Masked Language Modeling Becomes Conditional Density Estimation for Tabular Data Synthesis
2405.20602
0
0
Abstract
In this paper, our goal is to generate synthetic data for heterogeneous (mixed-type) tabular datasets with high machine learning utility (MLu). Given that the MLu performance relies on accurately approximating the conditional distributions, we focus on devising a synthetic data generation method based on conditional distribution estimation. We propose a novel synthetic data generation method, MaCoDE, by redefining the multi-class classification task of Masked Language Modeling (MLM) as histogram-based non-parametric conditional density estimation. Our proposed method enables estimating conditional densities across arbitrary combinations of target and conditional variables. Furthermore, we demonstrate that our proposed method bridges the theoretical gap between distributional learning and MLM. To validate the effectiveness of our proposed model, we conduct synthetic data generation experiments on 10 real-world datasets. Given the analogy between predicting masked input tokens in MLM and missing data imputation, we also evaluate the performance of multiple imputations on incomplete datasets with various missing data mechanisms. Moreover, our proposed model offers the advantage of enabling adjustments to data privacy levels without requiring re-training.
Create account to get full access
Overview
- This paper explores a new approach to tabular data synthesis using masked language modeling techniques.
- The proposed method, called Conditional Density Estimation for Tabular Data Synthesis, treats the tabular data generation task as a conditional density estimation problem.
- The model learns to estimate the conditional distributions of each column given the values of the other columns, allowing it to generate new, realistic-looking tabular samples.
- This is a significant departure from previous approaches, which often relied on generative adversarial networks (Multi-Objective Evolutionary GAN for Tabular Data Synthesis) or other complex architectures.
Plain English Explanation
The paper presents a new way to generate synthetic tabular data that looks and behaves like real data. Instead of using complicated machine learning models, the researchers treat the problem as one of "conditional density estimation." This means the model learns to predict the value of each column in the table, based on the values of the other columns.
Imagine you have a table of data with information about people, like their age, income, and education level. The model would learn how these different factors are related - for example, how age affects income or how education level is connected to income. Then, it can use this learned knowledge to generate new, realistic-looking rows of data that follow the same patterns as the original table.
This approach is simpler and more interpretable than some previous methods, like Generative Adversarial Networks (GANs), which can be harder to understand and tune. By framing the problem as conditional density estimation, the researchers have found a way to generate high-quality synthetic data while keeping the model relatively straightforward.
Technical Explanation
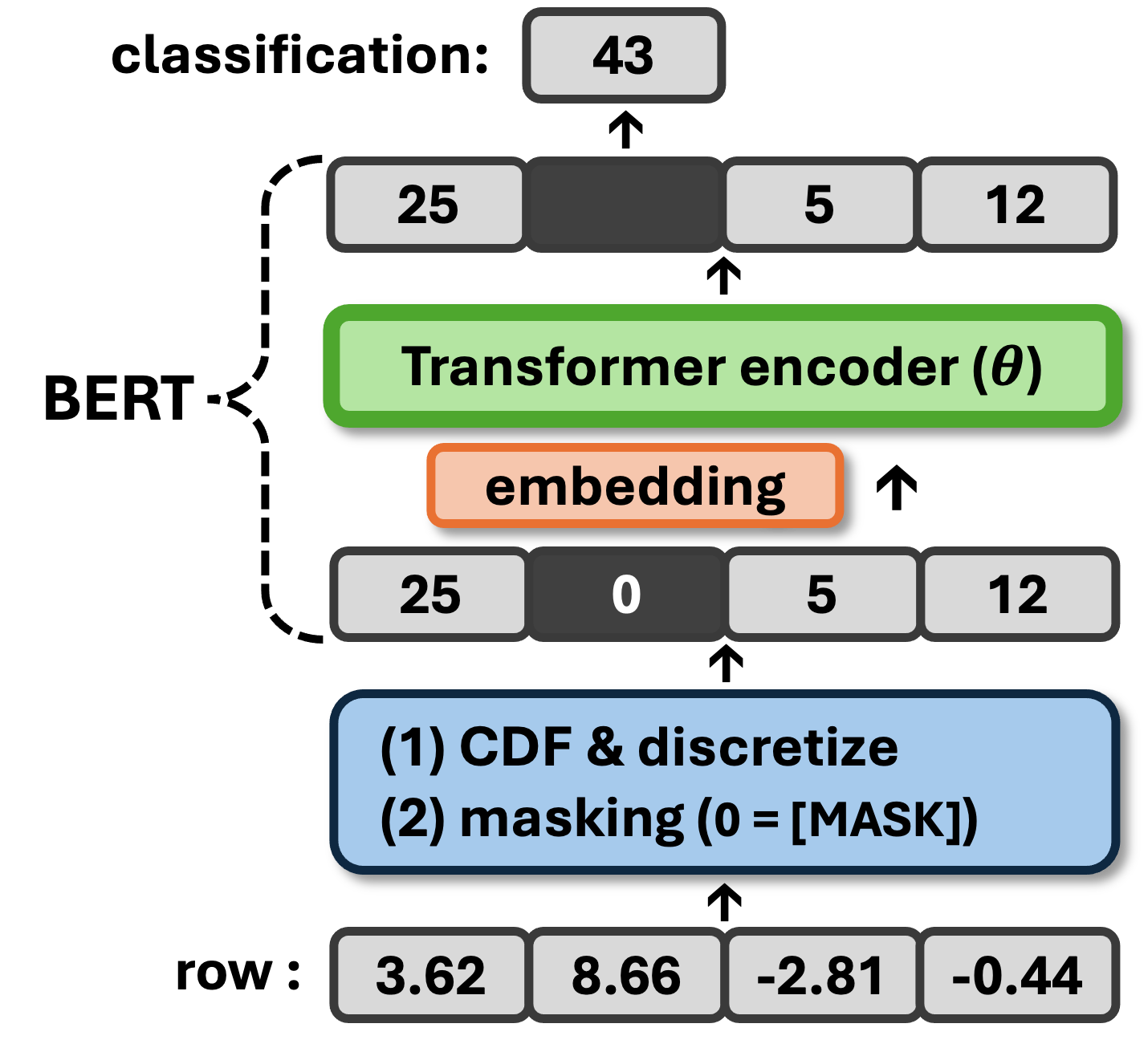
The key innovation of this paper is to cast the tabular data synthesis task as a conditional density estimation problem. Rather than trying to learn the full joint distribution of all the columns in the table, the model learns to estimate the conditional distribution of each column given the values of the other columns.
This is achieved by adapting the Masked Language Modeling (MLM) technique from the field of natural language processing. In MLM, a language model is trained to predict the missing words in a partially masked sentence. The authors apply a similar principle to tabular data, masking out the values of one column and training the model to predict those missing values based on the other columns.
By treating each column as a "token" to be predicted, the model can learn the complex relationships and dependencies within the tabular data. This allows it to generate new, realistic-looking rows that preserve the statistical properties and patterns of the original data.
The authors experiment with different model architectures, including Transformer-based models and autoregressive models, and find that the Transformer-based approach generally performs best. They also explore ways to handle different data types (e.g., categorical, continuous) and missing values within the tabular data.
Critical Analysis
The proposed approach represents a significant advancement in the field of tabular data synthesis, offering a more principled and interpretable alternative to previous methods like GANs. By framing the problem as conditional density estimation, the authors have developed a flexible and scalable framework that can handle a wide variety of tabular data characteristics.
One potential limitation of the method is that it may struggle with capturing long-range dependencies or complex, non-linear relationships within the data. The authors acknowledge this and suggest exploring ways to incorporate additional structural information or domain-specific knowledge to address this.
Additionally, the authors do not extensively explore the potential privacy or security implications of their approach. While generating synthetic data can be a valuable tool for preserving individual privacy, there are still open questions around the robustness of such methods to various attacks or the potential for information leakage.
Overall, this paper presents a compelling and innovative approach to tabular data synthesis, with a strong theoretical foundation and promising empirical results. As the authors note, there is still room for further research and refinement, particularly in the areas of interpretability, scalability, and privacy preservation. Researchers and practitioners in the field of data synthesis would do well to closely follow the developments in this area.
Conclusion
This paper introduces a new method for generating synthetic tabular data that treats the problem as one of conditional density estimation. By adapting the Masked Language Modeling technique from natural language processing, the authors have developed a flexible and interpretable approach that can capture the complex relationships and dependencies within tabular data.
The proposed method represents a significant advancement over previous approaches, such as Generative Adversarial Networks and Supervised Generative Optimization, offering a more principled and scalable framework for tabular data synthesis. The authors have demonstrated the effectiveness of their approach through extensive experimentation and have outlined several promising directions for future research.
As the field of data synthesis continues to evolve, this paper serves as an important contribution, showcasing the potential of leveraging techniques from natural language processing to tackle the unique challenges of working with tabular data. The insights and methodologies presented here are likely to have a lasting impact on the way researchers and practitioners approach the problem of generating high-quality synthetic data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Group-wise Prompting for Synthetic Tabular Data Generation using Large Language Models
Jinhee Kim, Taesung Kim, Jaegul Choo
0
0
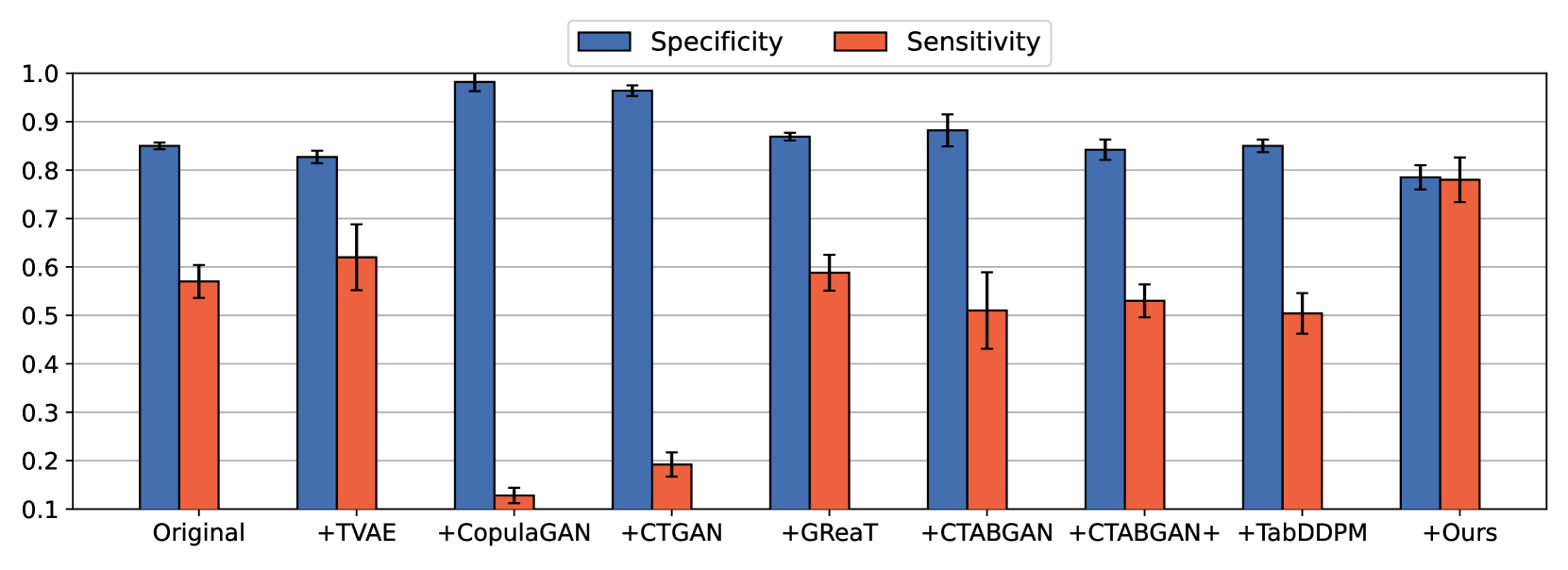
Large language models (LLMs) have demonstrated impressive in-context learning capabilities across various domains. Inspired by this, our study explores the effectiveness of LLMs in generating realistic tabular data to mitigate class imbalance. We investigate and identify key prompt design elements such as data format, class presentation, and variable mapping to optimize the generation performance. Our findings indicate that using CSV format, balancing classes, and employing unique variable mapping produces realistic and reliable data, significantly enhancing machine learning performance for minor classes in imbalanced datasets. Additionally, these approaches improve the stability and efficiency of LLM data generation. We validate our approach using six real-world datasets and a toy dataset, achieving state-of-the-art performance in classification tasks. The code is available at: https://github.com/seharanul17/synthetic-tabular-LLM
5/28/2024
MALLM-GAN: Multi-Agent Large Language Model as Generative Adversarial Network for Synthesizing Tabular Data
Yaobin Ling, Xiaoqian Jiang, Yejin Kim
0
0
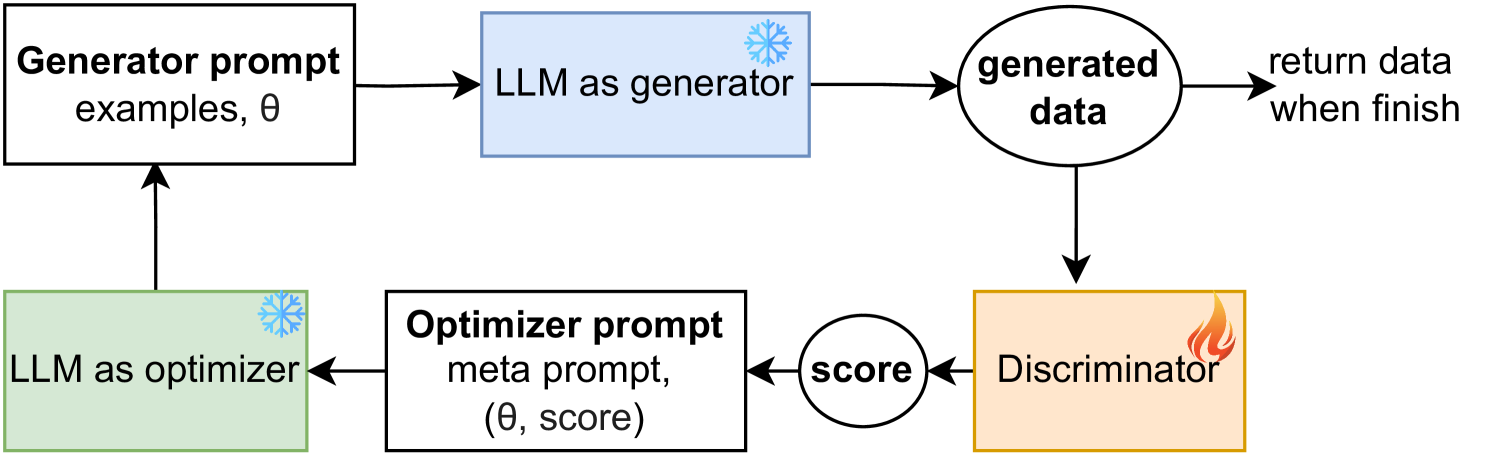
In the era of big data, access to abundant data is crucial for driving research forward. However, such data is often inaccessible due to privacy concerns or high costs, particularly in healthcare domain. Generating synthetic (tabular) data can address this, but existing models typically require substantial amounts of data to train effectively, contradicting our objective to solve data scarcity. To address this challenge, we propose a novel framework to generate synthetic tabular data, powered by large language models (LLMs) that emulates the architecture of a Generative Adversarial Network (GAN). By incorporating data generation process as contextual information and utilizing LLM as the optimizer, our approach significantly enhance the quality of synthetic data generation in common scenarios with small sample sizes. Our experimental results on public and private datasets demonstrate that our model outperforms several state-of-art models regarding generating higher quality synthetic data for downstream tasks while keeping privacy of the real data.
6/18/2024
💬
Exploration of Masked and Causal Language Modelling for Text Generation
Nicolo Micheletti, Samuel Belkadi, Lifeng Han, Goran Nenadic
0
0
Large Language Models (LLMs) have revolutionised the field of Natural Language Processing (NLP) and have achieved state-of-the-art performance in practically every task in this field. However, the prevalent approach used in text generation, Causal Language Modelling (CLM), which generates text sequentially from left to right, inherently limits the freedom of the model, which does not decide when and where each token is generated. In contrast, Masked Language Modelling (MLM), primarily used for language understanding tasks, can generate tokens anywhere in the text and any order. This paper conducts an extensive comparison of MLM and CLM approaches for text generation tasks. To do so, we pre-train several language models of comparable sizes on three different datasets, namely 1) medical discharge summaries, 2) movie plot synopses, and 3) authorship verification datasets. To assess the quality of the generations, we first employ quantitative metrics and then perform a qualitative human evaluation to analyse coherence and grammatical correctness. In addition, we evaluate the usefulness of the generated texts by using them in three different downstream tasks: 1) Entity Recognition, 2) Text Classification, and 3) Authorship Verification. The results show that MLM consistently outperforms CLM in text generation across all datasets, with higher quantitative scores and better coherence in the generated text. The study also finds textit{no strong correlation} between the quality of the generated text and the performance of the models in the downstream tasks. With this study, we show that MLM for text generation has great potential for future research and provides direction for future studies in this area.
5/22/2024
Multi-objective evolutionary GAN for tabular data synthesis
Nian Ran, Bahrul Ilmi Nasution, Claire Little, Richard Allmendinger, Mark Elliot
0
0
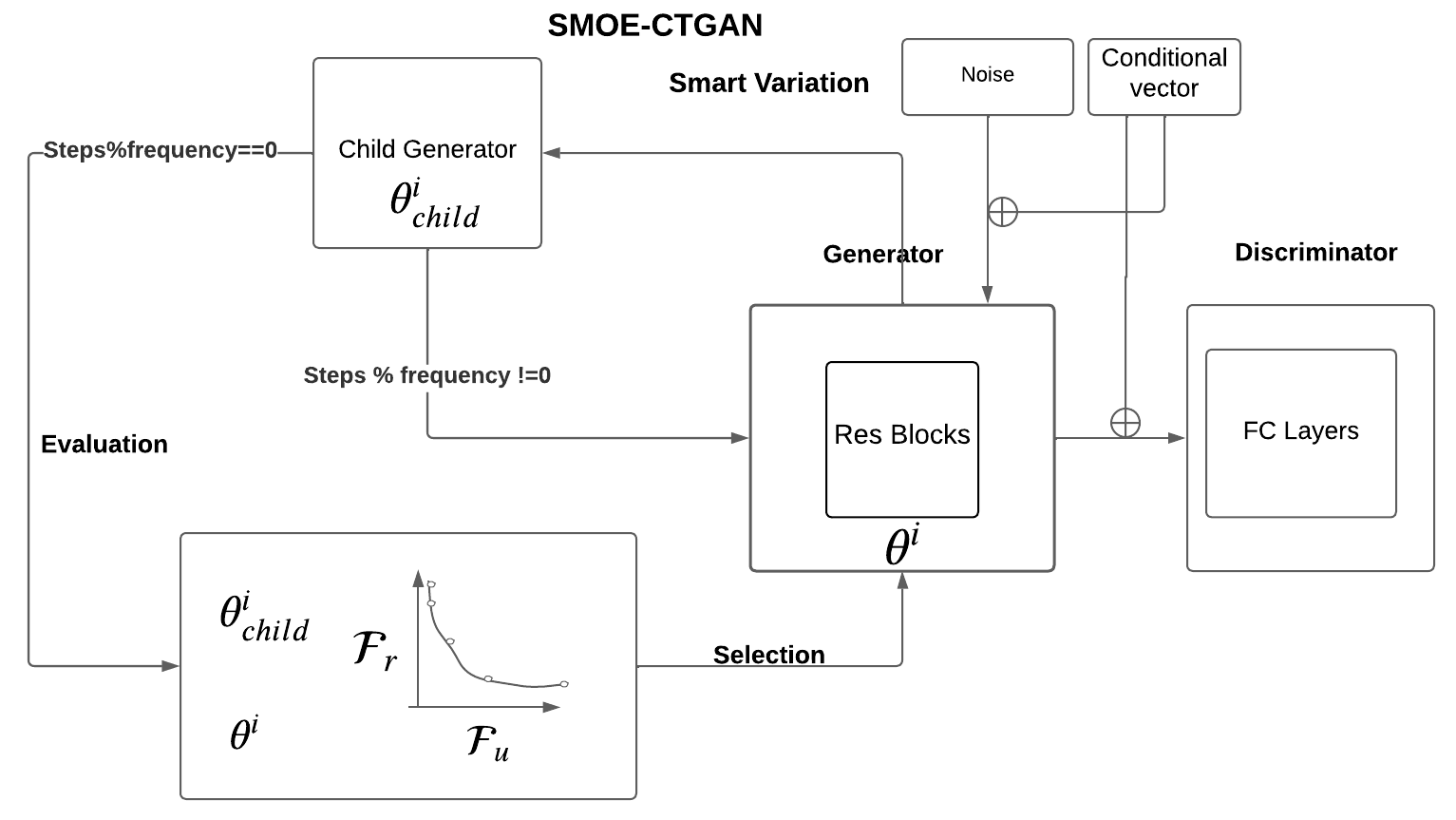
Synthetic data has a key role to play in data sharing by statistical agencies and other generators of statistical data products. Generative Adversarial Networks (GANs), typically applied to image synthesis, are also a promising method for tabular data synthesis. However, there are unique challenges in tabular data compared to images, eg tabular data may contain both continuous and discrete variables and conditional sampling, and, critically, the data should possess high utility and low disclosure risk (the risk of re-identifying a population unit or learning something new about them), providing an opportunity for multi-objective (MO) optimization. Inspired by MO GANs for images, this paper proposes a smart MO evolutionary conditional tabular GAN (SMOE-CTGAN). This approach models conditional synthetic data by applying conditional vectors in training, and uses concepts from MO optimisation to balance disclosure risk against utility. Our results indicate that SMOE-CTGAN is able to discover synthetic datasets with different risk and utility levels for multiple national census datasets. We also find a sweet spot in the early stage of training where a competitive utility and extremely low risk are achieved, by using an Improvement Score. The full code can be downloaded from https://github.com/HuskyNian/SMO_EGAN_pytorch.
4/17/2024