MMCert: Provable Defense against Adversarial Attacks to Multi-modal Models

0

Sign in to get full access
Overview
- This research paper introduces "MMCert", a new defense mechanism against adversarial attacks on multi-modal AI models.
- Multi-modal models combine different input types, like images and text, to make predictions.
- Adversarial attacks are subtle, imperceptible changes to inputs that can fool these models into making incorrect predictions.
- MMCert aims to provably defend multi-modal models against such adversarial attacks.
Plain English Explanation
Multi-modal AI models are powerful tools that can process and analyze different types of data, like images and text, to make decisions. However, these models can be vulnerable to adversarial attacks - small, almost imperceptible changes to the input data that cause the model to make incorrect predictions.
The researchers developed a new defense mechanism called MMCert that can protect multi-modal models from these adversarial attacks. MMCert works by adding a specialized "certification" layer to the model that verifies the inputs and ensures they have not been tampered with before passing them to the main prediction model. This certification process provides a mathematical guarantee that the model's outputs will be robust and reliable, even in the face of adversarial attacks.
The key innovation of MMCert is that it can certify the safety of multi-modal models, which combine different data types like images and text. Previous defenses were limited to single-modal models. By expanding the scope of provable robustness to multi-modal settings, MMCert represents an important advance in making AI systems more secure and trustworthy.
Technical Explanation
The paper first provides background on adversarial attacks on multi-modal models. These attacks leverage the complex interactions between different input modalities to generate subtle perturbations that can fool the model. The authors highlight the limitations of existing single-modal defense mechanisms and motivate the need for a multi-modal solution.
MMCert works by training a specialized "certification network" alongside the main multi-modal prediction model. This certification network learns to verify that the inputs have not been adversarially modified before passing them to the prediction model. The authors formulate this certification as a constrained optimization problem and derive mathematical guarantees of the network's robustness.
Experiments on multiple benchmark multi-modal datasets demonstrate that MMCert can achieve state-of-the-art certified robustness, successfully defending against a range of adversarial attacks while maintaining high predictive performance on clean inputs. The authors also analyze the trade-offs between robustness, accuracy, and computational cost, providing guidance on practical deployment.
Critical Analysis
The paper provides a rigorous and well-designed defense mechanism against adversarial attacks on multi-modal AI models. The mathematical foundations of MMCert's certification process are sound and the experimental results are compelling.
However, the authors acknowledge that MMCert is not a panacea - there may be some attack strategies that can bypass the certification process. Additionally, the increased computational overhead of the certification network may limit the practical deployment of MMCert, especially for resource-constrained applications.
Further research is needed to explore the broader security implications of multi-modal AI systems and to develop even more efficient and comprehensive defense mechanisms. Investigating the robustness of MMCert against adaptive adversaries who may attempt to circumvent the certification process would also be a valuable direction.
Conclusion
This paper presents a significant advancement in the field of adversarial robustness for multi-modal AI models. By introducing MMCert, a provable defense mechanism that can certify the safety of combined image and text inputs, the researchers have expanded the scope of trustworthy and secure AI systems.
The successful evaluation of MMCert on benchmark datasets suggests that it could be a valuable tool for deploying multi-modal AI in high-stakes applications where reliability is paramount. As AI continues to permeate more aspects of our lives, developing robust defenses against adversarial threats will be crucial for ensuring the trustworthiness and safety of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MMCert: Provable Defense against Adversarial Attacks to Multi-modal Models
Yanting Wang, Hongye Fu, Wei Zou, Jinyuan Jia
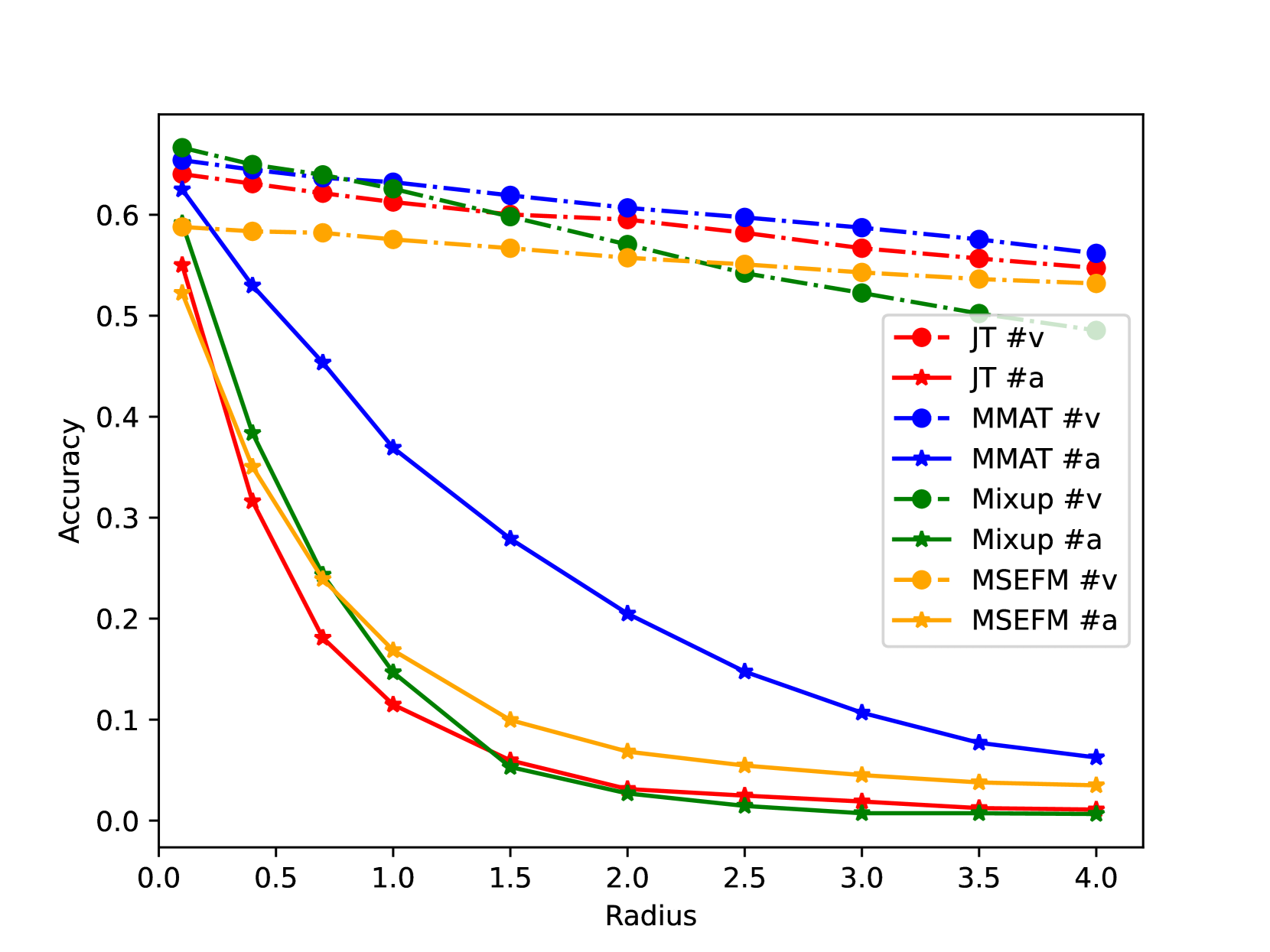
Different from a unimodal model whose input is from a single modality, the input (called multi-modal input) of a multi-modal model is from multiple modalities such as image, 3D points, audio, text, etc. Similar to unimodal models, many existing studies show that a multi-modal model is also vulnerable to adversarial perturbation, where an attacker could add small perturbation to all modalities of a multi-modal input such that the multi-modal model makes incorrect predictions for it. Existing certified defenses are mostly designed for unimodal models, which achieve sub-optimal certified robustness guarantees when extended to multi-modal models as shown in our experimental results. In our work, we propose MMCert, the first certified defense against adversarial attacks to a multi-modal model. We derive a lower bound on the performance of our MMCert under arbitrary adversarial attacks with bounded perturbations to both modalities (e.g., in the context of auto-driving, we bound the number of changed pixels in both RGB image and depth image). We evaluate our MMCert using two benchmark datasets: one for the multi-modal road segmentation task and the other for the multi-modal emotion recognition task. Moreover, we compare our MMCert with a state-of-the-art certified defense extended from unimodal models. Our experimental results show that our MMCert outperforms the baseline.
Read more4/3/2024
0
Quantifying and Enhancing Multi-modal Robustness with Modality Preference
Zequn Yang, Yake Wei, Ce Liang, Di Hu
Multi-modal models have shown a promising capability to effectively integrate information from various sources, yet meanwhile, they are found vulnerable to pervasive perturbations, such as uni-modal attacks and missing conditions. To counter these perturbations, robust multi-modal representations are highly expected, which are positioned well away from the discriminative multi-modal decision boundary. In this paper, different from conventional empirical studies, we focus on a commonly used joint multi-modal framework and theoretically discover that larger uni-modal representation margins and more reliable integration for modalities are essential components for achieving higher robustness. This discovery can further explain the limitation of multi-modal robustness and the phenomenon that multi-modal models are often vulnerable to attacks on the specific modality. Moreover, our analysis reveals how the widespread issue, that the model has different preferences for modalities, limits the multi-modal robustness by influencing the essential components and could lead to attacks on the specific modality highly effective. Inspired by our theoretical finding, we introduce a training procedure called Certifiable Robust Multi-modal Training (CRMT), which can alleviate this influence from modality preference and explicitly regulate essential components to significantly improve robustness in a certifiable manner. Our method demonstrates substantial improvements in performance and robustness compared with existing methods. Furthermore, our training procedure can be easily extended to enhance other robust training strategies, highlighting its credibility and flexibility.
Read more4/19/2024

0
Adversarial Attacks to Multi-Modal Models
Zhihao Dou, Xin Hu, Haibo Yang, Zhuqing Liu, Minghong Fang
Multi-modal models have gained significant attention due to their powerful capabilities. These models effectively align embeddings across diverse data modalities, showcasing superior performance in downstream tasks compared to their unimodal counterparts. Recent study showed that the attacker can manipulate an image or audio file by altering it in such a way that its embedding matches that of an attacker-chosen targeted input, thereby deceiving downstream models. However, this method often underperforms due to inherent disparities in data from different modalities. In this paper, we introduce CrossFire, an innovative approach to attack multi-modal models. CrossFire begins by transforming the targeted input chosen by the attacker into a format that matches the modality of the original image or audio file. We then formulate our attack as an optimization problem, aiming to minimize the angular deviation between the embeddings of the transformed input and the modified image or audio file. Solving this problem determines the perturbations to be added to the original media. Our extensive experiments on six real-world benchmark datasets reveal that CrossFire can significantly manipulate downstream tasks, surpassing existing attacks. Additionally, we evaluate six defensive strategies against CrossFire, finding that current defenses are insufficient to counteract our CrossFire.
Read more9/25/2024
0
Unbridled Icarus: A Survey of the Potential Perils of Image Inputs in Multimodal Large Language Model Security
Yihe Fan, Yuxin Cao, Ziyu Zhao, Ziyao Liu, Shaofeng Li
Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities that increasingly influence various aspects of our daily lives, constantly defining the new boundary of Artificial General Intelligence (AGI). Image modalities, enriched with profound semantic information and a more continuous mathematical nature compared to other modalities, greatly enhance the functionalities of MLLMs when integrated. However, this integration serves as a double-edged sword, providing attackers with expansive vulnerabilities to exploit for highly covert and harmful attacks. The pursuit of reliable AI systems like powerful MLLMs has emerged as a pivotal area of contemporary research. In this paper, we endeavor to demostrate the multifaceted risks associated with the incorporation of image modalities into MLLMs. Initially, we delineate the foundational components and training processes of MLLMs. Subsequently, we construct a threat model, outlining the security vulnerabilities intrinsic to MLLMs. Moreover, we analyze and summarize existing scholarly discourses on MLLMs' attack and defense mechanisms, culminating in suggestions for the future research on MLLM security. Through this comprehensive analysis, we aim to deepen the academic understanding of MLLM security challenges and propel forward the development of trustworthy MLLM systems.
Read more8/13/2024