LiveSpeech: Low-Latency Zero-shot Text-to-Speech via Autoregressive Modeling of Audio Discrete Codes
2406.02897
0
0
Abstract
Prior works have demonstrated zero-shot text-to-speech by using a generative language model on audio tokens obtained via a neural audio codec. It is still challenging, however, to adapt them to low-latency scenarios. In this paper, we present LiveSpeech - a fully autoregressive language model-based approach for zero-shot text-to-speech, enabling low-latency streaming of the output audio. To allow multiple token prediction within a single decoding step, we propose (1) using adaptive codebook loss weights that consider codebook contribution in each frame and focus on hard instances, and (2) grouping codebooks and processing groups in parallel. Experiments show our proposed models achieve competitive results to state-of-the-art baselines in terms of content accuracy, speaker similarity, audio quality, and inference speed while being suitable for low-latency streaming applications.
Create account to get full access
Overview
- This paper introduces LiveSpeech, a low-latency zero-shot text-to-speech (TTS) system that uses autoregressive modeling of audio discrete codes.
- The key innovation is the use of discrete audio codes, which allows the system to generate speech without the need for a pre-trained voice model.
- LiveSpeech achieves low latency and high-quality speech synthesis through its autoregressive modeling approach, which generates audio samples sequentially.
Plain English Explanation
The paper describes a new text-to-speech (TTS) system called LiveSpeech that can generate speech without needing a pre-recorded voice model. Traditional TTS systems require a lot of audio data to train a voice model, but LiveSpeech gets around this by using "discrete audio codes" instead.
These discrete codes are a way of representing the audio signal in a compact, digital format. LiveSpeech then uses an autoregressive model to generate the audio samples one by one, sequentially. This allows the system to produce high-quality speech with low latency, meaning the time between when text is input and when the speech is generated is very short.
The key advantage of LiveSpeech is that it can generate speech for any text, without needing a pre-recorded voice. This makes it useful for applications where you want to generate speech on-the-fly, like virtual assistants or language learning tools. The discrete audio codes and autoregressive modeling are the technical innovations that enable this zero-shot TTS capability.
Technical Explanation
The LiveSpeech system uses an autoregressive model to sequentially generate audio samples from discrete audio codes, rather than relying on a pre-trained voice model. This differs from previous zero-shot TTS approaches like MobileSpeech and Phonetic-enhanced Language Modeling for TTS, which typically require a phonetic representation as input.
The LiveSpeech model first encodes the input text into a sequence of discrete audio codes using a pre-trained audio codec. It then uses an autoregressive model, similar to a language model, to predict the next audio code in the sequence. By generating the audio samples one-by-one in this manner, LiveSpeech is able to achieve low-latency speech synthesis without the need for a full voice model.
The authors also introduce techniques like CLAM-TTS to improve the quality of the generated audio, and SimpleSpeech to make the system more efficient for deployment on mobile devices.
Critical Analysis
The LiveSpeech approach shows promising results for low-latency, zero-shot text-to-speech, but there are some limitations discussed in the paper. One key challenge is ensuring the generated audio maintains high quality and naturalness, as the autoregressive modeling can introduce some artifacts or instability.
The authors note that further research is needed to improve the audio quality, for example by incorporating more sophisticated audio priors or leveraging larger-scale discrete audio codecs. There are also open questions about the scalability of the approach to handle a wider range of speaking styles and languages, beyond the English evaluation in this work.
Additionally, while the zero-shot capability is a strength, the system still relies on a pre-trained audio codec. Improving language model-based zero-shot TTS to further reduce the dependency on external components could be an area for future research.
Overall, the LiveSpeech system represents an interesting step forward in low-latency TTS, but there remains room for improvement in terms of audio quality, language coverage, and reducing external dependencies.
Conclusion
The LiveSpeech paper introduces a novel zero-shot text-to-speech system that can generate high-quality speech with low latency, without requiring a pre-trained voice model. By using autoregressive modeling of discrete audio codes, the system is able to synthesize speech on-the-fly for any input text.
While there are some limitations that require further research, the LiveSpeech approach demonstrates the potential for more flexible and efficient text-to-speech systems. This could lead to improved virtual assistants, language learning tools, and other applications where low-latency speech generation is important. The authors' innovations in discrete audio modeling and autoregressive synthesis are a significant contribution to the field of text-to-speech.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
MobileSpeech: A Fast and High-Fidelity Framework for Mobile Zero-Shot Text-to-Speech
Shengpeng Ji, Ziyue Jiang, Hanting Wang, Jialong Zuo, Zhou Zhao
0
0
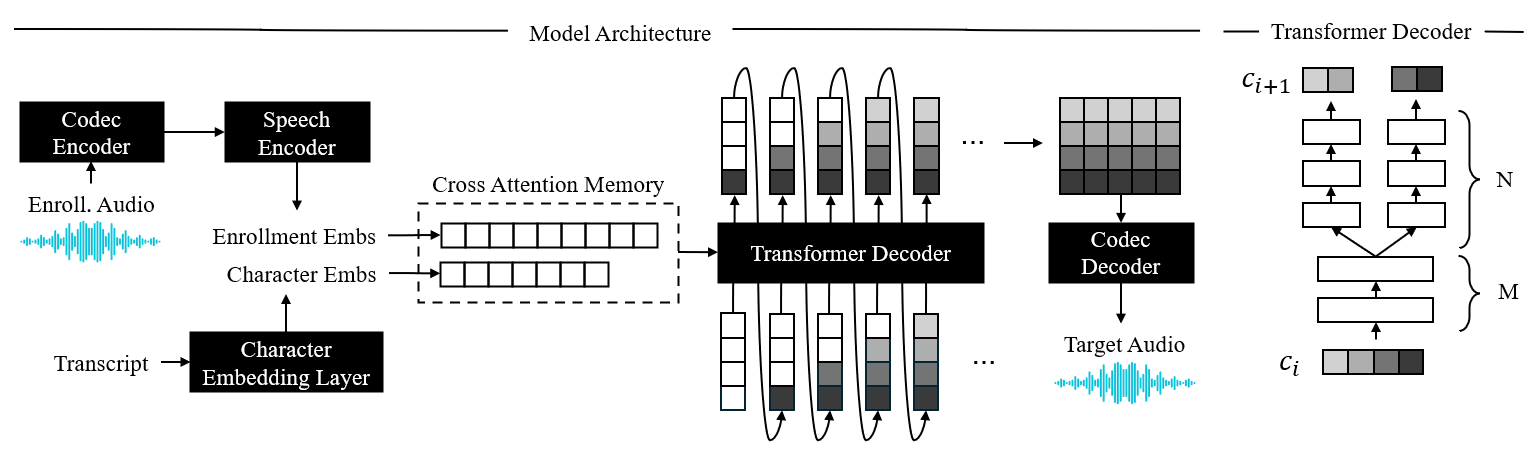
Zero-shot text-to-speech (TTS) has gained significant attention due to its powerful voice cloning capabilities, requiring only a few seconds of unseen speaker voice prompts. However, all previous work has been developed for cloud-based systems. Taking autoregressive models as an example, although these approaches achieve high-fidelity voice cloning, they fall short in terms of inference speed, model size, and robustness. Therefore, we propose MobileSpeech, which is a fast, lightweight, and robust zero-shot text-to-speech system based on mobile devices for the first time. Specifically: 1) leveraging discrete codec, we design a parallel speech mask decoder module called SMD, which incorporates hierarchical information from the speech codec and weight mechanisms across different codec layers during the generation process. Moreover, to bridge the gap between text and speech, we introduce a high-level probabilistic mask that simulates the progression of information flow from less to more during speech generation. 2) For speaker prompts, we extract fine-grained prompt duration from the prompt speech and incorporate text, prompt speech by cross attention in SMD. We demonstrate the effectiveness of MobileSpeech on multilingual datasets at different levels, achieving state-of-the-art results in terms of generating speed and speech quality. MobileSpeech achieves RTF of 0.09 on a single A100 GPU and we have successfully deployed MobileSpeech on mobile devices. Audio samples are available at url{https://mobilespeech.github.io/} .
6/4/2024
Phonetic Enhanced Language Modeling for Text-to-Speech Synthesis
Kun Zhou, Shengkui Zhao, Yukun Ma, Chong Zhang, Hao Wang, Dianwen Ng, Chongjia Ni, Nguyen Trung Hieu, Jia Qi Yip, Bin Ma
0
0
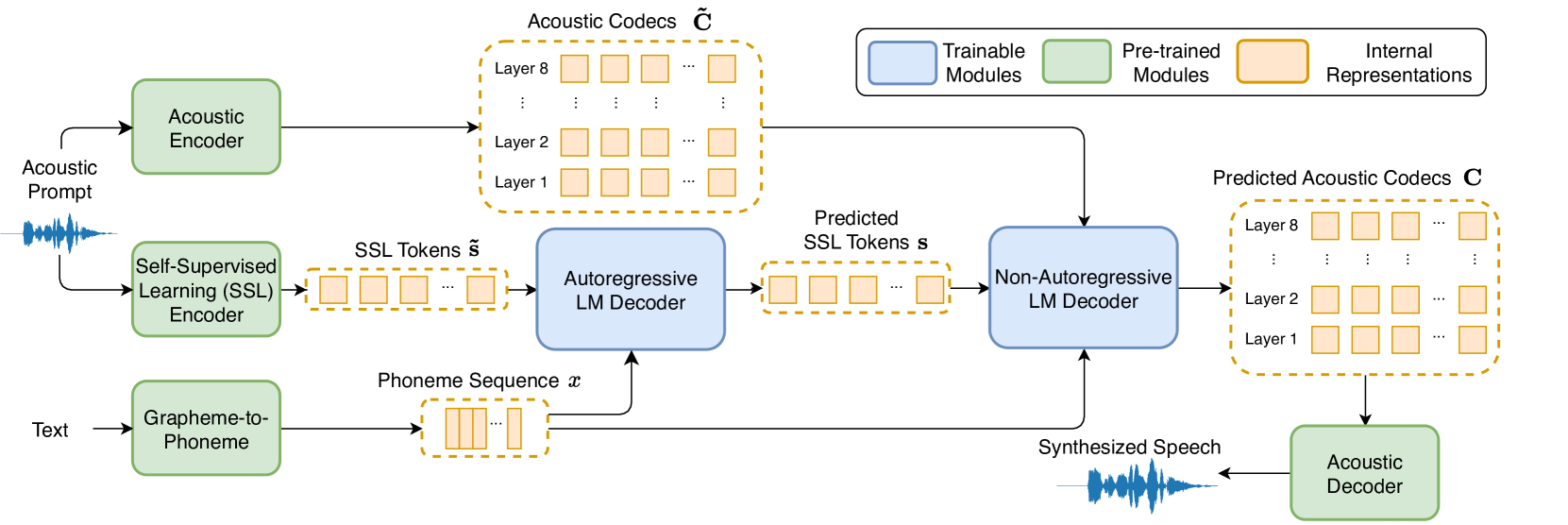
Recent language model-based text-to-speech (TTS) frameworks demonstrate scalability and in-context learning capabilities. However, they suffer from robustness issues due to the accumulation of errors in speech unit predictions during autoregressive language modeling. In this paper, we propose a phonetic enhanced language modeling method to improve the performance of TTS models. We leverage self-supervised representations that are phonetically rich as the training target for the autoregressive language model. Subsequently, a non-autoregressive model is employed to predict discrete acoustic codecs that contain fine-grained acoustic details. The TTS model focuses solely on linguistic modeling during autoregressive training, thereby reducing the error propagation that occurs in non-autoregressive training. Both objective and subjective evaluations validate the effectiveness of our proposed method.
6/13/2024
CLaM-TTS: Improving Neural Codec Language Model for Zero-Shot Text-to-Speech
Jaehyeon Kim, Keon Lee, Seungjun Chung, Jaewoong Cho
0
0
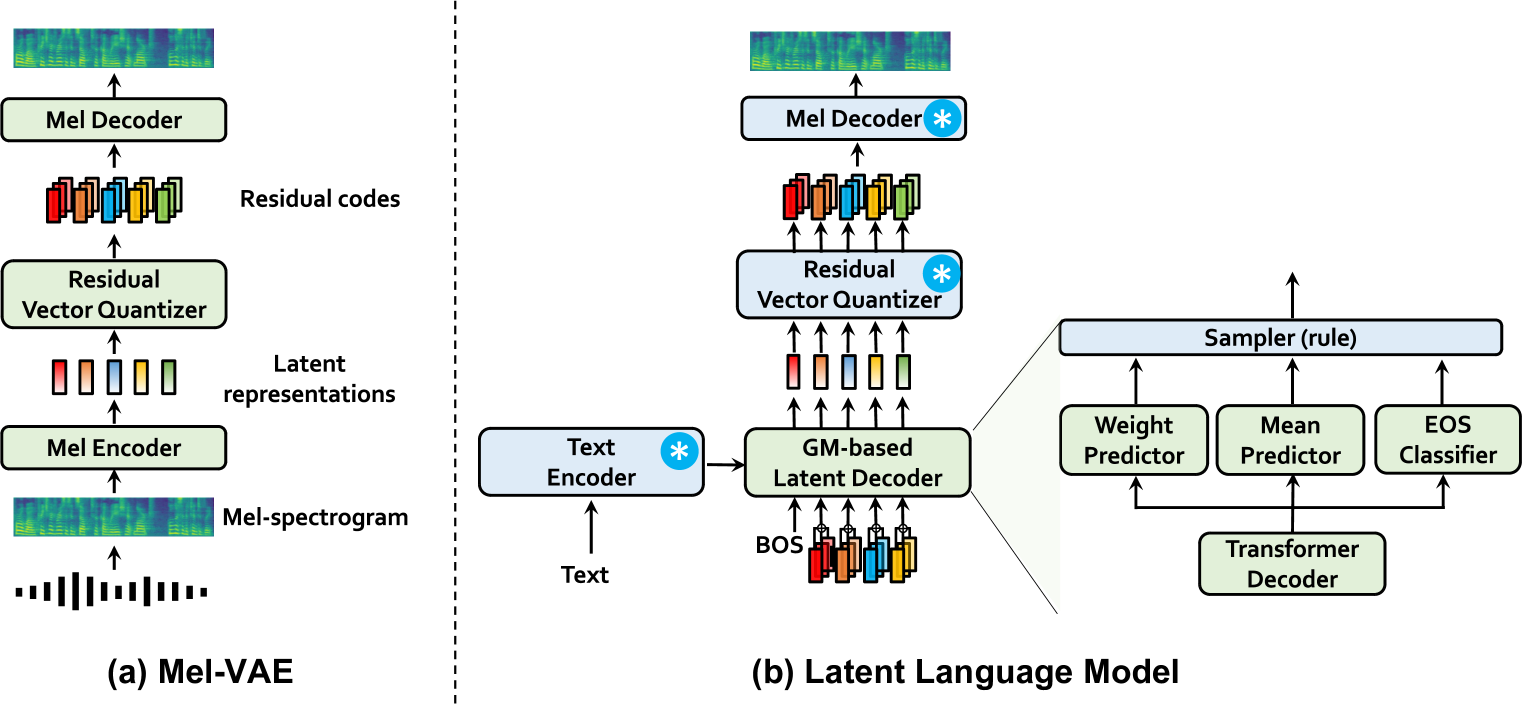
With the emergence of neural audio codecs, which encode multiple streams of discrete tokens from audio, large language models have recently gained attention as a promising approach for zero-shot Text-to-Speech (TTS) synthesis. Despite the ongoing rush towards scaling paradigms, audio tokenization ironically amplifies the scalability challenge, stemming from its long sequence length and the complexity of modelling the multiple sequences. To mitigate these issues, we present CLaM-TTS that employs a probabilistic residual vector quantization to (1) achieve superior compression in the token length, and (2) allow a language model to generate multiple tokens at once, thereby eliminating the need for cascaded modeling to handle the number of token streams. Our experimental results demonstrate that CLaM-TTS is better than or comparable to state-of-the-art neural codec-based TTS models regarding naturalness, intelligibility, speaker similarity, and inference speed. In addition, we examine the impact of the pretraining extent of the language models and their text tokenization strategies on performances.
4/4/2024
🧠
SpeechX: Neural Codec Language Model as a Versatile Speech Transformer
Xiaofei Wang, Manthan Thakker, Zhuo Chen, Naoyuki Kanda, Sefik Emre Eskimez, Sanyuan Chen, Min Tang, Shujie Liu, Jinyu Li, Takuya Yoshioka
0
0
Recent advancements in generative speech models based on audio-text prompts have enabled remarkable innovations like high-quality zero-shot text-to-speech. However, existing models still face limitations in handling diverse audio-text speech generation tasks involving transforming input speech and processing audio captured in adverse acoustic conditions. This paper introduces SpeechX, a versatile speech generation model capable of zero-shot TTS and various speech transformation tasks, dealing with both clean and noisy signals. SpeechX combines neural codec language modeling with multi-task learning using task-dependent prompting, enabling unified and extensible modeling and providing a consistent way for leveraging textual input in speech enhancement and transformation tasks. Experimental results show SpeechX's efficacy in various tasks, including zero-shot TTS, noise suppression, target speaker extraction, speech removal, and speech editing with or without background noise, achieving comparable or superior performance to specialized models across tasks. See https://aka.ms/speechx for demo samples.
6/27/2024