AppAgent v2: Advanced Agent for Flexible Mobile Interactions

0
Sign in to get full access
Overview
- This paper introduces AppAgent v2, an advanced agent for flexible mobile interactions.
- AppAgent v2 is designed to assist users with a wide range of tasks on their mobile devices.
- The agent leverages large language models and multimodal capabilities to provide intelligent and adaptable assistance.
Plain English Explanation
AppAgent v2: Advanced Agent for Flexible Mobile Interactions presents an intelligent assistant that can help users with various tasks on their smartphones and tablets. Rather than being limited to a specific set of commands or features, this agent uses large language models and the ability to process different types of information, like text, images, and voice, to understand and respond to a wide range of user needs.
The key idea is to create a more flexible and adaptable assistant that can handle a diverse set of user requests, from scheduling appointments and setting reminders to providing recommendations and even creative assistance. By leveraging advanced AI techniques, the researchers aim to develop an agent that can understand the user's intent and context, and then respond in a way that is tailored to the individual's needs.
This could be particularly useful for mobile device users who want a single, capable assistant to handle a variety of tasks, rather than relying on a collection of specialized apps or voice assistants. The multimodal capabilities of AppAgent v2 also allow it to work with different types of input and output, making it more accessible and versatile.
Technical Explanation
AppAgent v2: Advanced Agent for Flexible Mobile Interactions presents a novel agent architecture designed to provide intelligent and adaptable assistance on mobile devices. The key innovations include:
-
Multimodal Interaction: AppAgent v2 can process and generate a variety of input and output modalities, such as text, voice, images, and even sketches. This allows the agent to understand and respond to user requests in a more natural and seamless way.
-
Large Language Model Integration: The agent leverages state-of-the-art large language models, which provide robust natural language understanding and generation capabilities. This enables the agent to comprehend complex queries and formulate relevant and coherent responses.
-
Contextual Awareness: AppAgent v2 maintains an understanding of the user's current context, such as their location, calendar, and device usage patterns. This contextual information is used to tailor the agent's responses and recommendations to the user's specific needs.
-
Task-Agnostic Design: Rather than being limited to a predefined set of tasks, the agent is designed to be flexible and adaptable. It can handle a wide range of user requests, from scheduling and productivity to creative tasks and personal assistance.
The researchers evaluated AppAgent v2 through a series of user studies and found that it was able to outperform traditional virtual assistants in terms of user satisfaction, task completion, and overall usability. The agent's multimodal capabilities and contextual awareness were particularly appreciated by participants.
Critical Analysis
The paper provides a compelling vision for a more advanced and versatile mobile assistant, but it also acknowledges several limitations and areas for future research:
-
Ethical Considerations: As with any powerful AI system, there are ethical concerns around privacy, bias, and the potential for misuse that need to be carefully addressed.
-
Computational Efficiency: Integrating large language models and multimodal processing can be computationally intensive, which may present challenges for real-time performance on mobile devices.
-
Personalization and Adaptation: While the agent's contextual awareness is a strength, further research is needed to ensure that it can truly adapt to the individual user's preferences and habits over time.
-
Multimodal Integration: The paper focuses on the individual modalities, but more work is needed to seamlessly combine different input and output channels for a truly seamless user experience.
Overall, the research presented in AppAgent v2: Advanced Agent for Flexible Mobile Interactions represents an important step forward in the development of intelligent and adaptable mobile assistants. By addressing the limitations and continuing to refine the technology, the researchers have the potential to create a transformative tool for mobile device users.
Conclusion
AppAgent v2: Advanced Agent for Flexible Mobile Interactions introduces a groundbreaking mobile agent that leverages large language models and multimodal capabilities to provide intelligent and adaptable assistance. This research represents a significant advancement in the field of virtual assistants, with the potential to revolutionize how users interact with their mobile devices.
By offering a flexible and context-aware agent that can handle a wide range of tasks, the researchers have developed a more personalized and empowering solution for mobile device users. As the technology continues to evolve and address the identified limitations, the impact of AppAgent v2 could extend far beyond the realm of mobile computing, with implications for how we interact with and rely on intelligent assistants in our daily lives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AppAgent v2: Advanced Agent for Flexible Mobile Interactions
Yanda Li, Chi Zhang, Wanqi Yang, Bin Fu, Pei Cheng, Xin Chen, Ling Chen, Yunchao Wei
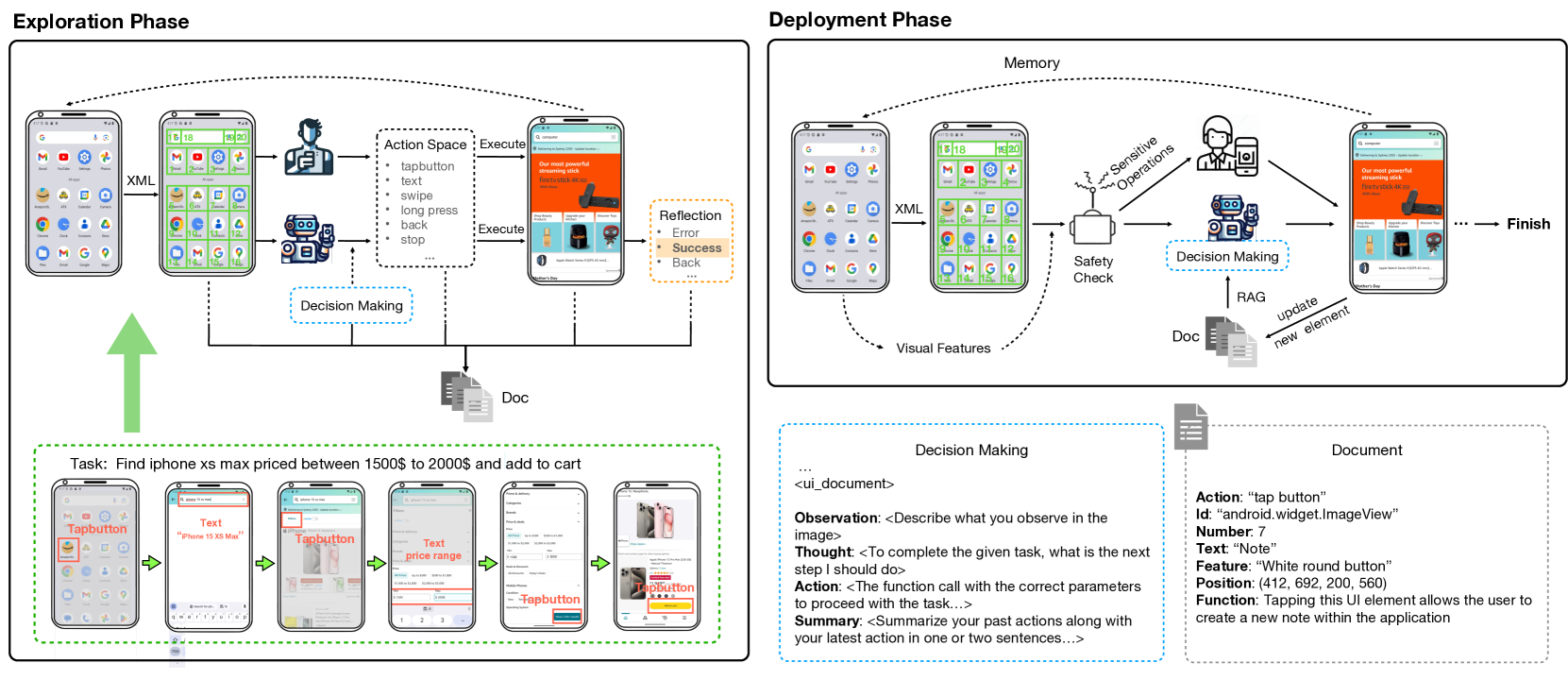
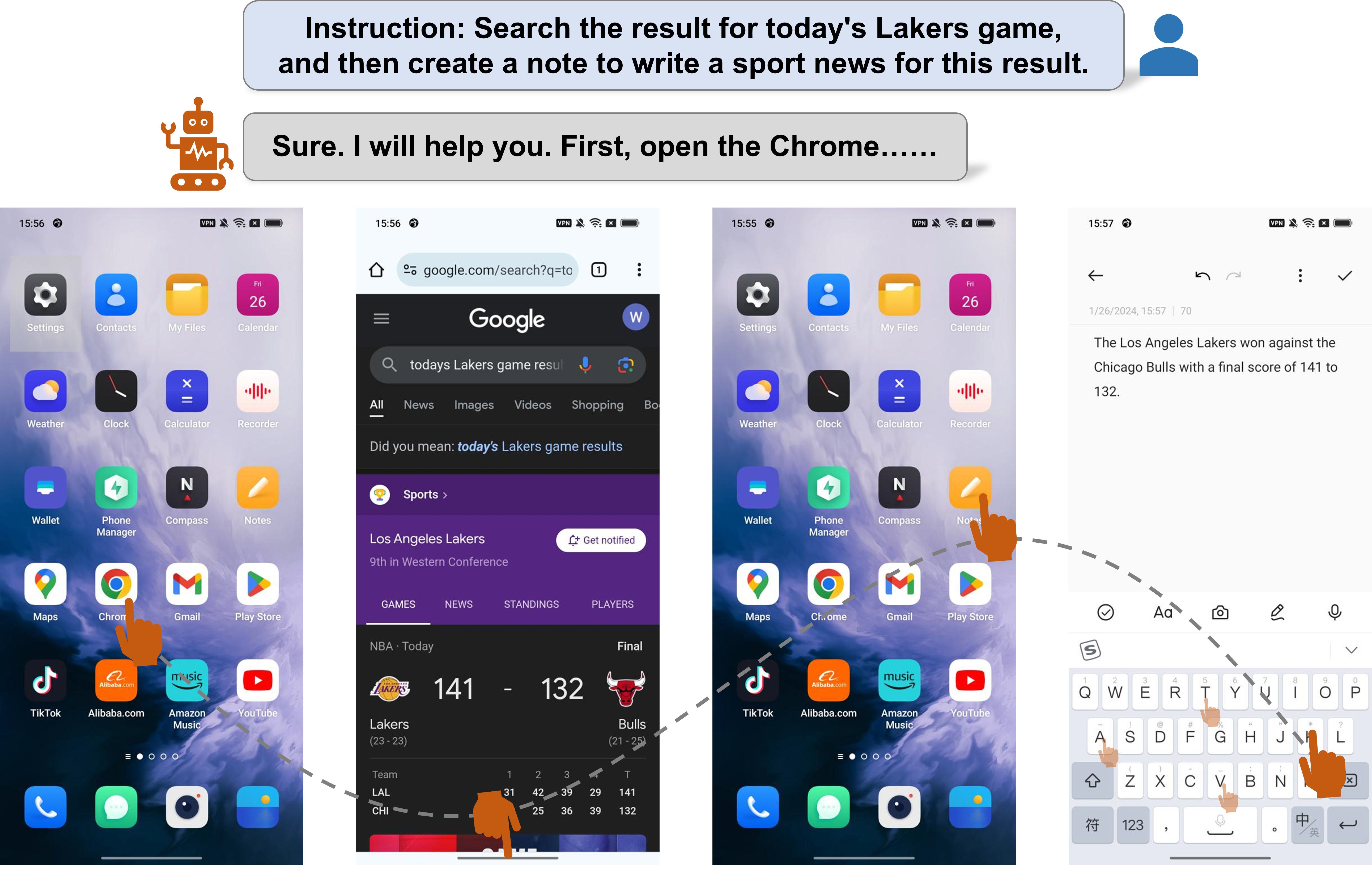
With the advancement of Multimodal Large Language Models (MLLM), LLM-driven visual agents are increasingly impacting software interfaces, particularly those with graphical user interfaces. This work introduces a novel LLM-based multimodal agent framework for mobile devices. This framework, capable of navigating mobile devices, emulates human-like interactions. Our agent constructs a flexible action space that enhances adaptability across various applications including parser, text and vision descriptions. The agent operates through two main phases: exploration and deployment. During the exploration phase, functionalities of user interface elements are documented either through agent-driven or manual explorations into a customized structured knowledge base. In the deployment phase, RAG technology enables efficient retrieval and update from this knowledge base, thereby empowering the agent to perform tasks effectively and accurately. This includes performing complex, multi-step operations across various applications, thereby demonstrating the framework's adaptability and precision in handling customized task workflows. Our experimental results across various benchmarks demonstrate the framework's superior performance, confirming its effectiveness in real-world scenarios. Our code will be open source soon.
Read more8/26/2024
0
Mobile-Agent: Autonomous Multi-Modal Mobile Device Agent with Visual Perception
Junyang Wang, Haiyang Xu, Jiabo Ye, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, Jitao Sang
Mobile device agent based on Multimodal Large Language Models (MLLM) is becoming a popular application. In this paper, we introduce Mobile-Agent, an autonomous multi-modal mobile device agent. Mobile-Agent first leverages visual perception tools to accurately identify and locate both the visual and textual elements within the app's front-end interface. Based on the perceived vision context, it then autonomously plans and decomposes the complex operation task, and navigates the mobile Apps through operations step by step. Different from previous solutions that rely on XML files of Apps or mobile system metadata, Mobile-Agent allows for greater adaptability across diverse mobile operating environments in a vision-centric way, thereby eliminating the necessity for system-specific customizations. To assess the performance of Mobile-Agent, we introduced Mobile-Eval, a benchmark for evaluating mobile device operations. Based on Mobile-Eval, we conducted a comprehensive evaluation of Mobile-Agent. The experimental results indicate that Mobile-Agent achieved remarkable accuracy and completion rates. Even with challenging instructions, such as multi-app operations, Mobile-Agent can still complete the requirements. Code and model will be open-sourced at https://github.com/X-PLUG/MobileAgent.
Read more4/19/2024

0
Mobile-Agent-v2: Mobile Device Operation Assistant with Effective Navigation via Multi-Agent Collaboration
Junyang Wang, Haiyang Xu, Haitao Jia, Xi Zhang, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, Jitao Sang
Mobile device operation tasks are increasingly becoming a popular multi-modal AI application scenario. Current Multi-modal Large Language Models (MLLMs), constrained by their training data, lack the capability to function effectively as operation assistants. Instead, MLLM-based agents, which enhance capabilities through tool invocation, are gradually being applied to this scenario. However, the two major navigation challenges in mobile device operation tasks, task progress navigation and focus content navigation, are significantly complicated under the single-agent architecture of existing work. This is due to the overly long token sequences and the interleaved text-image data format, which limit performance. To address these navigation challenges effectively, we propose Mobile-Agent-v2, a multi-agent architecture for mobile device operation assistance. The architecture comprises three agents: planning agent, decision agent, and reflection agent. The planning agent generates task progress, making the navigation of history operations more efficient. To retain focus content, we design a memory unit that updates with task progress. Additionally, to correct erroneous operations, the reflection agent observes the outcomes of each operation and handles any mistakes accordingly. Experimental results indicate that Mobile-Agent-v2 achieves over a 30% improvement in task completion compared to the single-agent architecture of Mobile-Agent. The code is open-sourced at https://github.com/X-PLUG/MobileAgent.
Read more6/4/2024
🚀
0
CoCo-Agent: A Comprehensive Cognitive MLLM Agent for Smartphone GUI Automation
Xinbei Ma, Zhuosheng Zhang, Hai Zhao
Multimodal large language models (MLLMs) have shown remarkable potential as human-like autonomous language agents to interact with real-world environments, especially for graphical user interface (GUI) automation. However, those GUI agents require comprehensive cognition ability including exhaustive perception and reliable action response. We propose a Comprehensive Cognitive LLM Agent, CoCo-Agent, with two novel approaches, comprehensive environment perception (CEP) and conditional action prediction (CAP), to systematically improve the GUI automation performance. First, CEP facilitates the GUI perception through different aspects and granularity, including screenshots and complementary detailed layouts for the visual channel and historical actions for the textual channel. Second, CAP decomposes the action prediction into sub-problems: action type prediction and action target conditioned on the action type. With our technical design, our agent achieves new state-of-the-art performance on AITW and META-GUI benchmarks, showing promising abilities in realistic scenarios. Code is available at https://github.com/xbmxb/CoCo-Agent.
Read more6/4/2024