MM-Soc: Benchmarking Multimodal Large Language Models in Social Media Platforms

0

Sign in to get full access
Overview
- Introduces the MM-Soc benchmark for evaluating multimodal large language models on social media platforms
- Examines the performance of various models on tasks like content generation, multimodal understanding, and social media interaction
- Provides insights into the strengths and limitations of current multimodal models in real-world social media settings
Plain English Explanation
The paper presents the MM-Soc benchmark, which is designed to evaluate how well multimodal large language models perform on tasks related to social media platforms. These models are trained on a wide range of data, including text, images, and other modalities, and are intended to have broad capabilities in understanding and generating content.
The researchers wanted to see how these advanced models would handle the unique challenges of social media, such as dealing with short, informal text, diverse content, and complex user interactions. They tested the models on tasks like content generation, multimodal understanding, and social media interaction, to get a comprehensive view of their strengths and limitations in real-world social media settings.
By benchmarking the models on this specialized dataset, the paper provides insights into the current state of multimodal language AI and identifies areas where further research and development may be needed to make these models truly effective for social media applications.
Technical Explanation
The MM-Soc benchmark is designed to evaluate the performance of multimodal large language models on social media-related tasks. It includes a diverse dataset of content from various social media platforms, covering text, images, and other modalities.
The benchmark assesses the models' capabilities in three main areas:
-
Content Generation: The models are tested on their ability to generate relevant and coherent text, images, and multimodal content in response to social media prompts.
-
Multimodal Understanding: The models are evaluated on their ability to understand and reason about the relationships between text, images, and other modalities in social media posts.
-
Social Media Interaction: The models are assessed on their ability to engage in realistic social media interactions, such as responding appropriately to comments, generating relevant hashtags, and understanding social context.
The paper compares the performance of several state-of-the-art multimodal large language models on the MM-Soc benchmark, providing insights into the strengths and limitations of these models in social media settings.
Critical Analysis
The paper acknowledges several caveats and limitations of the MM-Soc benchmark and the evaluation of multimodal large language models in social media settings:
- The dataset, while diverse, may not capture the full breadth and complexity of real-world social media content and interactions.
- The evaluation tasks, while designed to be representative, may not fully capture all the nuances and challenges of social media platforms.
- The performance of the models may be influenced by biases and limitations in the training data and model architectures, which are not fully addressed in the paper.
Additionally, the paper does not delve into potential ethical concerns or societal implications of using these models in social media applications, such as the risk of amplifying misinformation, generating harmful content, or infringing on user privacy.
Further research and critical analysis are needed to more thoroughly understand the capabilities and limitations of multimodal large language models in social media contexts, and to ensure that their development and deployment are aligned with ethical principles and societal well-being.
Conclusion
The MM-Soc benchmark provides a valuable framework for evaluating the performance of multimodal large language models in social media settings. The paper's findings suggest that while these models have made significant progress in understanding and generating multimodal content, they still face challenges in effectively navigating the unique dynamics and complexities of social media platforms.
The insights gained from this benchmark can inform the continued development and refinement of multimodal language AI, ultimately leading to more capable and responsible systems that can better support and enrich social media interactions. As these technologies continue to evolve, it will be crucial to consider their broader societal implications and ensure they are deployed in a manner that prioritizes ethical principles and the well-being of users and communities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MM-Soc: Benchmarking Multimodal Large Language Models in Social Media Platforms
Yiqiao Jin, Minje Choi, Gaurav Verma, Jindong Wang, Srijan Kumar
Social media platforms are hubs for multimodal information exchange, encompassing text, images, and videos, making it challenging for machines to comprehend the information or emotions associated with interactions in online spaces. Multimodal Large Language Models (MLLMs) have emerged as a promising solution to these challenges, yet they struggle to accurately interpret human emotions and complex content such as misinformation. This paper introduces MM-Soc, a comprehensive benchmark designed to evaluate MLLMs' understanding of multimodal social media content. MM-Soc compiles prominent multimodal datasets and incorporates a novel large-scale YouTube tagging dataset, targeting a range of tasks from misinformation detection, hate speech detection, and social context generation. Through our exhaustive evaluation on ten size-variants of four open-source MLLMs, we have identified significant performance disparities, highlighting the need for advancements in models' social understanding capabilities. Our analysis reveals that, in a zero-shot setting, various types of MLLMs generally exhibit difficulties in handling social media tasks. However, MLLMs demonstrate performance improvements post fine-tuning, suggesting potential pathways for improvement. Our code and data are available at https://github.com/claws-lab/MMSoc.git.
Read more9/4/2024

0
A Survey on Benchmarks of Multimodal Large Language Models
Jian Li, Weiheng Lu, Hao Fei, Meng Luo, Ming Dai, Min Xia, Yizhang Jin, Zhenye Gan, Ding Qi, Chaoyou Fu, Ying Tai, Wankou Yang, Yabiao Wang, Chengjie Wang
Multimodal Large Language Models (MLLMs) are gaining increasing popularity in both academia and industry due to their remarkable performance in various applications such as visual question answering, visual perception, understanding, and reasoning. Over the past few years, significant efforts have been made to examine MLLMs from multiple perspectives. This paper presents a comprehensive review of 200 benchmarks and evaluations for MLLMs, focusing on (1)perception and understanding, (2)cognition and reasoning, (3)specific domains, (4)key capabilities, and (5)other modalities. Finally, we discuss the limitations of the current evaluation methods for MLLMs and explore promising future directions. Our key argument is that evaluation should be regarded as a crucial discipline to support the development of MLLMs better. For more details, please visit our GitHub repository: https://github.com/swordlidev/Evaluation-Multimodal-LLMs-Survey.
Read more9/9/2024
0
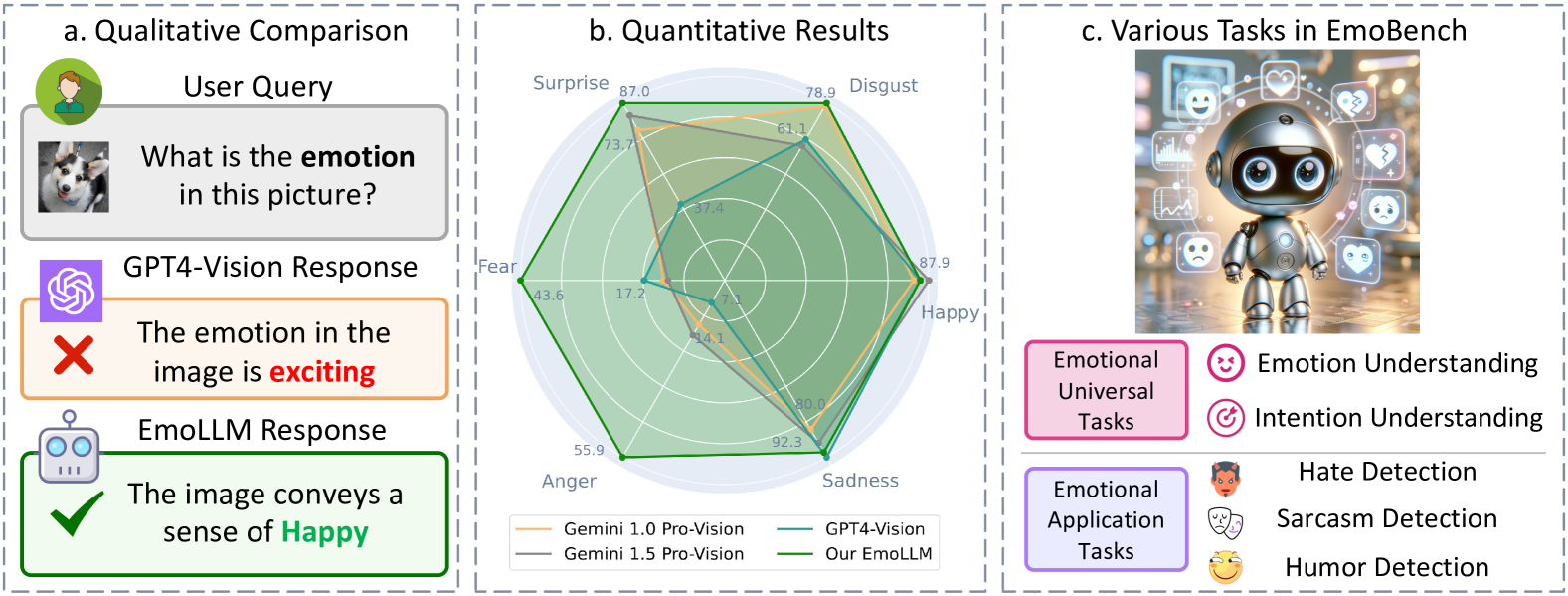
EmoLLM: Multimodal Emotional Understanding Meets Large Language Models
Qu Yang, Mang Ye, Bo Du
Multi-modal large language models (MLLMs) have achieved remarkable performance on objective multimodal perception tasks, but their ability to interpret subjective, emotionally nuanced multimodal content remains largely unexplored. Thus, it impedes their ability to effectively understand and react to the intricate emotions expressed by humans through multimodal media. To bridge this gap, we introduce EmoBench, the first comprehensive benchmark designed specifically to evaluate the emotional capabilities of MLLMs across five popular emotional tasks, using a diverse dataset of 287k images and videos paired with corresponding textual instructions. Meanwhile, we propose EmoLLM, a novel model for multimodal emotional understanding, incorporating with two core techniques. 1) Multi-perspective Visual Projection, it captures diverse emotional cues from visual data from multiple perspectives. 2) EmoPrompt, it guides MLLMs to reason about emotions in the correct direction. Experimental results demonstrate that EmoLLM significantly elevates multimodal emotional understanding performance, with an average improvement of 12.1% across multiple foundation models on EmoBench. Our work contributes to the advancement of MLLMs by facilitating a deeper and more nuanced comprehension of intricate human emotions, paving the way for the development of artificial emotional intelligence capabilities with wide-ranging applications in areas such as human-computer interaction, mental health support, and empathetic AI systems. Code, data, and model will be released.
Read more7/2/2024
0
MultiSocial: Multilingual Benchmark of Machine-Generated Text Detection of Social-Media Texts
Dominik Macko, Jakub Kopal, Robert Moro, Ivan Srba
Recent LLMs are able to generate high-quality multilingual texts, indistinguishable for humans from authentic human-written ones. Research in machine-generated text detection is however mostly focused on the English language and longer texts, such as news articles, scientific papers or student essays. Social-media texts are usually much shorter and often feature informal language, grammatical errors, or distinct linguistic items (e.g., emoticons, hashtags). There is a gap in studying the ability of existing methods in detection of such texts, reflected also in the lack of existing multilingual benchmark datasets. To fill this gap we propose the first multilingual (22 languages) and multi-platform (5 social media platforms) dataset for benchmarking machine-generated text detection in the social-media domain, called MultiSocial. It contains 472,097 texts, of which about 58k are human-written and approximately the same amount is generated by each of 7 multilingual LLMs. We use this benchmark to compare existing detection methods in zero-shot as well as fine-tuned form. Our results indicate that the fine-tuned detectors have no problem to be trained on social-media texts and that the platform selection for training matters.
Read more6/19/2024