CityBench: Evaluating the Capabilities of Large Language Model as World Model
2406.13945
0
0

Abstract
Large language models (LLMs) with powerful generalization ability has been widely used in many domains. A systematic and reliable evaluation of LLMs is a crucial step in their development and applications, especially for specific professional fields. In the urban domain, there have been some early explorations about the usability of LLMs, but a systematic and scalable evaluation benchmark is still lacking. The challenge in constructing a systematic evaluation benchmark for the urban domain lies in the diversity of data and scenarios, as well as the complex and dynamic nature of cities. In this paper, we propose CityBench, an interactive simulator based evaluation platform, as the first systematic evaluation benchmark for the capability of LLMs for urban domain. First, we build CitySim to integrate the multi-source data and simulate fine-grained urban dynamics. Based on CitySim, we design 7 tasks in 2 categories of perception-understanding and decision-making group to evaluate the capability of LLMs as city-scale world model for urban domain. Due to the flexibility and ease-of-use of CitySim, our evaluation platform CityBench can be easily extended to any city in the world. We evaluate 13 well-known LLMs including open source LLMs and commercial LLMs in 13 cities around the world. Extensive experiments demonstrate the scalability and effectiveness of proposed CityBench and shed lights for the future development of LLMs in urban domain. The dataset, benchmark and source codes are openly accessible to the research community via https://github.com/tsinghua-fib-lab/CityBench
Create account to get full access
Overview
• The paper "CityBench: Evaluating the Capabilities of Large Language Model as World Model" presents a new evaluation benchmark called CityBench that aims to assess the abilities of large language models (LLMs) to reason about the physical and social aspects of an urban environment.
• The authors argue that while LLMs have shown impressive capabilities in various tasks, their ability to serve as "world models" that can accurately represent and reason about the real world remains largely unexplored.
• CityBench consists of a diverse set of tasks that cover different aspects of urban environments, including spatial reasoning, social interactions, and temporal dynamics, allowing for a comprehensive evaluation of LLMs' capabilities as world models.
Plain English Explanation
The paper introduces a new way to test the abilities of large language models (LLMs) - computer programs that can understand and generate human-like text. The authors argue that while LLMs have become very good at tasks like answering questions and generating text, we don't really know how well they can understand and reason about the real world.
To address this, the researchers created a benchmark called CityBench, which is a set of tests that assess how well LLMs can represent and reason about the physical and social aspects of a city. The tests cover things like:
- Spatial reasoning: Can the LLM understand the layout of a city and how different locations are related?
- Social interactions: Can the LLM reason about how people might interact in different situations?
- Temporal dynamics: Can the LLM understand how a city changes over time?
By testing LLMs on this diverse set of tasks, the researchers hope to get a better sense of whether these models can truly serve as "world models" - representations of the real world that can be used for reasoning and decision-making.
Technical Explanation
The paper presents a new benchmark called CityBench that aims to evaluate the capabilities of large language models (LLMs) as "world models" - representations of the real world that can be used for reasoning and decision-making.
The authors argue that while LLMs have shown impressive performance on a wide range of language tasks, their ability to accurately model and reason about the physical and social aspects of the real world remains largely unexplored. CityBench is designed to address this gap by providing a diverse set of tasks that cover different aspects of urban environments.
The CityBench tasks include:
- Spatial reasoning tasks that assess the LLM's understanding of the spatial layout and relationships within a city.
- Social interaction tasks that evaluate the LLM's ability to reason about human behavior and social dynamics in an urban context.
- Temporal reasoning tasks that test the LLM's capacity to understand how a city changes over time.
The authors developed a diverse set of test cases within each task category, drawing on real-world data sources to create realistic scenarios that challenge the LLMs' world modeling capabilities.
Critical Analysis
The CityBench benchmark represents a valuable contribution to the field of large language model evaluation, as it goes beyond traditional language tasks to assess the models' ability to reason about the physical and social aspects of the real world.
However, the authors acknowledge several limitations and areas for further research:
- The current CityBench tasks are focused on urban environments, and the authors suggest expanding the benchmark to cover other real-world domains, such as natural environments or clinical settings.
- The paper does not provide a detailed analysis of the performance of specific LLM architectures on the CityBench tasks, which would be valuable for understanding the current state of the art and guiding future model development.
- The authors note that the CityBench tasks require a combination of language understanding, commonsense reasoning, and world knowledge, and further research is needed to disentangle the specific capabilities that contribute to successful performance.
Overall, the CityBench benchmark represents an important step towards a more comprehensive evaluation of large language models as world models, and the authors' call for further research and expansion of the benchmark is well-justified.
Conclusion
The "CityBench: Evaluating the Capabilities of Large Language Model as World Model" paper presents a novel evaluation benchmark that aims to assess the abilities of large language models to serve as accurate representations of the real world. By testing LLMs on a diverse set of tasks covering spatial reasoning, social interactions, and temporal dynamics in an urban environment, the authors hope to gain insights into the models' capacities as "world models" that can be used for reasoning and decision-making.
While the current CityBench focuses on urban environments, the authors suggest that expanding the benchmark to other real-world domains could lead to a more comprehensive understanding of LLMs' world modeling capabilities. Additionally, further research is needed to disentangle the specific factors contributing to successful performance on the CityBench tasks, which could inform the development of more effective LLM architectures and training approaches.
Overall, the CityBench benchmark represents an important step forward in the ongoing efforts to evaluate the capabilities of large language models and their potential as powerful tools for understanding and interacting with the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A User-Centric Benchmark for Evaluating Large Language Models
Jiayin Wang, Fengran Mo, Weizhi Ma, Peijie Sun, Min Zhang, Jian-Yun Nie
0
0
Large Language Models (LLMs) are essential tools to collaborate with users on different tasks. Evaluating their performance to serve users' needs in real-world scenarios is important. While many benchmarks have been created, they mainly focus on specific predefined model abilities. Few have covered the intended utilization of LLMs by real users. To address this oversight, we propose benchmarking LLMs from a user perspective in both dataset construction and evaluation designs. We first collect 1846 real-world use cases with 15 LLMs from a user study with 712 participants from 23 countries. These self-reported cases form the User Reported Scenarios(URS) dataset with a categorization of 7 user intents. Secondly, on this authentic multi-cultural dataset, we benchmark 10 LLM services on their efficacy in satisfying user needs. Thirdly, we show that our benchmark scores align well with user-reported experience in LLM interactions across diverse intents, both of which emphasize the overlook of subjective scenarios. In conclusion, our study proposes to benchmark LLMs from a user-centric perspective, aiming to facilitate evaluations that better reflect real user needs. The benchmark dataset and code are available at https://github.com/Alice1998/URS.
4/24/2024
💬
CityGPT: Empowering Urban Spatial Cognition of Large Language Models
Jie Feng, Yuwei Du, Tianhui Liu, Siqi Guo, Yuming Lin, Yong Li
0
0
Large language models(LLMs) with powerful language generation and reasoning capabilities have already achieved success in many domains, e.g., math and code generation. However, due to the lacking of physical world's corpus and knowledge during training, they usually fail to solve many real-life tasks in the urban space. In this paper, we propose CityGPT, a systematic framework for enhancing the capability of LLMs on understanding urban space and solving the related urban tasks by building a city-scale world model in the model. First, we construct a diverse instruction tuning dataset CityInstruction for injecting urban knowledge and enhancing spatial reasoning capability effectively. By using a mixture of CityInstruction and general instruction data, we fine-tune various LLMs (e.g., ChatGLM3-6B, Qwen1.5 and LLama3 series) to enhance their capability without sacrificing general abilities. To further validate the effectiveness of proposed methods, we construct a comprehensive benchmark CityEval to evaluate the capability of LLMs on diverse urban scenarios and problems. Extensive evaluation results demonstrate that small LLMs trained with CityInstruction can achieve competitive performance with commercial LLMs in the comprehensive evaluation of CityEval. The source codes are openly accessible to the research community via https://github.com/tsinghua-fib-lab/CityGPT.
6/21/2024
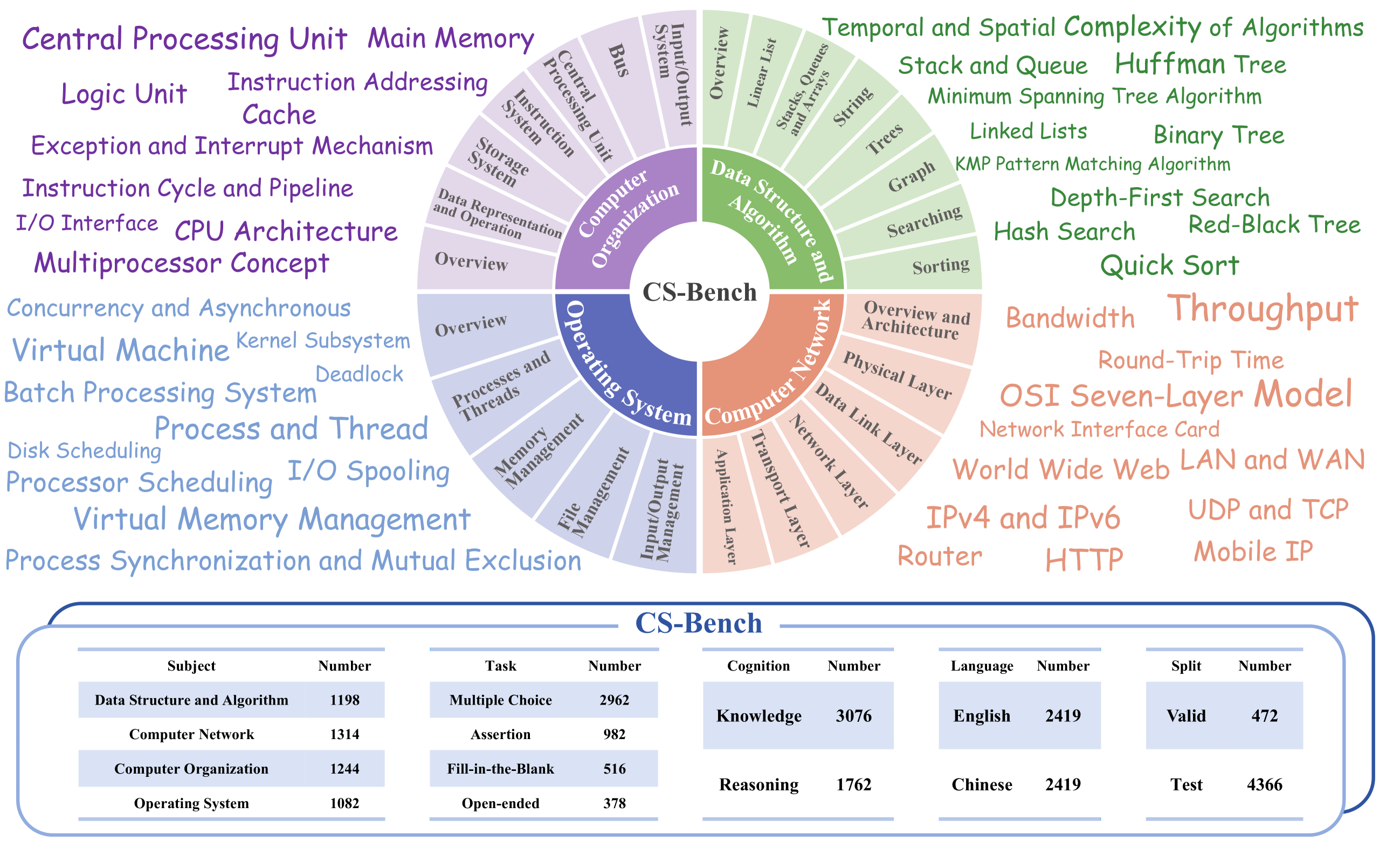
CS-Bench: A Comprehensive Benchmark for Large Language Models towards Computer Science Mastery
Xiaoshuai Song, Muxi Diao, Guanting Dong, Zhengyang Wang, Yujia Fu, Runqi Qiao, Zhexu Wang, Dayuan Fu, Huangxuan Wu, Bin Liang, Weihao Zeng, Yejie Wang, Zhuoma GongQue, Jianing Yu, Qiuna Tan, Weiran Xu
0
0
Computer Science (CS) stands as a testament to the intricacies of human intelligence, profoundly advancing the development of artificial intelligence and modern society. However, the current community of large language models (LLMs) overly focuses on benchmarks for analyzing specific foundational skills (e.g. mathematics and code generation), neglecting an all-round evaluation of the computer science field. To bridge this gap, we introduce CS-Bench, the first bilingual (Chinese-English) benchmark dedicated to evaluating the performance of LLMs in computer science. CS-Bench comprises approximately 5K meticulously curated test samples, covering 26 subfields across 4 key areas of computer science, encompassing various task forms and divisions of knowledge and reasoning. Utilizing CS-Bench, we conduct a comprehensive evaluation of over 30 mainstream LLMs, revealing the relationship between CS performance and model scales. We also quantitatively analyze the reasons for failures in existing LLMs and highlight directions for improvements, including knowledge supplementation and CS-specific reasoning. Further cross-capability experiments show a high correlation between LLMs' capabilities in computer science and their abilities in mathematics and coding. Moreover, expert LLMs specialized in mathematics and coding also demonstrate strong performances in several CS subfields. Looking ahead, we envision CS-Bench serving as a cornerstone for LLM applications in the CS field and paving new avenues in assessing LLMs' diverse reasoning capabilities. The CS-Bench data and evaluation code are available at https://github.com/csbench/csbench.
6/14/2024
⛏️
Evaluating LLMs at Evaluating Temporal Generalization
Chenghao Zhu, Nuo Chen, Yufei Gao, Benyou Wang
0
0
The rapid advancement of Large Language Models (LLMs) highlights the urgent need for evolving evaluation methodologies that keep pace with improvements in language comprehension and information processing. However, traditional benchmarks, which are often static, fail to capture the continually changing information landscape, leading to a disparity between the perceived and actual effectiveness of LLMs in ever-changing real-world scenarios. Furthermore, these benchmarks do not adequately measure the models' capabilities over a broader temporal range or their adaptability over time. We examine current LLMs in terms of temporal generalization and bias, revealing that various temporal biases emerge in both language likelihood and prognostic prediction. This serves as a caution for LLM practitioners to pay closer attention to mitigating temporal biases. Also, we propose an evaluation framework Freshbench for dynamically generating benchmarks from the most recent real-world prognostication prediction. Our code is available at https://github.com/FreedomIntelligence/FreshBench. The dataset will be released soon.
5/15/2024