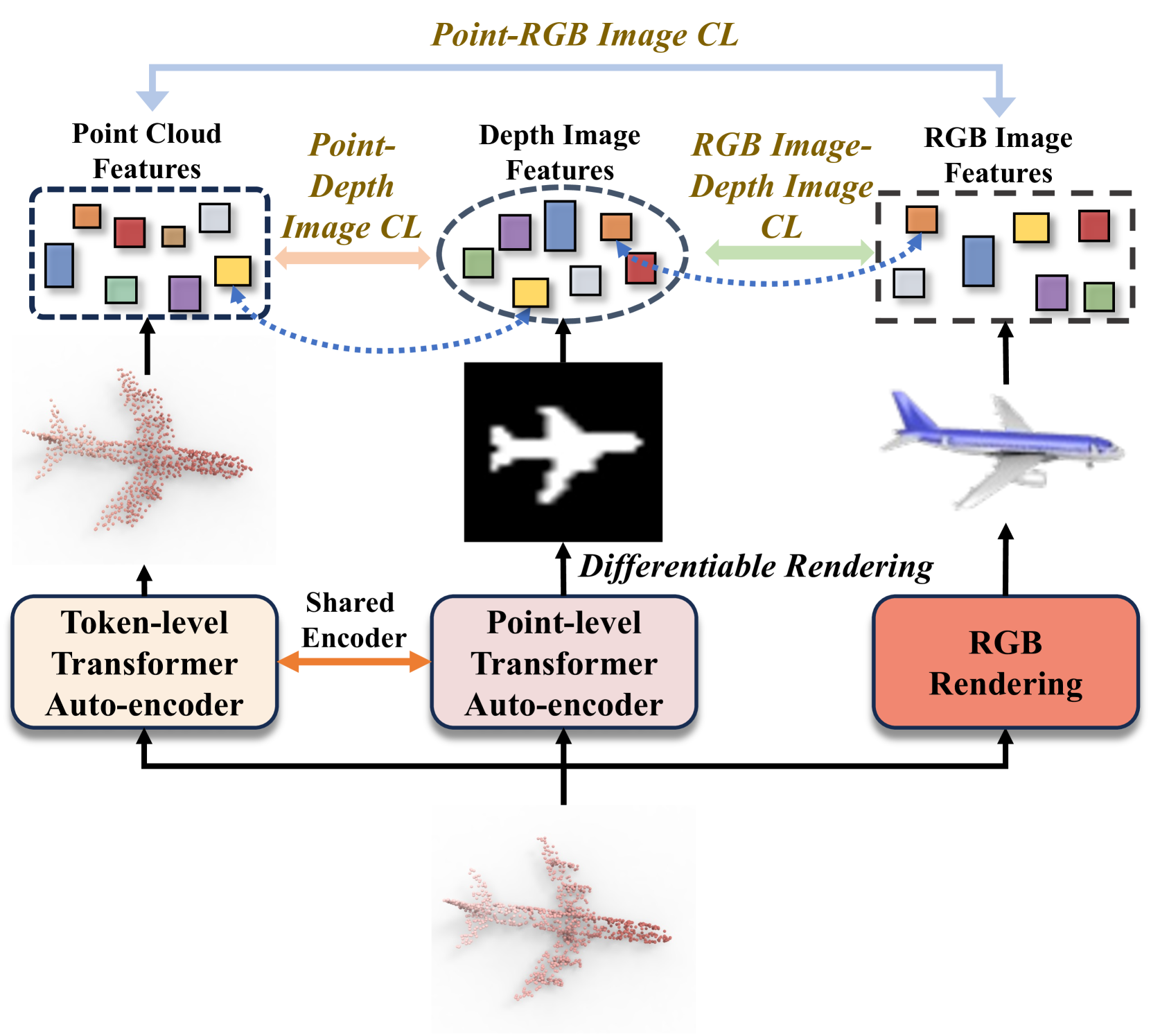
0
Towards Unified Representation of Multi-Modal Pre-training for 3D Understanding via Differentiable Rendering
Ben Fei, Yixuan Li, Weidong Yang, Lipeng Ma, Ying He
State-of-the-art 3D models, which excel in recognition tasks, typically depend on large-scale datasets and well-defined category sets. Recent advances in multi-modal pre-training have demonstrated potential in learning 3D representations by aligning features from 3D shapes with their 2D RGB or depth counterparts. However, these existing frameworks often rely solely on either RGB or depth images, limiting their effectiveness in harnessing a comprehensive range of multi-modal data for 3D applications. To tackle this challenge, we present DR-Point, a tri-modal pre-training framework that learns a unified representation of RGB images, depth images, and 3D point clouds by pre-training with object triplets garnered from each modality. To address the scarcity of such triplets, DR-Point employs differentiable rendering to obtain various depth images. This approach not only augments the supply of depth images but also enhances the accuracy of reconstructed point clouds, thereby promoting the representative learning of the Transformer backbone. Subsequently, using a limited number of synthetically generated triplets, DR-Point effectively learns a 3D representation space that aligns seamlessly with the RGB-Depth image space. Our extensive experiments demonstrate that DR-Point outperforms existing self-supervised learning methods in a wide range of downstream tasks, including 3D object classification, part segmentation, point cloud completion, semantic segmentation, and detection. Additionally, our ablation studies validate the effectiveness of DR-Point in enhancing point cloud understanding.
Read more4/23/2024
🏋️
0
Single-image driven 3d viewpoint training data augmentation for effective wine label recognition
Yueh-Cheng Huang, Hsin-Yi Chen, Cheng-Jui Hung, Jen-Hui Chuang, Jenq-Neng Hwang
Confronting the critical challenge of insufficient training data in the field of complex image recognition, this paper introduces a novel 3D viewpoint augmentation technique specifically tailored for wine label recognition. This method enhances deep learning model performance by generating visually realistic training samples from a single real-world wine label image, overcoming the challenges posed by the intricate combinations of text and logos. Classical Generative Adversarial Network (GAN) methods fall short in synthesizing such intricate content combination. Our proposed solution leverages time-tested computer vision and image processing strategies to expand our training dataset, thereby broadening the range of training samples for deep learning applications. This innovative approach to data augmentation circumvents the constraints of limited training resources. Using the augmented training images through batch-all triplet metric learning on a Vision Transformer (ViT) architecture, we can get the most discriminative embedding features for every wine label, enabling us to perform one-shot recognition of existing wine labels in the training classes or future newly collected wine labels unavailable in the training. Experimental results show a significant increase in recognition accuracy over conventional 2D data augmentation techniques.
Read more4/16/2024