MobileConvRec: A Conversational Dataset for Mobile Apps Recommendations

0

Sign in to get full access
Overview
- This paper introduces MobileConvRec, a new conversational dataset for mobile app recommendations.
- The dataset contains multiturn dialogues between users and a conversational agent discussing mobile app suggestions.
- The authors designed MobileConvRec to enable research on conversational recommender systems for mobile apps.
Plain English Explanation
The paper presents a new dataset called MobileConvRec that is designed to help researchers develop better conversational systems for recommending mobile apps to users. Conversational recommender systems are AI-powered chat interfaces that can discuss and suggest apps based on a user's preferences and needs.
MobileConvRec contains many simulated dialogues between a user and a conversational agent talking about mobile app recommendations. The dialogues cover things like the user explaining what kind of app they're looking for, the agent suggesting options, the user providing feedback, and the agent refining its suggestions.
By having this dataset available, researchers can use it to train and test their conversational recommender systems for mobile apps. This allows them to develop systems that can engage in more natural, human-like dialogues to better understand a user's needs and provide personalized app recommendations. The goal is to make the process of finding and discovering new apps on mobile devices more seamless and enjoyable for users.
Technical Explanation
The MobileConvRec dataset contains over 10,000 multi-turn dialogues between a user and a conversational agent discussing mobile app recommendations. The dialogues were generated using a novel data collection framework that combines language models, knowledge bases, and user persona modeling.
The framework first generates a user persona with attributes like age, interests, and app preferences. It then uses this persona to guide the conversational flow, with the agent making app suggestions based on the user's needs and the user providing feedback. Multiple rounds of this interaction are simulated to create the full dialogues.
The dataset includes not only the text of the conversations, but also metadata like user intents, app information, and sentiment annotations. This allows researchers to analyze the dialogues in depth and develop more advanced conversational recommender systems.
The authors evaluate several baseline models on the MobileConvRec dataset, including retrieval-based and generation-based approaches. The results show that the dataset presents some unique challenges compared to more generic conversational datasets, providing opportunities for further research and innovation in this domain.
Critical Analysis
The MobileConvRec dataset is a valuable resource for advancing the state-of-the-art in conversational recommender systems, but it does have some limitations.
One potential issue is the fully simulated nature of the dialogues. While this allows for fine-grained control and annotation, it may not capture the full complexity and unpredictability of real-world user interactions. Incorporating more diverse user behavior and real-world data could help improve the realism and generalizability of the dataset.
Additionally, the dataset only covers mobile app recommendations, which is a relatively narrow domain. Expanding the dataset to include other types of conversational recommendations, such as for movies, restaurants, or products, could broaden its utility and impact.
Finally, the baseline models evaluated in the paper achieve relatively low performance, suggesting that significant further research and innovation is needed to develop truly robust and effective conversational recommender systems. Exploring more advanced techniques, such as those that leverage persona knowledge, could be a fruitful direction for future work.
Conclusion
The MobileConvRec dataset represents an important step forward in the field of conversational recommender systems. By providing a large-scale, annotated dataset of mobile app discussions, the paper enables researchers to develop more sophisticated and user-friendly conversational interfaces for app discovery and recommendation.
While the dataset has some limitations, it opens up exciting avenues for future research. Advances in this area could significantly improve the mobile app experience for users, helping them find the apps they need more efficiently and enjoyably. The potential impact of this work extends beyond just mobile apps, as the insights and techniques developed here could also be applied to other domains of conversational recommendations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MobileConvRec: A Conversational Dataset for Mobile Apps Recommendations
Srijata Maji, Moghis Fereidouni, Vinaik Chhetri, Umar Farooq, A. B. Siddique
Existing recommendation systems have focused on two paradigms: 1- historical user-item interaction-based recommendations and 2- conversational recommendations. Conversational recommendation systems facilitate natural language dialogues between users and the system, allowing the system to solicit users' explicit needs while enabling users to inquire about recommendations and provide feedback. Due to substantial advancements in natural language processing, conversational recommendation systems have gained prominence. Existing conversational recommendation datasets have greatly facilitated research in their respective domains. Despite the exponential growth in mobile users and apps in recent years, research in conversational mobile app recommender systems has faced substantial constraints. This limitation can primarily be attributed to the lack of high-quality benchmark datasets specifically tailored for mobile apps. To facilitate research for conversational mobile app recommendations, we introduce MobileConvRec. MobileConvRec simulates conversations by leveraging real user interactions with mobile apps on the Google Play store, originally captured in large-scale mobile app recommendation dataset MobileRec. The proposed conversational recommendation dataset synergizes sequential user-item interactions, which reflect implicit user preferences, with comprehensive multi-turn conversations to effectively grasp explicit user needs. MobileConvRec consists of over 12K multi-turn recommendation-related conversations spanning 45 app categories. Moreover, MobileConvRec presents rich metadata for each app such as permissions data, security and privacy-related information, and binary executables of apps, among others. We demonstrate that MobileConvRec can serve as an excellent testbed for conversational mobile app recommendation through a comparative study of several pre-trained large language models.
Read more5/29/2024
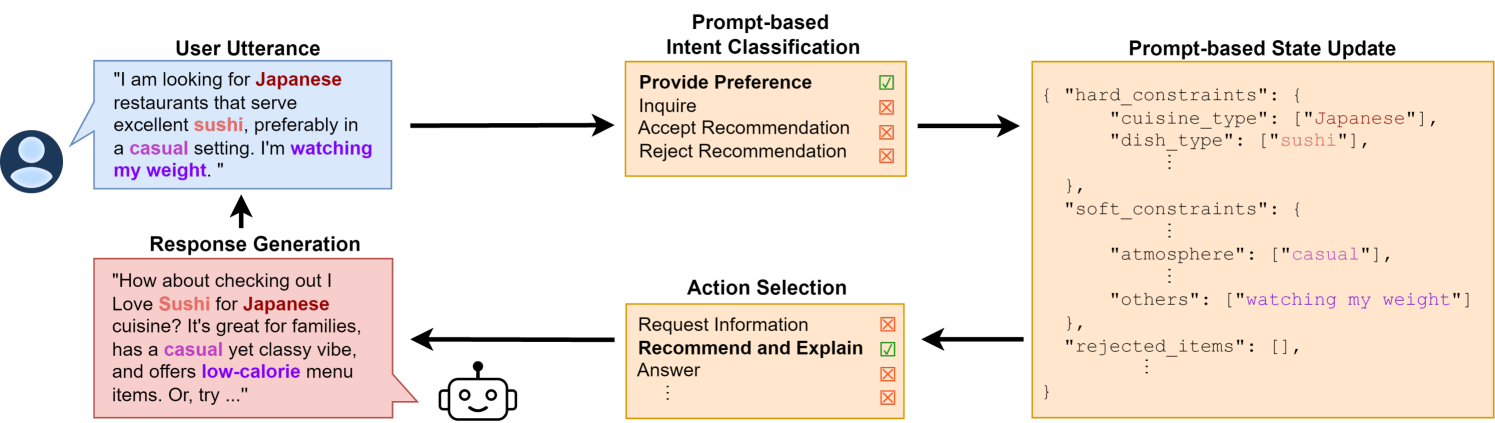
0
Retrieval-Augmented Conversational Recommendation with Prompt-based Semi-Structured Natural Language State Tracking
Sara Kemper, Justin Cui, Kai Dicarlantonio, Kathy Lin, Danjie Tang, Anton Korikov, Scott Sanner
Conversational recommendation (ConvRec) systems must understand rich and diverse natural language (NL) expressions of user preferences and intents, often communicated in an indirect manner (e.g., I'm watching my weight). Such complex utterances make retrieving relevant items challenging, especially if only using often incomplete or out-of-date metadata. Fortunately, many domains feature rich item reviews that cover standard metadata categories and offer complex opinions that might match a user's interests (e.g., classy joint for a date). However, only recently have large language models (LLMs) let us unlock the commonsense connections between user preference utterances and complex language in user-generated reviews. Further, LLMs enable novel paradigms for semi-structured dialogue state tracking, complex intent and preference understanding, and generating recommendations, explanations, and question answers. We thus introduce a novel technology RA-Rec, a Retrieval-Augmented, LLM-driven dialogue state tracking system for ConvRec, showcased with a video, open source GitHub repository, and interactive Google Colab notebook.
Read more6/4/2024

0
MerRec: A Large-scale Multipurpose Mercari Dataset for Consumer-to-Consumer Recommendation Systems
Lichi Li, Zainul Abi Din, Zhen Tan, Sam London, Tianlong Chen, Ajay Daptardar
In the evolving e-commerce field, recommendation systems crucially shape user experience and engagement. The rise of Consumer-to-Consumer (C2C) recommendation systems, noted for their flexibility and ease of access for customer vendors, marks a significant trend. However, the academic focus remains largely on Business-to-Consumer (B2C) models, leaving a gap filled by the limited C2C recommendation datasets that lack in item attributes, user diversity, and scale. The intricacy of C2C recommendation systems is further accentuated by the dual roles users assume as both sellers and buyers, introducing a spectrum of less uniform and varied inputs. Addressing this, we introduce MerRec, the first large-scale dataset specifically for C2C recommendations, sourced from the Mercari e-commerce platform, covering millions of users and products over 6 months in 2023. MerRec not only includes standard features such as user_id, item_id, and session_id, but also unique elements like timestamped action types, product taxonomy, and textual product attributes, offering a comprehensive dataset for research. This dataset, extensively evaluated across four recommendation tasks, establishes a new benchmark for the development of advanced recommendation algorithms in real-world scenarios, bridging the gap between academia and industry and propelling the study of C2C recommendations. Our experiment code is available at https://github.com/mercari/mercari-ml-merrec-pub-us and dataset at https://huggingface.co/datasets/mercari-us/merrec.
Read more7/18/2024

0
EasyRec: Simple yet Effective Language Models for Recommendation
Xubin Ren, Chao Huang
Deep neural networks have become a powerful technique for learning representations from user-item interaction data in collaborative filtering (CF) for recommender systems. However, many existing methods heavily rely on unique user and item IDs, which limits their ability to perform well in practical zero-shot learning scenarios where sufficient training data may be unavailable. Inspired by the success of language models (LMs) and their strong generalization capabilities, a crucial question arises: How can we harness the potential of language models to empower recommender systems and elevate its generalization capabilities to new heights? In this study, we propose EasyRec - an effective and easy-to-use approach that seamlessly integrates text-based semantic understanding with collaborative signals. EasyRec employs a text-behavior alignment framework, which combines contrastive learning with collaborative language model tuning, to ensure a strong alignment between the text-enhanced semantic space and the collaborative behavior information. Extensive empirical evaluations across diverse real-world datasets demonstrate the superior performance of EasyRec compared to state-of-the-art alternative models, particularly in the challenging text-based zero-shot recommendation scenarios. Furthermore, the study highlights the potential of seamlessly integrating EasyRec as a plug-and-play component into text-enhanced collaborative filtering frameworks, thereby empowering existing recommender systems to elevate their recommendation performance and adapt to the evolving user preferences in dynamic environments. For better result reproducibility of our EasyRec framework, the model implementation details, source code, and datasets are available at the link: https://github.com/HKUDS/EasyRec.
Read more8/19/2024