MMM and MMMSynth: Clustering of heterogeneous tabular data, and synthetic data generation
2310.19454
0
0
🔗
Abstract
We provide new algorithms for two tasks relating to heterogeneous tabular datasets: clustering, and synthetic data generation. Tabular datasets typically consist of heterogeneous data types (numerical, ordinal, categorical) in columns, but may also have hidden cluster structure in their rows: for example, they may be drawn from heterogeneous (geographical, socioeconomic, methodological) sources, such that the outcome variable they describe (such as the presence of a disease) may depend not only on the other variables but on the cluster context. Moreover, sharing of biomedical data is often hindered by patient confidentiality laws, and there is current interest in algorithms to generate synthetic tabular data from real data, for example via deep learning. We demonstrate a novel EM-based clustering algorithm, MMM (``Madras Mixture Model''), that outperforms standard algorithms in determining clusters in synthetic heterogeneous data, and recovers structure in real data. Based on this, we demonstrate a synthetic tabular data generation algorithm, MMMsynth, that pre-clusters the input data, and generates cluster-wise synthetic data assuming cluster-specific data distributions for the input columns. We benchmark this algorithm by testing the performance of standard ML algorithms when they are trained on synthetic data and tested on real published datasets. Our synthetic data generation algorithm outperforms other literature tabular-data generators, and approaches the performance of training purely with real data.
Create account to get full access
Overview
• This paper introduces new algorithms for two important tasks in heterogeneous tabular datasets: clustering and synthetic data generation.
• The authors demonstrate a novel EM-based clustering algorithm, called MMM (Madras Mixture Model), that outperforms standard algorithms in determining clusters in synthetic heterogeneous data and recovering structure in real data.
• Building on the MMM clustering algorithm, the authors also present a synthetic tabular data generation algorithm, MMMsynth, that pre-clusters the input data and generates cluster-wise synthetic data assuming cluster-specific data distributions.
• The authors benchmark the MMMsynth algorithm by testing the performance of standard ML algorithms when they are trained on synthetic data and tested on real published datasets. The results show that the synthetic data generation algorithm outperforms other literature tabular-data generators and approaches the performance of training purely with real data.
Plain English Explanation
Tabular datasets often contain a mix of different data types, such as numerical, ordinal, and categorical, in their columns. These datasets may also have hidden clusters or groups in their rows, based on factors like geographical, socioeconomic, or methodological differences in the data sources. Additionally, sharing of sensitive biomedical data is often hindered by privacy concerns, leading to interest in algorithms that can generate synthetic data that preserves the characteristics of the original data.
The authors of this paper have developed a new algorithm, called MMM (Madras Mixture Model), that is particularly effective at identifying these hidden clusters in heterogeneous tabular data. The MMM algorithm outperforms standard clustering methods in both synthetic and real-world datasets, helping to reveal the underlying structure of the data.
Building on the MMM clustering algorithm, the authors have also created a synthetic data generation algorithm, called MMMsynth. This algorithm first identifies the clusters in the original data, and then generates new synthetic data that mimics the cluster-specific data distributions. When tested, the MMMsynth algorithm outperformed other tabular data generators and was able to produce synthetic data that performed almost as well as the original real-world data when used to train standard machine learning models.
Technical Explanation
The authors of this paper present two novel algorithms for working with heterogeneous tabular datasets: a clustering algorithm called MMM (Madras Mixture Model) and a synthetic data generation algorithm called MMMsynth.
The MMM algorithm is an EM-based (Expectation-Maximization) clustering approach that can effectively handle the mixed data types (numerical, ordinal, categorical) often found in tabular datasets. The authors demonstrate that MMM outperforms standard clustering algorithms in identifying the hidden cluster structure in both synthetic and real-world datasets.
Building on the MMM clustering, the authors' MMMsynth algorithm generates synthetic tabular data that preserves the cluster-specific data distributions. The MMMsynth algorithm first pre-clusters the input data using MMM, and then generates new synthetic data for each cluster, assuming cluster-specific data distributions for the input columns.
The authors benchmark the MMMsynth algorithm by training standard machine learning models on the synthetic data and evaluating their performance on real-world published datasets. The results show that the synthetic data generated by MMMsynth outperforms other tabular data generators in the literature and approaches the performance of training on the original real-world data.
Critical Analysis
The authors acknowledge several limitations and areas for further research in their work. For example, they note that the MMM clustering algorithm may not be suitable for very high-dimensional datasets, and that the MMMsynth data generation approach assumes the input data has a cluster structure, which may not always be the case.
Additionally, while the authors demonstrate the effectiveness of their synthetic data generation approach, they do not provide a thorough analysis of the statistical properties or the utility of the generated data for specific downstream tasks. Further research may be needed to understand the broader implications and limitations of using synthetic data generated by MMMsynth.
Another potential area of concern is the potential for bias or fairness issues to be introduced or amplified when using synthetic data, especially in sensitive domains like healthcare. The authors do not address these important considerations in the current paper, and future work should explore the potential ethical and societal impacts of their methods.
Despite these limitations, the authors present a valuable contribution to the field of heterogeneous tabular data analysis, with their novel clustering and synthetic data generation algorithms offering promising avenues for further research and applications.
Conclusion
This paper introduces two new algorithms that address important challenges in working with heterogeneous tabular datasets: the MMM clustering algorithm and the MMMsynth synthetic data generation algorithm.
The MMM algorithm demonstrates superior performance in identifying hidden cluster structures in mixed-type tabular data, compared to standard clustering methods. Building on this, the MMMsynth algorithm is able to generate synthetic tabular data that preserves the cluster-specific data distributions, and performs well when used to train standard machine learning models.
While the authors acknowledge several limitations and areas for future research, their work represents a significant advancement in the field of tabular data analysis, with potential applications in domains like healthcare, where data sharing is often hindered by privacy concerns. The authors' innovations in clustering and synthetic data generation could pave the way for more effective and responsible use of heterogeneous tabular data in a variety of settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👨🏫
A supervised generative optimization approach for tabular data
Shinpei Nakamura-Sakai, Fadi Hamad, Saheed Obitayo, Vamsi K. Potluru
0
0
Synthetic data generation has emerged as a crucial topic for financial institutions, driven by multiple factors, such as privacy protection and data augmentation. Many algorithms have been proposed for synthetic data generation but reaching the consensus on which method we should use for the specific data sets and use cases remains challenging. Moreover, the majority of existing approaches are ``unsupervised'' in the sense that they do not take into account the downstream task. To address these issues, this work presents a novel synthetic data generation framework. The framework integrates a supervised component tailored to the specific downstream task and employs a meta-learning approach to learn the optimal mixture distribution of existing synthetic distributions.
5/13/2024
Group-wise Prompting for Synthetic Tabular Data Generation using Large Language Models
Jinhee Kim, Taesung Kim, Jaegul Choo
0
0
Large language models (LLMs) have demonstrated impressive in-context learning capabilities across various domains. Inspired by this, our study explores the effectiveness of LLMs in generating realistic tabular data to mitigate class imbalance. We investigate and identify key prompt design elements such as data format, class presentation, and variable mapping to optimize the generation performance. Our findings indicate that using CSV format, balancing classes, and employing unique variable mapping produces realistic and reliable data, significantly enhancing machine learning performance for minor classes in imbalanced datasets. Additionally, these approaches improve the stability and efficiency of LLM data generation. We validate our approach using six real-world datasets and a toy dataset, achieving state-of-the-art performance in classification tasks. The code is available at: https://github.com/seharanul17/synthetic-tabular-LLM
5/28/2024
Masked Language Modeling Becomes Conditional Density Estimation for Tabular Data Synthesis
Seunghwan An, Gyeongdong Woo, Jaesung Lim, ChangHyun Kim, Sungchul Hong, Jong-June Jeon
0
0
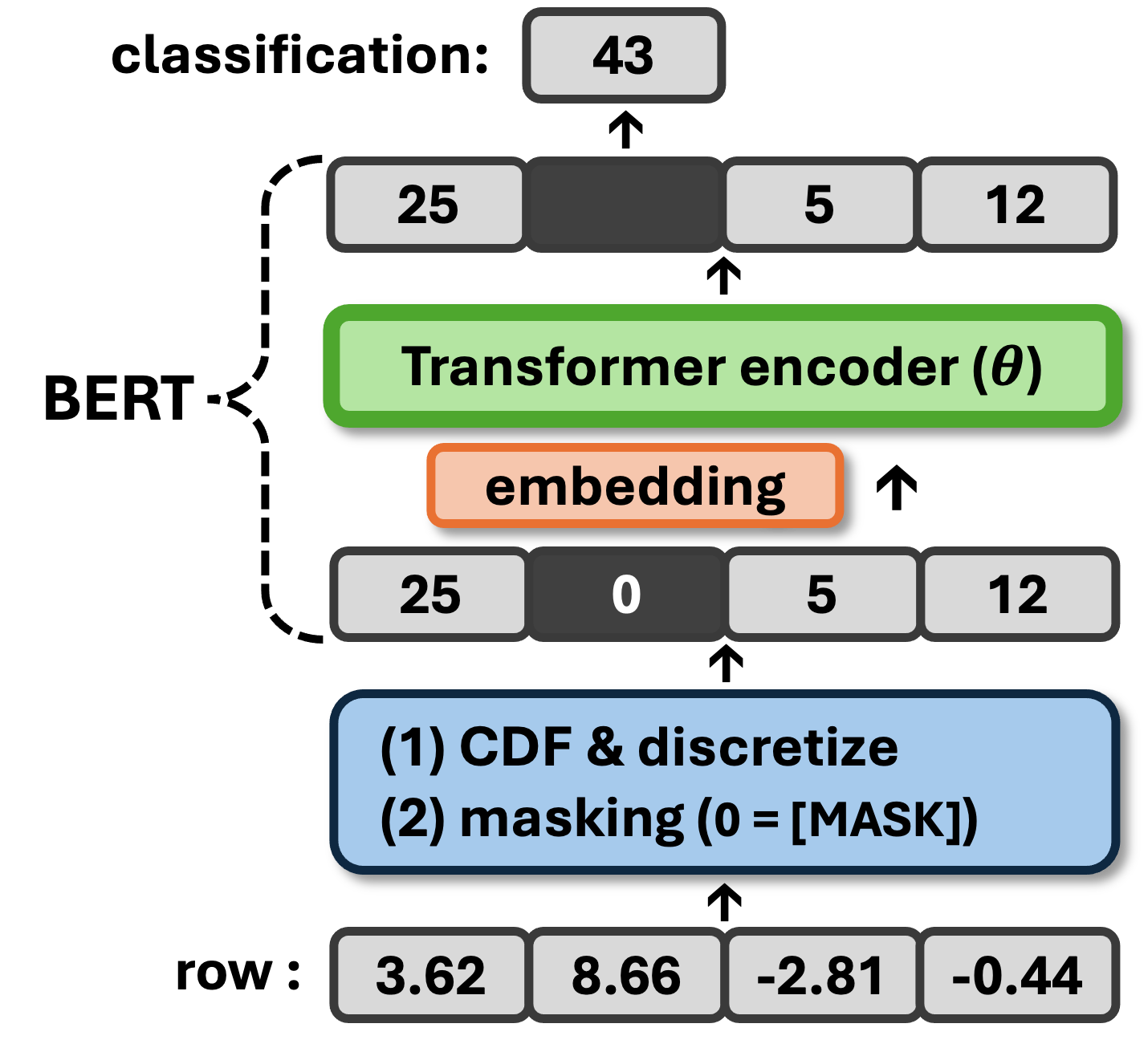
In this paper, our goal is to generate synthetic data for heterogeneous (mixed-type) tabular datasets with high machine learning utility (MLu). Given that the MLu performance relies on accurately approximating the conditional distributions, we focus on devising a synthetic data generation method based on conditional distribution estimation. We propose a novel synthetic data generation method, MaCoDE, by redefining the multi-class classification task of Masked Language Modeling (MLM) as histogram-based non-parametric conditional density estimation. Our proposed method enables estimating conditional densities across arbitrary combinations of target and conditional variables. Furthermore, we demonstrate that our proposed method bridges the theoretical gap between distributional learning and MLM. To validate the effectiveness of our proposed model, we conduct synthetic data generation experiments on 10 real-world datasets. Given the analogy between predicting masked input tokens in MLM and missing data imputation, we also evaluate the performance of multiple imputations on incomplete datasets with various missing data mechanisms. Moreover, our proposed model offers the advantage of enabling adjustments to data privacy levels without requiring re-training.
6/3/2024
Are LLMs Naturally Good at Synthetic Tabular Data Generation?
Shengzhe Xu, Cho-Ting Lee, Mandar Sharma, Raquib Bin Yousuf, Nikhil Muralidhar, Naren Ramakrishnan
0
0
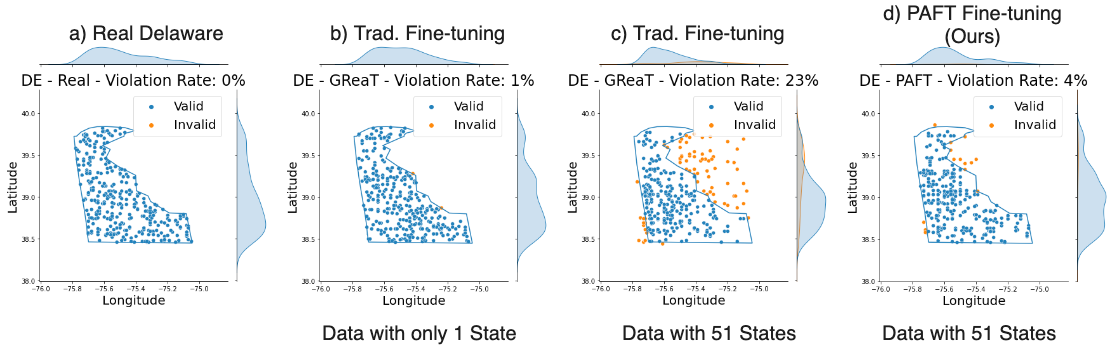
Large language models (LLMs) have demonstrated their prowess in generating synthetic text and images; however, their potential for generating tabular data -- arguably the most common data type in business and scientific applications -- is largely underexplored. This paper demonstrates that LLMs, used as-is, or after traditional fine-tuning, are severely inadequate as synthetic table generators. Due to the autoregressive nature of LLMs, fine-tuning with random order permutation runs counter to the importance of modeling functional dependencies, and renders LLMs unable to model conditional mixtures of distributions (key to capturing real world constraints). We showcase how LLMs can be made to overcome some of these deficiencies by making them permutation-aware.
6/24/2024