Mobile-Agent-v2: Mobile Device Operation Assistant with Effective Navigation via Multi-Agent Collaboration

0

Sign in to get full access
Overview
- The provided research paper discusses the development of a mobile device assistant called "Mobile-Agent-v2" that leverages multi-agent collaboration for effective navigation and operation.
- The paper explores techniques to enhance the capabilities of mobile device assistants, such as improving navigation, task completion, and overall user experience.
- Key focus areas include multi-agent collaboration, intelligent task planning, and multimodal interaction.
Plain English Explanation
The research paper introduces a new mobile device assistant called "Mobile-Agent-v2" that aims to improve the way people use and interact with their smartphones and other mobile devices. The main idea is to create a more intelligent and collaborative assistant that can help users navigate their device's features and complete tasks more effectively.
The researchers behind this project recognized that current mobile assistants can be limited in their capabilities, often struggling with complex tasks or failing to provide seamless and intuitive experiences. To address these limitations, they developed a system that uses a team of specialized "agents" working together to enhance the assistant's abilities.
These agents are essentially different software components that each focus on a specific aspect of the device's operation, such as understanding voice commands, analyzing visual information, or planning the best sequence of steps to complete a task. By having these agents collaborate and share information, the assistant can provide more comprehensive and intelligent support to the user.
For example, if a user asks the assistant to "find a good Italian restaurant near me," the different agents would work together to: [https://aimodels.fyi/papers/arxiv/mobile-agent-autonomous-multi-modal-mobile-device]
- Understand the voice command and extract the relevant information (location, cuisine type).
- Search through a database of nearby restaurants and identify the most suitable options.
- Analyze the user's preferences and past behavior to recommend the best restaurant.
- Provide step-by-step navigation instructions to guide the user to the selected restaurant.
This collaborative approach allows the assistant to handle more complex tasks and provide a more seamless and personalized experience for the user. The researchers also explored ways to make the interaction with the assistant more natural and intuitive, such as incorporating multimodal inputs (voice, touch, vision) and adapting the assistant's behavior based on the user's context and preferences.
Technical Explanation
The Mobile-Agent-v2 system is built upon a multi-agent architecture, where each agent specializes in a particular aspect of the mobile device's operation. These agents include:
- Voice Command Agent: Responsible for understanding and interpreting voice commands from the user.
- Vision Agent: Analyzes visual information, such as images or on-screen content, to extract relevant data.
- Task Planning Agent: Plans the optimal sequence of steps to complete a user's request, taking into account the capabilities of the other agents.
- Navigation Agent: Provides turn-by-turn navigation instructions and guidance to the user.
- User Preference Agent: Learns the user's preferences and behavior patterns to personalize the assistant's recommendations and actions.
The agents communicate and collaborate with each other through a central coordination module, which facilitates the exchange of information and the execution of tasks. This multi-agent approach allows the system to handle a wide range of user requests and adapt to changing circumstances more effectively than a traditional single-agent assistant.
The researchers also incorporated multimodal interaction capabilities, allowing the user to provide input through various channels, such as voice, touch, and vision. This enhances the flexibility and responsiveness of the assistant, enabling it to better understand the user's context and preferences.
To evaluate the performance of Mobile-Agent-v2, the researchers conducted a series of experiments comparing it to other state-of-the-art mobile assistants, such as PlanAgent and Octopus-v3. The results showed that Mobile-Agent-v2 outperformed these assistants in various metrics, including task completion rate, user satisfaction, and overall user experience.
Critical Analysis
The Mobile-Agent-v2 research presents a promising approach to enhancing the capabilities of mobile device assistants. By leveraging a multi-agent architecture and incorporating multimodal interaction, the system demonstrates significant improvements in areas such as task completion, navigation, and personalization.
However, the paper does not address some potential limitations or concerns that could be further explored. For instance, the authors do not discuss the scalability of the multi-agent system, particularly as the number of agents and the complexity of their interactions grow. Additionally, the paper does not provide a detailed analysis of the computational and memory requirements of the system, which could be important considerations for resource-constrained mobile devices.
Another area that could benefit from further investigation is the system's ability to handle unexpected or novel user requests. While the multi-agent approach likely enhances the assistant's flexibility, the paper does not explore how the system would respond to edge cases or situations that fall outside of its trained capabilities.
Furthermore, the paper does not discuss the potential privacy and security implications of a mobile assistant that collects and processes a significant amount of user data, such as location information, preferences, and browsing history. As these types of assistants become more prevalent, it will be crucial to address these concerns and ensure that user privacy is protected.
Conclusion
The Mobile-Agent-v2 research represents an important step forward in the development of more capable and intelligent mobile device assistants. By leveraging a multi-agent architecture and multimodal interaction, the system demonstrates significant improvements in areas such as task completion, navigation, and personalization.
This work has the potential to enhance the overall user experience and productivity of mobile device users, ultimately making their interactions with their devices more seamless and efficient. As the field of mobile assistants continues to evolve, further research and development in this direction could lead to even more advanced and user-friendly solutions, benefiting both individual users and the broader technology landscape.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Mobile-Agent-v2: Mobile Device Operation Assistant with Effective Navigation via Multi-Agent Collaboration
Junyang Wang, Haiyang Xu, Haitao Jia, Xi Zhang, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, Jitao Sang
Mobile device operation tasks are increasingly becoming a popular multi-modal AI application scenario. Current Multi-modal Large Language Models (MLLMs), constrained by their training data, lack the capability to function effectively as operation assistants. Instead, MLLM-based agents, which enhance capabilities through tool invocation, are gradually being applied to this scenario. However, the two major navigation challenges in mobile device operation tasks, task progress navigation and focus content navigation, are significantly complicated under the single-agent architecture of existing work. This is due to the overly long token sequences and the interleaved text-image data format, which limit performance. To address these navigation challenges effectively, we propose Mobile-Agent-v2, a multi-agent architecture for mobile device operation assistance. The architecture comprises three agents: planning agent, decision agent, and reflection agent. The planning agent generates task progress, making the navigation of history operations more efficient. To retain focus content, we design a memory unit that updates with task progress. Additionally, to correct erroneous operations, the reflection agent observes the outcomes of each operation and handles any mistakes accordingly. Experimental results indicate that Mobile-Agent-v2 achieves over a 30% improvement in task completion compared to the single-agent architecture of Mobile-Agent. The code is open-sourced at https://github.com/X-PLUG/MobileAgent.
Read more6/4/2024
0
Mobile-Agent: Autonomous Multi-Modal Mobile Device Agent with Visual Perception
Junyang Wang, Haiyang Xu, Jiabo Ye, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, Jitao Sang
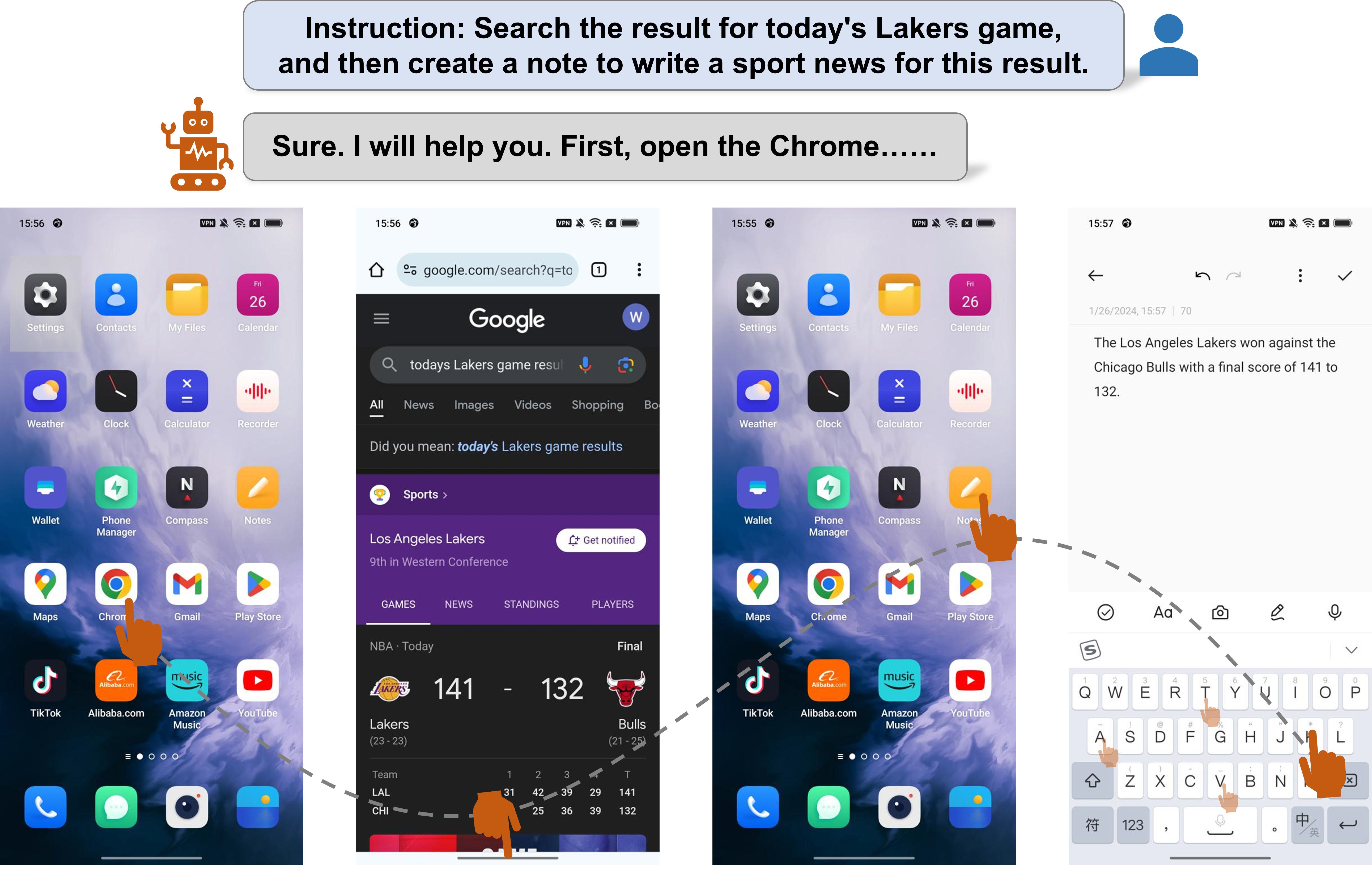
Mobile device agent based on Multimodal Large Language Models (MLLM) is becoming a popular application. In this paper, we introduce Mobile-Agent, an autonomous multi-modal mobile device agent. Mobile-Agent first leverages visual perception tools to accurately identify and locate both the visual and textual elements within the app's front-end interface. Based on the perceived vision context, it then autonomously plans and decomposes the complex operation task, and navigates the mobile Apps through operations step by step. Different from previous solutions that rely on XML files of Apps or mobile system metadata, Mobile-Agent allows for greater adaptability across diverse mobile operating environments in a vision-centric way, thereby eliminating the necessity for system-specific customizations. To assess the performance of Mobile-Agent, we introduced Mobile-Eval, a benchmark for evaluating mobile device operations. Based on Mobile-Eval, we conducted a comprehensive evaluation of Mobile-Agent. The experimental results indicate that Mobile-Agent achieved remarkable accuracy and completion rates. Even with challenging instructions, such as multi-app operations, Mobile-Agent can still complete the requirements. Code and model will be open-sourced at https://github.com/X-PLUG/MobileAgent.
Read more4/19/2024
0
AppAgent v2: Advanced Agent for Flexible Mobile Interactions
Yanda Li, Chi Zhang, Wanqi Yang, Bin Fu, Pei Cheng, Xin Chen, Ling Chen, Yunchao Wei
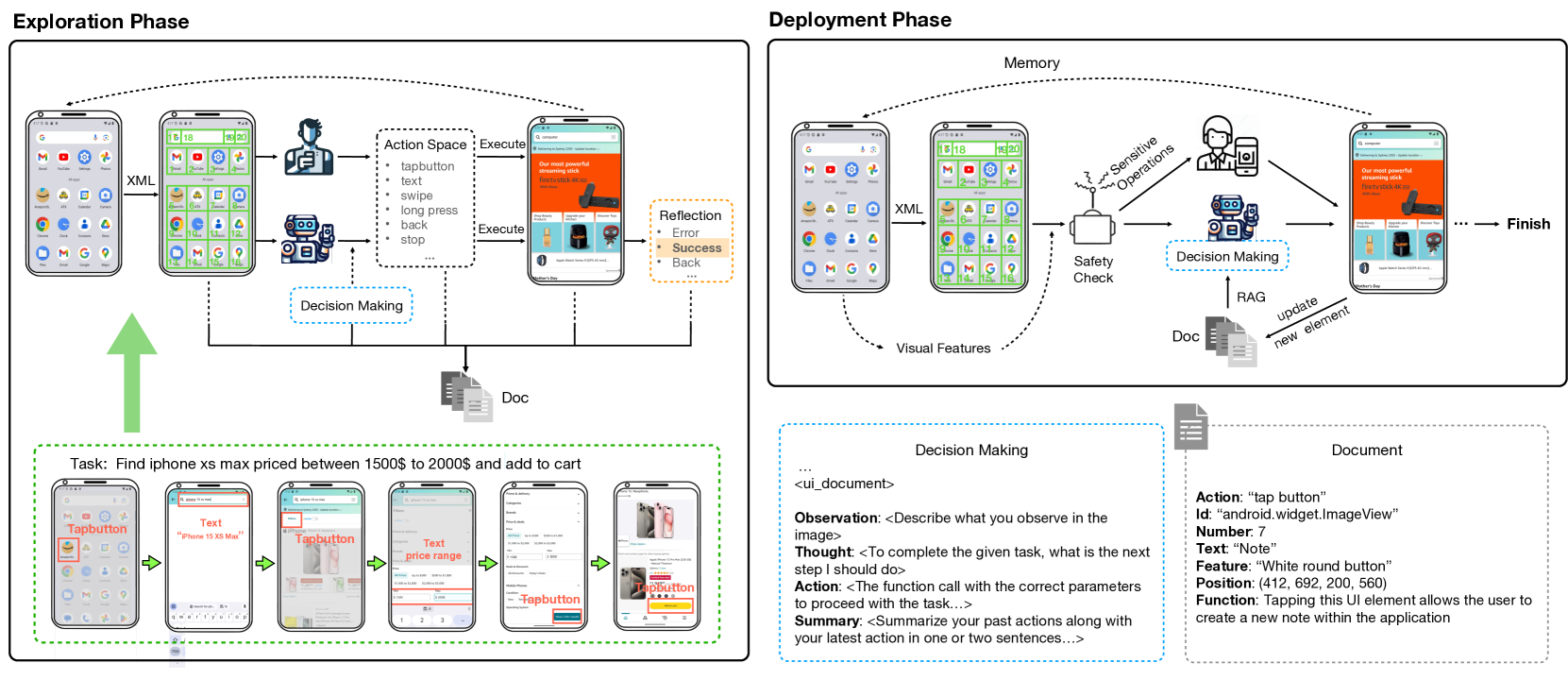
With the advancement of Multimodal Large Language Models (MLLM), LLM-driven visual agents are increasingly impacting software interfaces, particularly those with graphical user interfaces. This work introduces a novel LLM-based multimodal agent framework for mobile devices. This framework, capable of navigating mobile devices, emulates human-like interactions. Our agent constructs a flexible action space that enhances adaptability across various applications including parser, text and vision descriptions. The agent operates through two main phases: exploration and deployment. During the exploration phase, functionalities of user interface elements are documented either through agent-driven or manual explorations into a customized structured knowledge base. In the deployment phase, RAG technology enables efficient retrieval and update from this knowledge base, thereby empowering the agent to perform tasks effectively and accurately. This includes performing complex, multi-step operations across various applications, thereby demonstrating the framework's adaptability and precision in handling customized task workflows. Our experimental results across various benchmarks demonstrate the framework's superior performance, confirming its effectiveness in real-world scenarios. Our code will be open source soon.
Read more8/26/2024

0
MobileExperts: A Dynamic Tool-Enabled Agent Team in Mobile Devices
Jiayi Zhang, Chuang Zhao, Yihan Zhao, Zhaoyang Yu, Ming He, Jianping Fan
The attainment of autonomous operations in mobile computing devices has consistently been a goal of human pursuit. With the development of Large Language Models (LLMs) and Visual Language Models (VLMs), this aspiration is progressively turning into reality. While contemporary research has explored automation of simple tasks on mobile devices via VLMs, there remains significant room for improvement in handling complex tasks and reducing high reasoning costs. In this paper, we introduce MobileExperts, which for the first time introduces tool formulation and multi-agent collaboration to address the aforementioned challenges. More specifically, MobileExperts dynamically assembles teams based on the alignment of agent portraits with the human requirements. Following this, each agent embarks on an independent exploration phase, formulating its tools to evolve into an expert. Lastly, we develop a dual-layer planning mechanism to establish coordinate collaboration among experts. To validate our effectiveness, we design a new benchmark of hierarchical intelligence levels, offering insights into algorithm's capability to address tasks across a spectrum of complexity. Experimental results demonstrate that MobileExperts performs better on all intelligence levels and achieves ~ 22% reduction in reasoning costs, thus verifying the superiority of our design.
Read more7/8/2024