DifFUSER: Diffusion Model for Robust Multi-Sensor Fusion in 3D Object Detection and BEV Segmentation
2404.04629
0
0

Abstract
Diffusion models have recently gained prominence as powerful deep generative models, demonstrating unmatched performance across various domains. However, their potential in multi-sensor fusion remains largely unexplored. In this work, we introduce DifFUSER, a novel approach that leverages diffusion models for multi-modal fusion in 3D object detection and BEV map segmentation. Benefiting from the inherent denoising property of diffusion, DifFUSER is able to refine or even synthesize sensor features in case of sensor malfunction, thereby improving the quality of the fused output. In terms of architecture, our DifFUSER blocks are chained together in a hierarchical BiFPN fashion, termed cMini-BiFPN, offering an alternative architecture for latent diffusion. We further introduce a Gated Self-conditioned Modulated (GSM) latent diffusion module together with a Progressive Sensor Dropout Training (PSDT) paradigm, designed to add stronger conditioning to the diffusion process and robustness to sensor failures. Our extensive evaluations on the Nuscenes dataset reveal that DifFUSER not only achieves state-of-the-art performance with a 69.1% mIOU in BEV map segmentation tasks but also competes effectively with leading transformer-based fusion techniques in 3D object detection.
Create account to get full access
Overview
- This paper proposes a diffusion model-based approach for robust multi-sensor fusion in 3D object detection and bird's-eye view (BEV) segmentation tasks.
- The model integrates information from various sensors, such as cameras and LiDAR, to enhance the accuracy and reliability of 3D object detection and BEV segmentation.
- The diffusion-based framework aims to address challenges posed by sensor noise, occlusions, and inconsistencies in the input data.
Plain English Explanation
The paper describes a new way to combine information from different sensors, like cameras and laser scanners (LiDAR), to improve the accuracy of 3D object detection and the creation of bird's-eye view (BEV) maps. The key idea is to use a diffusion model, which is a type of machine learning technique that can handle noisy and incomplete data.
The diffusion model acts like a filter, smoothing out the inconsistencies and errors in the sensor data. This helps the system better understand the 3D environment and accurately identify and locate objects, even when the input data from the individual sensors is not perfect. By fusing the data from multiple sensors using the diffusion model, the researchers were able to create more reliable 3D object detections and BEV maps, which are important for applications like self-driving cars and robotic navigation.
Technical Explanation
The paper introduces a diffusion-based approach for robust multi-sensor fusion in 3D object detection and BEV segmentation. The proposed framework leverages the diffusion model, a powerful machine learning technique, to integrate information from various sensors, such as cameras and LiDAR.
The diffusion model is used to address challenges posed by sensor noise, occlusions, and inconsistencies in the input data. By modeling the diffusion of information across the sensor modalities, the framework can effectively fuse the data and enhance the accuracy and robustness of 3D object detection and BEV segmentation tasks.
The paper presents experimental results on several benchmark datasets, demonstrating the effectiveness of the diffusion-based approach compared to traditional multi-sensor fusion methods. The model is shown to outperform state-of-the-art techniques in terms of 3D object detection and BEV segmentation performance.
Critical Analysis
The paper presents a novel and promising approach to multi-sensor fusion for 3D object detection and BEV segmentation. The use of the diffusion model is a key strength, as it can handle the inherent noise and inconsistencies in sensor data, which is a common challenge in these applications.
However, the paper does not extensively discuss the limitations or potential drawbacks of the diffusion-based approach. For example, it would be valuable to understand the computational complexity of the model and its implications for real-time deployment in autonomous systems.
Additionally, the paper could have provided a more in-depth analysis of the specific scenarios or environmental conditions where the diffusion-based fusion approach excels or falls short compared to other methods. This could help researchers and practitioners better understand the strengths and weaknesses of the proposed technique and guide future research directions.
Conclusion
This paper introduces a novel diffusion-based approach for robust multi-sensor fusion in 3D object detection and BEV segmentation tasks. By leveraging the power of diffusion models, the proposed framework can effectively integrate data from various sensors, such as cameras and LiDAR, to enhance the accuracy and reliability of these critical computer vision and robotics applications.
The experimental results demonstrate the effectiveness of the diffusion-based fusion approach, which outperforms state-of-the-art techniques on benchmark datasets. This research represents an important step forward in addressing the challenges posed by sensor noise, occlusions, and inconsistencies in multi-sensor fusion for 3D perception tasks, with potential applications in autonomous vehicles, robotics, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Diffusion Features to Bridge Domain Gap for Semantic Segmentation
Yuxiang Ji, Boyong He, Chenyuan Qu, Zhuoyue Tan, Chuan Qin, Liaoni Wu
0
0
Pre-trained diffusion models have demonstrated remarkable proficiency in synthesizing images across a wide range of scenarios with customizable prompts, indicating their effective capacity to capture universal features. Motivated by this, our study delves into the utilization of the implicit knowledge embedded within diffusion models to address challenges in cross-domain semantic segmentation. This paper investigates the approach that leverages the sampling and fusion techniques to harness the features of diffusion models efficiently. Contrary to the simplistic migration applications characterized by prior research, our finding reveals that the multi-step diffusion process inherent in the diffusion model manifests more robust semantic features. We propose DIffusion Feature Fusion (DIFF) as a backbone use for extracting and integrating effective semantic representations through the diffusion process. By leveraging the strength of text-to-image generation capability, we introduce a new training framework designed to implicitly learn posterior knowledge from it. Through rigorous evaluation in the contexts of domain generalization semantic segmentation, we establish that our methodology surpasses preceding approaches in mitigating discrepancies across distinct domains and attains the state-of-the-art (SOTA) benchmark. Within the synthetic-to-real (syn-to-real) context, our method significantly outperforms ResNet-based and transformer-based backbone methods, achieving an average improvement of $3.84%$ mIoU across various datasets. The implementation code will be released soon.
6/4/2024
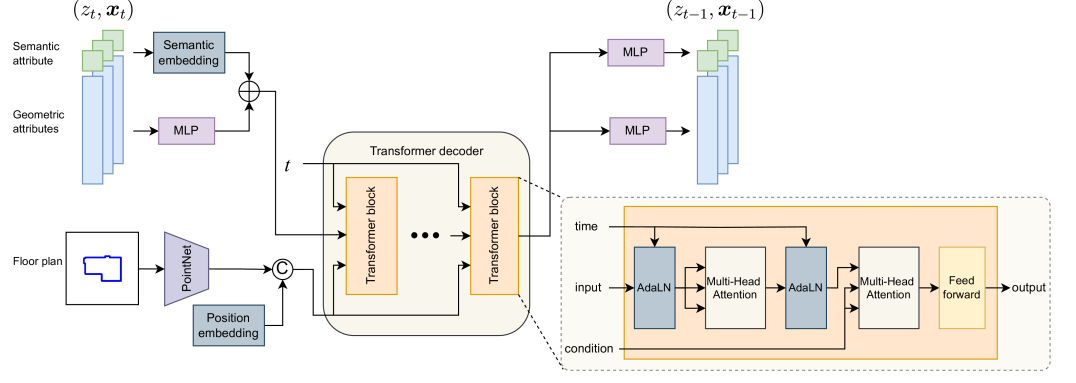
Mixed Diffusion for 3D Indoor Scene Synthesis
Siyi Hu, Diego Martin Arroyo, Stephanie Debats, Fabian Manhardt, Luca Carlone, Federico Tombari
0
0
Realistic conditional 3D scene synthesis significantly enhances and accelerates the creation of virtual environments, which can also provide extensive training data for computer vision and robotics research among other applications. Diffusion models have shown great performance in related applications, e.g., making precise arrangements of unordered sets. However, these models have not been fully explored in floor-conditioned scene synthesis problems. We present MiDiffusion, a novel mixed discrete-continuous diffusion model architecture, designed to synthesize plausible 3D indoor scenes from given room types, floor plans, and potentially pre-existing objects. We represent a scene layout by a 2D floor plan and a set of objects, each defined by its category, location, size, and orientation. Our approach uniquely implements structured corruption across the mixed discrete semantic and continuous geometric domains, resulting in a better conditioned problem for the reverse denoising step. We evaluate our approach on the 3D-FRONT dataset. Our experimental results demonstrate that MiDiffusion substantially outperforms state-of-the-art autoregressive and diffusion models in floor-conditioned 3D scene synthesis. In addition, our models can handle partial object constraints via a corruption-and-masking strategy without task specific training. We show MiDiffusion maintains clear advantages over existing approaches in scene completion and furniture arrangement experiments.
6/3/2024

DiffTF++: 3D-aware Diffusion Transformer for Large-Vocabulary 3D Generation
Ziang Cao, Fangzhou Hong, Tong Wu, Liang Pan, Ziwei Liu
0
0
Generating diverse and high-quality 3D assets automatically poses a fundamental yet challenging task in 3D computer vision. Despite extensive efforts in 3D generation, existing optimization-based approaches struggle to produce large-scale 3D assets efficiently. Meanwhile, feed-forward methods often focus on generating only a single category or a few categories, limiting their generalizability. Therefore, we introduce a diffusion-based feed-forward framework to address these challenges with a single model. To handle the large diversity and complexity in geometry and texture across categories efficiently, we 1) adopt improved triplane to guarantee efficiency; 2) introduce the 3D-aware transformer to aggregate the generalized 3D knowledge with specialized 3D features; and 3) devise the 3D-aware encoder/decoder to enhance the generalized 3D knowledge. Building upon our 3D-aware Diffusion model with TransFormer, DiffTF, we propose a stronger version for 3D generation, i.e., DiffTF++. It boils down to two parts: multi-view reconstruction loss and triplane refinement. Specifically, we utilize multi-view reconstruction loss to fine-tune the diffusion model and triplane decoder, thereby avoiding the negative influence caused by reconstruction errors and improving texture synthesis. By eliminating the mismatch between the two stages, the generative performance is enhanced, especially in texture. Additionally, a 3D-aware refinement process is introduced to filter out artifacts and refine triplanes, resulting in the generation of more intricate and reasonable details. Extensive experiments on ShapeNet and OmniObject3D convincingly demonstrate the effectiveness of our proposed modules and the state-of-the-art 3D object generation performance with large diversity, rich semantics, and high quality.
5/15/2024
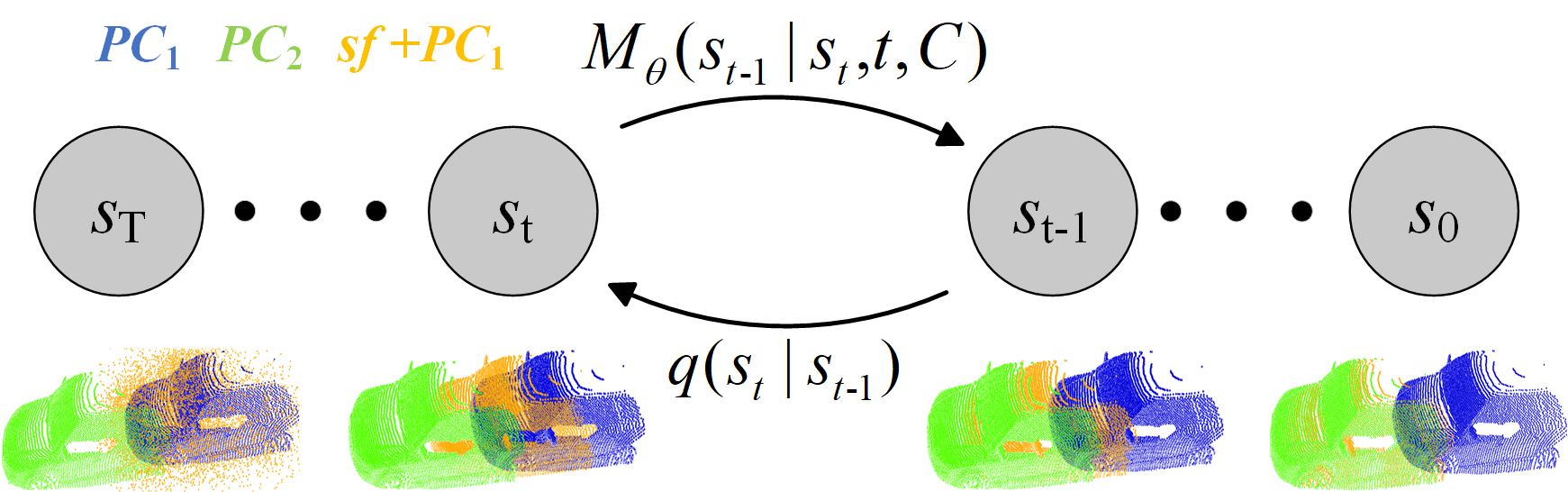
DifFlow3D: Toward Robust Uncertainty-Aware Scene Flow Estimation with Diffusion Model
Jiuming Liu, Guangming Wang, Weicai Ye, Chaokang Jiang, Jinru Han, Zhe Liu, Guofeng Zhang, Dalong Du, Hesheng Wang
0
0
Scene flow estimation, which aims to predict per-point 3D displacements of dynamic scenes, is a fundamental task in the computer vision field. However, previous works commonly suffer from unreliable correlation caused by locally constrained searching ranges, and struggle with accumulated inaccuracy arising from the coarse-to-fine structure. To alleviate these problems, we propose a novel uncertainty-aware scene flow estimation network (DifFlow3D) with the diffusion probabilistic model. Iterative diffusion-based refinement is designed to enhance the correlation robustness and resilience to challenging cases, e.g. dynamics, noisy inputs, repetitive patterns, etc. To restrain the generation diversity, three key flow-related features are leveraged as conditions in our diffusion model. Furthermore, we also develop an uncertainty estimation module within diffusion to evaluate the reliability of estimated scene flow. Our DifFlow3D achieves state-of-the-art performance, with 24.0% and 29.1% EPE3D reduction respectively on FlyingThings3D and KITTI 2015 datasets. Notably, our method achieves an unprecedented millimeter-level accuracy (0.0078m in EPE3D) on the KITTI dataset. Additionally, our diffusion-based refinement paradigm can be readily integrated as a plug-and-play module into existing scene flow networks, significantly increasing their estimation accuracy. Codes are released at https://github.com/IRMVLab/DifFlow3D.
5/13/2024