Mobile-Bench: An Evaluation Benchmark for LLM-based Mobile Agents

0

Sign in to get full access
Overview
• This paper introduces Mobile-Bench, a new evaluation benchmark designed to assess the performance of large language model (LLM)-based mobile agents.
• It also discusses related work, including Mobile-AIBench, Mobile-Env, CityBench, and Benchmarking Mobile Device Control Agents.
Plain English Explanation
The researchers have developed a new tool called Mobile-Bench to evaluate the performance of AI language models when used as virtual assistants on mobile devices. This is important because these AI assistants are becoming more common on our phones and tablets, but we need a way to test how well they can handle different tasks and scenarios.
Mobile-Bench provides a set of standardized tests or "benchmarks" that measure things like the AI's ability to understand natural language, provide helpful responses, and complete various mobile-specific tasks. By running these tests, researchers and developers can compare the capabilities of different AI language models and identify areas for improvement.
The paper also discusses some related tools and benchmarks that have been created for similar purposes, such as evaluating AI performance on mobile devices or in simulated urban environments. These provide useful context and comparisons for the Mobile-Bench approach.
Technical Explanation
The Mobile-Bench framework consists of a set of task-oriented evaluation scenarios designed to assess the capabilities of LLM-based mobile agents. These scenarios cover common mobile user interactions, such as scheduling appointments, setting reminders, and managing to-do lists.
The benchmark is designed to be efficient and user-friendly, allowing for rapid, repeatable testing of LLM performance on mobile devices. It includes both automatic and human-evaluation components, enabling comprehensive assessment of the agents' language understanding, task completion, and user experience.
The authors also discuss related work, including Mobile-AIBench, which focuses on benchmarking LLMs and language models for mobile device use cases, and Mobile-Env, a framework for building qualified evaluation benchmarks for LLMs on mobile platforms. Additionally, they compare Mobile-Bench to CityBench, a benchmark for evaluating the capabilities of large language models in simulated urban environments, and Benchmarking Mobile Device Control Agents, which assesses the performance of mobile device control agents across diverse scenarios.
Critical Analysis
The authors of the paper acknowledge that the Mobile-Bench benchmark is limited in scope, focusing primarily on common mobile user interactions. They suggest that future work could expand the benchmark to include a wider range of tasks and scenarios, potentially integrating with other evaluation frameworks for a more comprehensive assessment of LLM-based mobile agents.
Additionally, while the paper presents the Mobile-Bench framework and its initial evaluation results, it does not provide a detailed analysis of the performance of specific LLM models or how they compare to one another. Further research could delve deeper into the comparative analysis of different LLM-based mobile agents to provide more insights for developers and users.
Conclusion
The Mobile-Bench benchmark introduced in this paper represents a valuable contribution to the field of mobile AI agent evaluation. By providing a standardized, user-friendly framework for assessing the capabilities of LLM-based mobile agents, the researchers have created a tool that can help drive the development and improvement of these increasingly important technologies. As AI assistants become more prevalent on our mobile devices, tools like Mobile-Bench will be crucial for ensuring these agents can reliably and effectively assist users in their everyday tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Mobile-Bench: An Evaluation Benchmark for LLM-based Mobile Agents
Shihan Deng, Weikai Xu, Hongda Sun, Wei Liu, Tao Tan, Jianfeng Liu, Ang Li, Jian Luan, Bin Wang, Rui Yan, Shuo Shang
With the remarkable advancements of large language models (LLMs), LLM-based agents have become a research hotspot in human-computer interaction. However, there is a scarcity of benchmarks available for LLM-based mobile agents. Benchmarking these agents generally faces three main challenges: (1) The inefficiency of UI-only operations imposes limitations to task evaluation. (2) Specific instructions within a singular application lack adequacy for assessing the multi-dimensional reasoning and decision-making capacities of LLM mobile agents. (3) Current evaluation metrics are insufficient to accurately assess the process of sequential actions. To this end, we propose Mobile-Bench, a novel benchmark for evaluating the capabilities of LLM-based mobile agents. First, we expand conventional UI operations by incorporating 103 collected APIs to accelerate the efficiency of task completion. Subsequently, we collect evaluation data by combining real user queries with augmentation from LLMs. To better evaluate different levels of planning capabilities for mobile agents, our data is categorized into three distinct groups: SAST, SAMT, and MAMT, reflecting varying levels of task complexity. Mobile-Bench comprises 832 data entries, with more than 200 tasks specifically designed to evaluate multi-APP collaboration scenarios. Furthermore, we introduce a more accurate evaluation metric, named CheckPoint, to assess whether LLM-based mobile agents reach essential points during their planning and reasoning steps.
Read more7/2/2024
0
MobileAgentBench: An Efficient and User-Friendly Benchmark for Mobile LLM Agents
Luyuan Wang, Yongyu Deng, Yiwei Zha, Guodong Mao, Qinmin Wang, Tianchen Min, Wei Chen, Shoufa Chen
Large language model (LLM)-based mobile agents are increasingly popular due to their capability to interact directly with mobile phone Graphic User Interfaces (GUIs) and their potential to autonomously manage daily tasks. Despite their promising prospects in both academic and industrial sectors, little research has focused on benchmarking the performance of existing mobile agents, due to the inexhaustible states of apps and the vague definition of feasible action sequences. To address this challenge, we propose an efficient and user-friendly benchmark, MobileAgentBench, designed to alleviate the burden of extensive manual testing. We initially define 100 tasks across 10 open-source apps, categorized by multiple levels of difficulty. Subsequently, we evaluate several existing mobile agents, including AppAgent and MobileAgent, to thoroughly and systematically compare their performance. All materials are accessible on our project webpage: https://MobileAgentBench.github.io, contributing to the advancement of both academic and industrial fields.
Read more6/13/2024
0
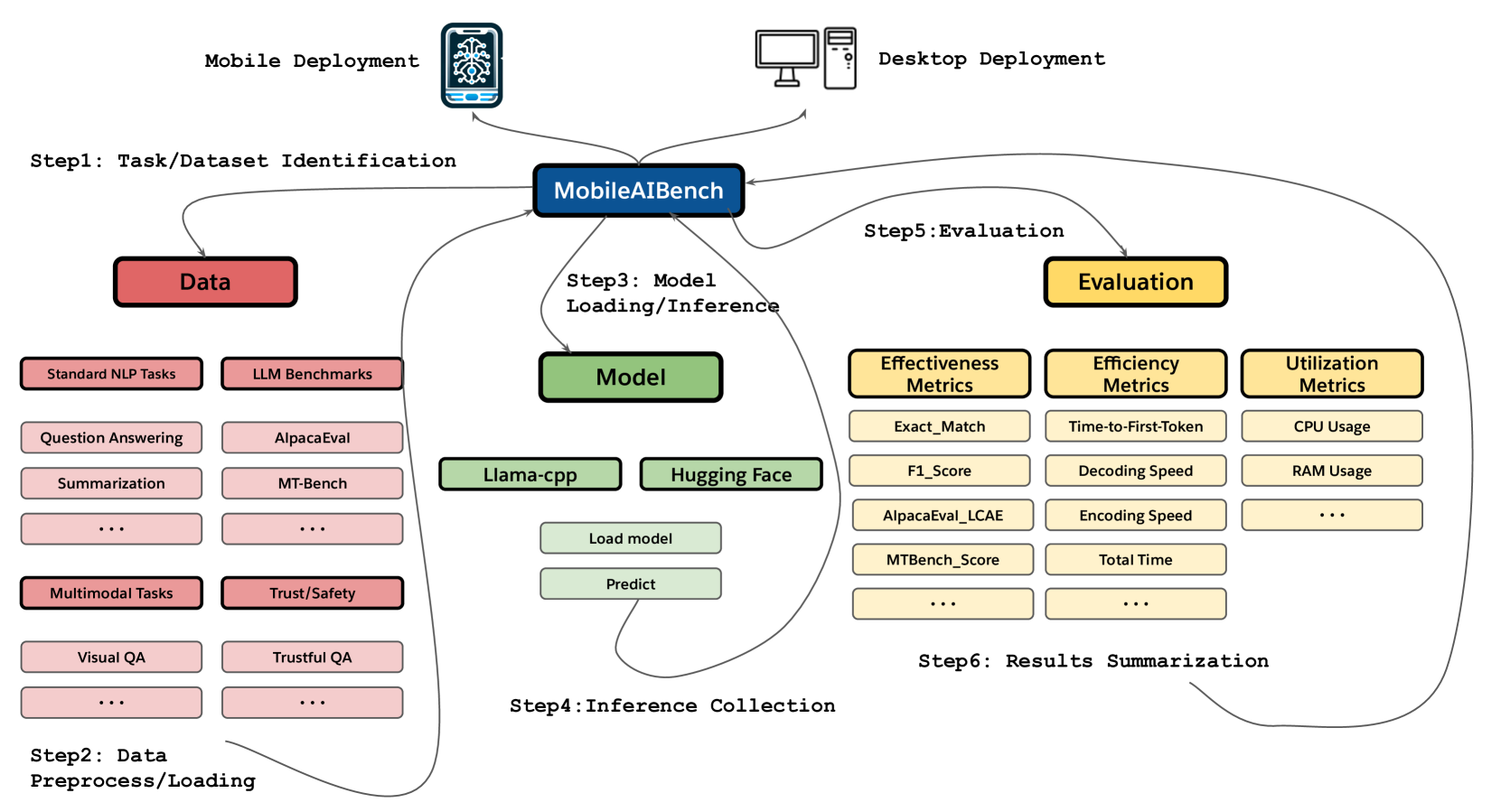
MobileAIBench: Benchmarking LLMs and LMMs for On-Device Use Cases
Rithesh Murthy, Liangwei Yang, Juntao Tan, Tulika Manoj Awalgaonkar, Yilun Zhou, Shelby Heinecke, Sachin Desai, Jason Wu, Ran Xu, Sarah Tan, Jianguo Zhang, Zhiwei Liu, Shirley Kokane, Zuxin Liu, Ming Zhu, Huan Wang, Caiming Xiong, Silvio Savarese
The deployment of Large Language Models (LLMs) and Large Multimodal Models (LMMs) on mobile devices has gained significant attention due to the benefits of enhanced privacy, stability, and personalization. However, the hardware constraints of mobile devices necessitate the use of models with fewer parameters and model compression techniques like quantization. Currently, there is limited understanding of quantization's impact on various task performances, including LLM tasks, LMM tasks, and, critically, trust and safety. There is a lack of adequate tools for systematically testing these models on mobile devices. To address these gaps, we introduce MobileAIBench, a comprehensive benchmarking framework for evaluating mobile-optimized LLMs and LMMs. MobileAIBench assesses models across different sizes, quantization levels, and tasks, measuring latency and resource consumption on real devices. Our two-part open-source framework includes a library for running evaluations on desktops and an iOS app for on-device latency and hardware utilization measurements. Our thorough analysis aims to accelerate mobile AI research and deployment by providing insights into the performance and feasibility of deploying LLMs and LMMs on mobile platforms.
Read more6/18/2024
🔄
0
Mobile-Env: Building Qualified Evaluation Benchmarks for LLM-GUI Interaction
Danyang Zhang, Zhennan Shen, Rui Xie, Situo Zhang, Tianbao Xie, Zihan Zhao, Siyuan Chen, Lu Chen, Hongshen Xu, Ruisheng Cao, Kai Yu
The Graphical User Interface (GUI) is pivotal for human interaction with the digital world, enabling efficient device control and the completion of complex tasks. Recent progress in Large Language Models (LLMs) and Vision Language Models (VLMs) offers the chance to create advanced GUI agents. To ensure their effectiveness, there's a pressing need for qualified benchmarks that provide trustworthy and reproducible evaluations -- a challenge current benchmarks often fail to address. To tackle this issue, we introduce Mobile-Env, a comprehensive toolkit tailored for creating GUI benchmarks in the Android mobile environment. Mobile-Env offers an isolated and controllable setting for reliable evaluations, and accommodates intermediate instructions and rewards to reflect real-world usage more naturally. Utilizing Mobile-Env, we collect an open-world task set across various real-world apps and a fixed world set, WikiHow, which captures a significant amount of dynamic online contents for fully controllable and reproducible evaluation. We conduct comprehensive evaluations of LLM agents using these benchmarks. Our findings reveal that even advanced models (e.g., GPT-4V and LLaMA-3) struggle with tasks that are relatively simple for humans. This highlights a crucial gap in current models and underscores the importance of developing more capable foundation models and more effective GUI agent frameworks.
Read more6/14/2024