A Survey on Benchmarks of Multimodal Large Language Models

0

Sign in to get full access
Overview
- This paper provides a comprehensive survey of benchmarks used to evaluate multimodal large language models (MM-LLMs).
- MM-LLMs are AI models that can process and generate text, images, and other modalities simultaneously.
- The survey covers a wide range of benchmarks across different tasks and datasets, including vision-language, audio-language, and multimodal reasoning.
- The authors analyze the strengths and limitations of these benchmarks and discuss future research directions.
Plain English Explanation
The paper explores the various ways researchers measure the performance of large AI models that can handle different types of data, like text, images, and audio. These "multimodal large language models" are powerful tools that can understand and generate content across multiple mediums.
The survey looks at a wide range of benchmarks - standardized tests and datasets - that researchers use to evaluate how well these models perform on different tasks. This includes tests for skills like interpreting images and describing them in words, answering questions that require combining information from text and visuals, and understanding the meaning behind audio clips and text.
By analyzing these benchmarks, the authors identify the strengths and limitations of the current approaches. This provides guidance on the best ways to measure the capabilities of these powerful AI models, and points to areas where more research is needed to further advance multimodal modeling.
Technical Explanation
The paper begins by providing an overview of multimodal large language models (MM-LLMs) - AI systems that can process and generate content across multiple modalities such as text, images, and audio. The authors then survey a wide range of benchmarks used to evaluate the performance of these models.
The benchmarks covered span diverse tasks, including:
- Vision-language: Evaluating a model's ability to interpret images and describe them in natural language.
- Audio-language: Assessing a model's understanding of the relationship between audio clips and corresponding text.
- Multimodal reasoning: Testing a model's capacity to combine information from different modalities to answer complex questions.
For each benchmark, the authors provide details on the dataset, evaluation metrics, and key findings from the literature. They also analyze the strengths and limitations of the different benchmarking approaches.
The paper concludes by discussing future research directions for improving multimodal benchmarks and advancing the field of MM-LLM development.
Critical Analysis
The survey provides a comprehensive overview of the current state of multimodal benchmarking, highlighting the breadth of tasks and datasets being used to evaluate MM-LLMs. However, the authors acknowledge that many of these benchmarks have important limitations.
For example, some datasets may exhibit biases or lack diversity, which could lead to models performing well on the benchmarks but failing to generalize to real-world scenarios. The authors also note that the field lacks standardized evaluation protocols, making it difficult to compare the performance of different models.
Additionally, the paper does not delve deeply into the ethical implications of multimodal modeling, such as the potential for these models to be used for misinformation or biased decision-making. Further research is needed to address these important concerns.
Conclusion
This survey offers a valuable resource for researchers and practitioners working on multimodal large language models. By cataloging the various benchmarks and their strengths and weaknesses, the paper provides guidance on the best ways to assess the capabilities of these powerful AI systems.
The insights from this work can inform the development of more robust and comprehensive benchmarks, ultimately driving the field of multimodal modeling forward. However, the authors also highlight the need for continued research to address the remaining challenges and ethical considerations in this rapidly evolving area of AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Survey on Benchmarks of Multimodal Large Language Models
Jian Li, Weiheng Lu, Hao Fei, Meng Luo, Ming Dai, Min Xia, Yizhang Jin, Zhenye Gan, Ding Qi, Chaoyou Fu, Ying Tai, Wankou Yang, Yabiao Wang, Chengjie Wang
Multimodal Large Language Models (MLLMs) are gaining increasing popularity in both academia and industry due to their remarkable performance in various applications such as visual question answering, visual perception, understanding, and reasoning. Over the past few years, significant efforts have been made to examine MLLMs from multiple perspectives. This paper presents a comprehensive review of 200 benchmarks and evaluations for MLLMs, focusing on (1)perception and understanding, (2)cognition and reasoning, (3)specific domains, (4)key capabilities, and (5)other modalities. Finally, we discuss the limitations of the current evaluation methods for MLLMs and explore promising future directions. Our key argument is that evaluation should be regarded as a crucial discipline to support the development of MLLMs better. For more details, please visit our GitHub repository: https://github.com/swordlidev/Evaluation-Multimodal-LLMs-Survey.
Read more9/9/2024
0
A Survey on Evaluation of Multimodal Large Language Models
Jiaxing Huang, Jingyi Zhang
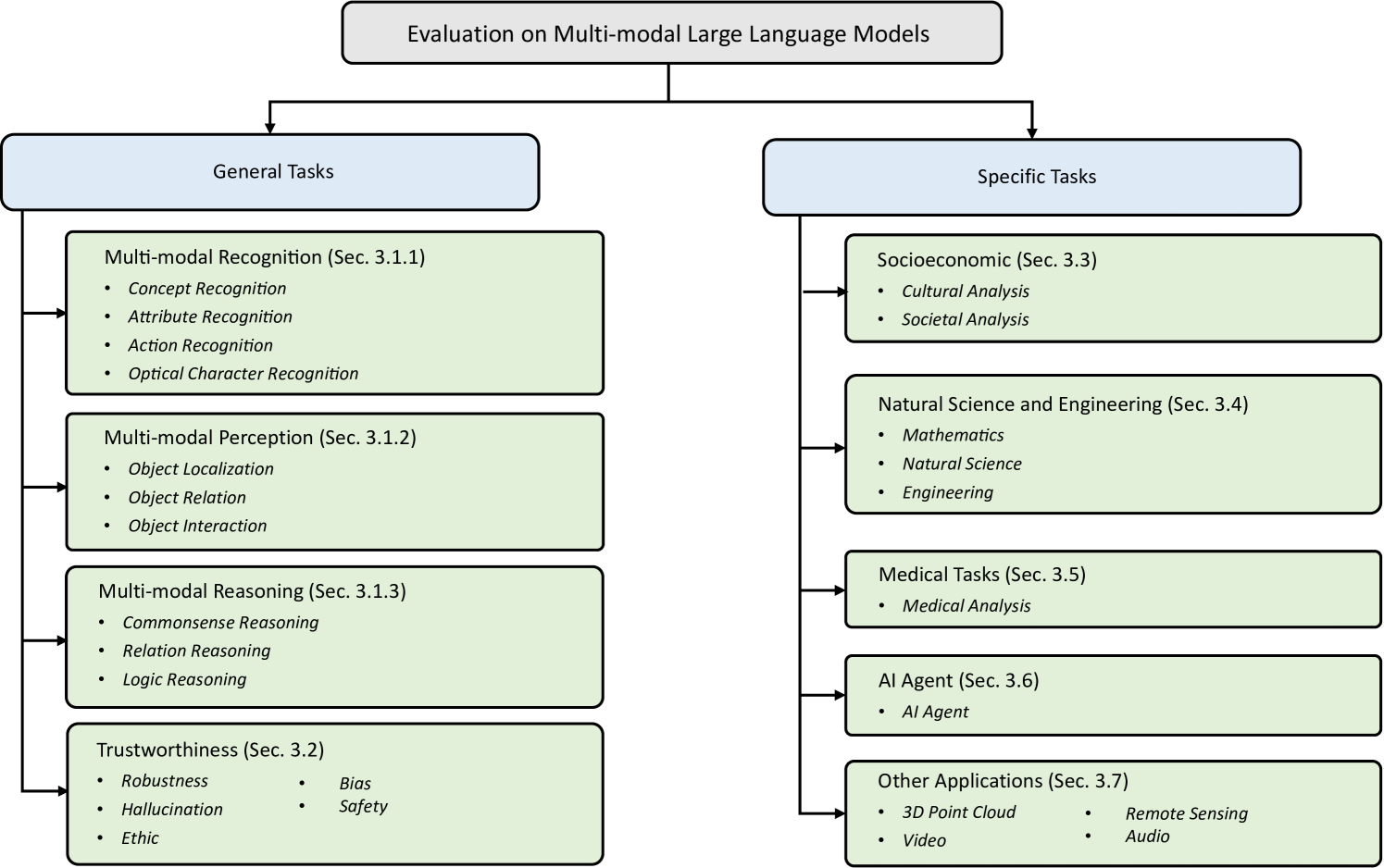
Multimodal Large Language Models (MLLMs) mimic human perception and reasoning system by integrating powerful Large Language Models (LLMs) with various modality encoders (e.g., vision, audio), positioning LLMs as the brain and various modality encoders as sensory organs. This framework endows MLLMs with human-like capabilities, and suggests a potential pathway towards achieving artificial general intelligence (AGI). With the emergence of all-round MLLMs like GPT-4V and Gemini, a multitude of evaluation methods have been developed to assess their capabilities across different dimensions. This paper presents a systematic and comprehensive review of MLLM evaluation methods, covering the following key aspects: (1) the background of MLLMs and their evaluation; (2) what to evaluate that reviews and categorizes existing MLLM evaluation tasks based on the capabilities assessed, including general multimodal recognition, perception, reasoning and trustworthiness, and domain-specific applications such as socioeconomic, natural sciences and engineering, medical usage, AI agent, remote sensing, video and audio processing, 3D point cloud analysis, and others; (3) where to evaluate that summarizes MLLM evaluation benchmarks into general and specific benchmarks; (4) how to evaluate that reviews and illustrates MLLM evaluation steps and metrics; Our overarching goal is to provide valuable insights for researchers in the field of MLLM evaluation, thereby facilitating the development of more capable and reliable MLLMs. We emphasize that evaluation should be regarded as a critical discipline, essential for advancing the field of MLLMs.
Read more8/29/2024
0
Efficient Multimodal Large Language Models: A Survey
Yizhang Jin, Jian Li, Yexin Liu, Tianjun Gu, Kai Wu, Zhengkai Jiang, Muyang He, Bo Zhao, Xin Tan, Zhenye Gan, Yabiao Wang, Chengjie Wang, Lizhuang Ma
In the past year, Multimodal Large Language Models (MLLMs) have demonstrated remarkable performance in tasks such as visual question answering, visual understanding and reasoning. However, the extensive model size and high training and inference costs have hindered the widespread application of MLLMs in academia and industry. Thus, studying efficient and lightweight MLLMs has enormous potential, especially in edge computing scenarios. In this survey, we provide a comprehensive and systematic review of the current state of efficient MLLMs. Specifically, we summarize the timeline of representative efficient MLLMs, research state of efficient structures and strategies, and the applications. Finally, we discuss the limitations of current efficient MLLM research and promising future directions. Please refer to our GitHub repository for more details: https://github.com/lijiannuist/Efficient-Multimodal-LLMs-Survey.
Read more8/12/2024

0
The Revolution of Multimodal Large Language Models: A Survey
Davide Caffagni, Federico Cocchi, Luca Barsellotti, Nicholas Moratelli, Sara Sarto, Lorenzo Baraldi, Lorenzo Baraldi, Marcella Cornia, Rita Cucchiara
Connecting text and visual modalities plays an essential role in generative intelligence. For this reason, inspired by the success of large language models, significant research efforts are being devoted to the development of Multimodal Large Language Models (MLLMs). These models can seamlessly integrate visual and textual modalities, while providing a dialogue-based interface and instruction-following capabilities. In this paper, we provide a comprehensive review of recent visual-based MLLMs, analyzing their architectural choices, multimodal alignment strategies, and training techniques. We also conduct a detailed analysis of these models across a wide range of tasks, including visual grounding, image generation and editing, visual understanding, and domain-specific applications. Additionally, we compile and describe training datasets and evaluation benchmarks, conducting comparisons among existing models in terms of performance and computational requirements. Overall, this survey offers a comprehensive overview of the current state of the art, laying the groundwork for future MLLMs.
Read more6/7/2024