MMAD: Multi-label Micro-Action Detection in Videos

0

Sign in to get full access
Overview
- Introduces a new multi-label micro-action detection dataset (MMA-52) and a corresponding model for video understanding
- Focuses on detecting fine-grained, short-duration actions in videos, which has applications in areas like human-computer interaction and healthcare monitoring
- Proposes a novel model architecture that can jointly detect and classify multiple micro-actions in a video
Plain English Explanation
The research paper presents a new dataset and model for understanding the fine details of human actions in videos. Rather than looking at broad, high-level actions (like "walking" or "waving"), the focus is on detecting very short, granular movements (like "tapping finger" or "scratching head"). This level of detail has potential applications in areas like monitoring patient movements for healthcare or enabling more natural interactions between humans and computers.
The new dataset, called MMA-52, contains videos labeled with 52 different micro-actions that people perform in everyday life. The researchers then developed a machine learning model that can simultaneously detect and classify multiple micro-actions occurring in a single video. This allows the model to understand the complex, overlapping movements that make up natural human behavior.
Overall, this work aims to advance the state-of-the-art in video understanding by shifting the focus to the micro-level of human actions, which could unlock new applications for AI technologies. By providing a benchmark dataset and a novel model architecture, the researchers are laying the groundwork for further developments in this area of computer vision.
Technical Explanation
The paper introduces the MMA-52 dataset, which contains 10,400 videos of 52 different micro-actions performed by 52 different people. Each video is labeled with one or more of the 52 micro-action classes, reflecting the fact that people often perform multiple subtle movements at the same time.
To address this multi-label micro-action detection task, the researchers propose a new model architecture called MMAD. It consists of a feature extraction backbone (built on top of a vision transformer), followed by a set of per-class prediction heads that output the presence or absence of each micro-action. This allows the model to jointly detect and classify the various micro-actions occurring in a single video.
The MMAD model is trained and evaluated on the MMA-52 dataset, demonstrating strong performance compared to prior work on micro-action recognition [1, 2]. The authors also show that their model can be effectively combined with language models for more holistic video understanding and used for temporal action detection.
Critical Analysis
The paper makes a compelling case for the importance of micro-action detection and the need for specialized datasets and models to address this challenge. The MMA-52 dataset appears to be a valuable contribution to the field, providing a benchmark for evaluating micro-action recognition systems.
However, the authors acknowledge some limitations of the dataset, such as the relatively small number of videos per class and the potential for bias in the selection of participants and actions. Additionally, the paper does not provide much insight into the real-world applications and practical implications of micro-action detection, which could be an area for further exploration.
From a technical perspective, the MMAD model architecture seems well-designed for the task at hand, but the authors could have provided more details on the training process, hyperparameter tuning, and any ablation studies performed to understand the contribution of different components. Moreover, it would be interesting to see how the MMAD model compares to more holistic approaches to video understanding that aim to capture both the semantic and temporal aspects of human behavior.
Overall, the paper represents an important step forward in the field of video understanding, and the dataset and model proposed could serve as a valuable resource for future research in micro-action learning and detection.
Conclusion
This research paper introduces a new multi-label micro-action detection dataset (MMA-52) and a corresponding model (MMAD) that can jointly detect and classify multiple fine-grained human actions in video. By shifting the focus to the micro-level of human movements, the work has the potential to enable new applications in areas like healthcare monitoring, human-computer interaction, and video analysis. While the paper has some limitations, it represents an important contribution to the field of video understanding and lays the groundwork for further advancements in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MMAD: Multi-label Micro-Action Detection in Videos
Kun Li, Dan Guo, Pengyu Liu, Guoliang Chen, Meng Wang
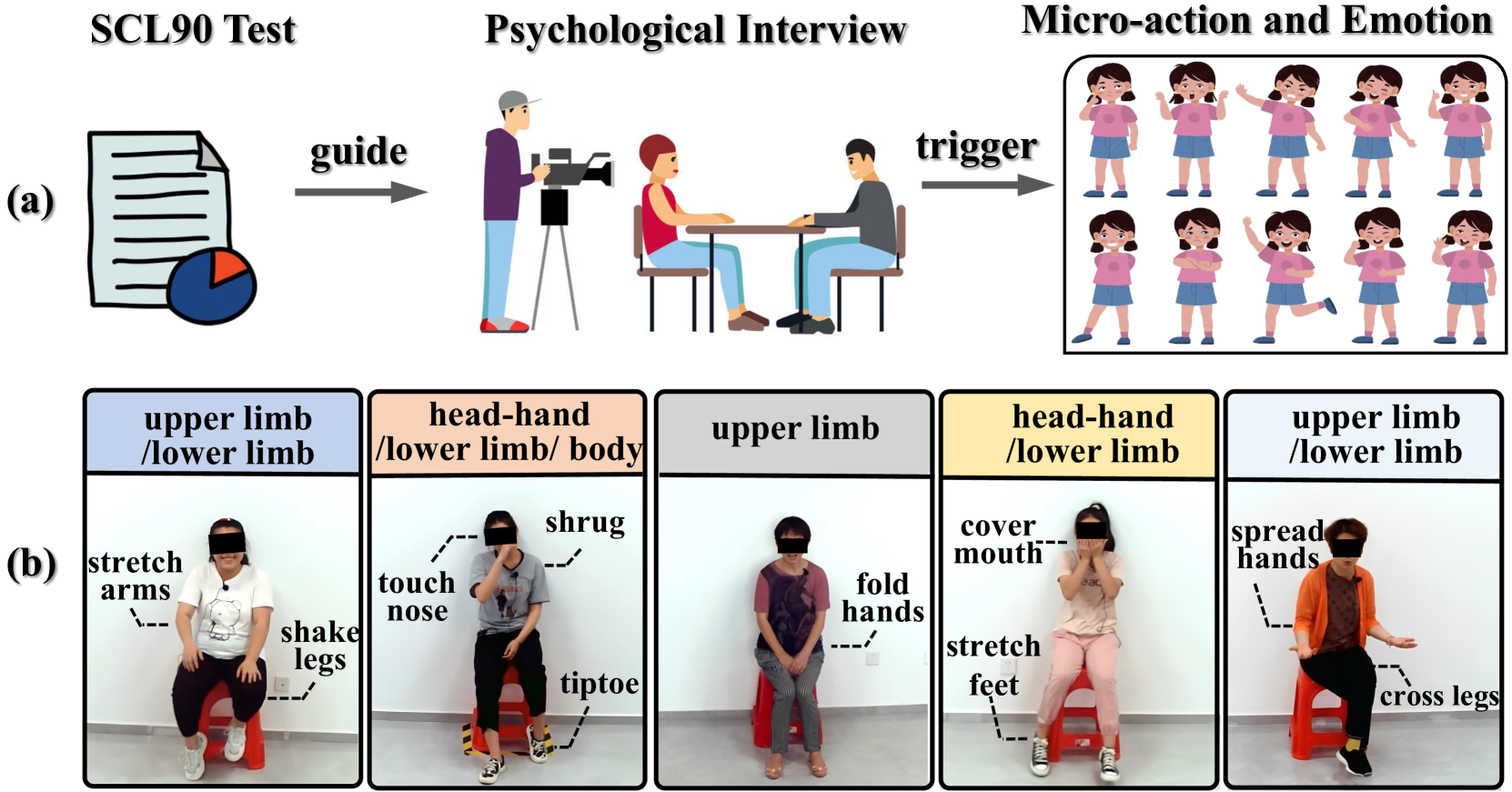
Human body actions are an important form of non-verbal communication in social interactions. This paper focuses on a specific subset of body actions known as micro-actions, which are subtle, low-intensity body movements that provide a deeper understanding of inner human feelings. In real-world scenarios, human micro-actions often co-occur, with multiple micro-actions overlapping in time, such as simultaneous head and hand movements. However, current research primarily focuses on recognizing individual micro-actions while overlooking their co-occurring nature. To narrow this gap, we propose a new task named Multi-label Micro-Action Detection (MMAD), which involves identifying all micro-actions in a given short video, determining their start and end times, and categorizing them. Achieving this requires a model capable of accurately capturing both long-term and short-term action relationships to locate and classify multiple micro-actions. To support the MMAD task, we introduce a new dataset named Multi-label Micro-Action-52 (MMA-52), specifically designed to facilitate the detailed analysis and exploration of complex human micro-actions. The proposed MMA-52 dataset is available at: https://github.com/VUT-HFUT/Micro-Action.
Read more7/9/2024
0
Benchmarking Micro-action Recognition: Dataset, Methods, and Applications
Dan Guo, Kun Li, Bin Hu, Yan Zhang, Meng Wang
Micro-action is an imperceptible non-verbal behaviour characterised by low-intensity movement. It offers insights into the feelings and intentions of individuals and is important for human-oriented applications such as emotion recognition and psychological assessment. However, the identification, differentiation, and understanding of micro-actions pose challenges due to the imperceptible and inaccessible nature of these subtle human behaviors in everyday life. In this study, we innovatively collect a new micro-action dataset designated as Micro-action-52 (MA-52), and propose a benchmark named micro-action network (MANet) for micro-action recognition (MAR) task. Uniquely, MA-52 provides the whole-body perspective including gestures, upper- and lower-limb movements, attempting to reveal comprehensive micro-action cues. In detail, MA-52 contains 52 micro-action categories along with seven body part labels, and encompasses a full array of realistic and natural micro-actions, accounting for 205 participants and 22,422 video instances collated from the psychological interviews. Based on the proposed dataset, we assess MANet and other nine prevalent action recognition methods. MANet incorporates squeeze-and excitation (SE) and temporal shift module (TSM) into the ResNet architecture for modeling the spatiotemporal characteristics of micro-actions. Then a joint-embedding loss is designed for semantic matching between video and action labels; the loss is used to better distinguish between visually similar yet distinct micro-action categories. The extended application in emotion recognition has demonstrated one of the important values of our proposed dataset and method. In the future, further exploration of human behaviour, emotion, and psychological assessment will be conducted in depth. The dataset and source code are released at https://github.com/VUT-HFUT/Micro-Action.
Read more6/4/2024

0
Multi-Granularity Hand Action Detection
Ting Zhe, Jing Zhang, Yongqian Li, Yong Luo, Han Hu, Dacheng Tao
Detecting hand actions in videos is crucial for understanding video content and has diverse real-world applications. Existing approaches often focus on whole-body actions or coarse-grained action categories, lacking fine-grained hand-action localization information. To fill this gap, we introduce the FHA-Kitchens (Fine-Grained Hand Actions in Kitchen Scenes) dataset, providing both coarse- and fine-grained hand action categories along with localization annotations. This dataset comprises 2,377 video clips and 30,047 frames, annotated with approximately 200k bounding boxes and 880 action categories. Evaluation of existing action detection methods on FHA-Kitchens reveals varying generalization capabilities across different granularities. To handle multi-granularity in hand actions, we propose MG-HAD, an End-to-End Multi-Granularity Hand Action Detection method. It incorporates two new designs: Multi-dimensional Action Queries and Coarse-Fine Contrastive Denoising. Extensive experiments demonstrate MG-HAD's effectiveness for multi-granularity hand action detection, highlighting the significance of FHA-Kitchens for future research and real-world applications. The dataset and source code are available at https://github.com/superZ678/MG-HAD.
Read more8/13/2024

0
One-Stage Open-Vocabulary Temporal Action Detection Leveraging Temporal Multi-scale and Action Label Features
Trung Thanh Nguyen, Yasutomo Kawanishi, Takahiro Komamizu, Ichiro Ide
Open-vocabulary Temporal Action Detection (Open-vocab TAD) is an advanced video analysis approach that expands Closed-vocabulary Temporal Action Detection (Closed-vocab TAD) capabilities. Closed-vocab TAD is typically confined to localizing and classifying actions based on a predefined set of categories. In contrast, Open-vocab TAD goes further and is not limited to these predefined categories. This is particularly useful in real-world scenarios where the variety of actions in videos can be vast and not always predictable. The prevalent methods in Open-vocab TAD typically employ a 2-stage approach, which involves generating action proposals and then identifying those actions. However, errors made during the first stage can adversely affect the subsequent action identification accuracy. Additionally, existing studies face challenges in handling actions of different durations owing to the use of fixed temporal processing methods. Therefore, we propose a 1-stage approach consisting of two primary modules: Multi-scale Video Analysis (MVA) and Video-Text Alignment (VTA). The MVA module captures actions at varying temporal resolutions, overcoming the challenge of detecting actions with diverse durations. The VTA module leverages the synergy between visual and textual modalities to precisely align video segments with corresponding action labels, a critical step for accurate action identification in Open-vocab scenarios. Evaluations on widely recognized datasets THUMOS14 and ActivityNet-1.3, showed that the proposed method achieved superior results compared to the other methods in both Open-vocab and Closed-vocab settings. This serves as a strong demonstration of the effectiveness of the proposed method in the TAD task.
Read more5/1/2024