MoDA: Leveraging Motion Priors from Videos for Advancing Unsupervised Domain Adaptation in Semantic Segmentation

0

Sign in to get full access
Overview
- This paper proposes a novel unsupervised domain adaptation (UDA) method called MoDA that leverages motion priors from videos to improve semantic segmentation performance on target domains.
- MoDA combines geometric learning and motion-guided adaptation to bridge the domain gap between source and target datasets.
- The method achieves state-of-the-art results on several benchmark datasets, demonstrating the effectiveness of utilizing motion information for UDA in semantic segmentation.
Plain English Explanation
Semantic segmentation is the task of dividing an image into meaningful regions or objects, like identifying all the cars, people, or buildings in a scene. This is an important capability for applications like self-driving cars and scene understanding.
However, training a good semantic segmentation model requires lots of labeled training data, which can be expensive and time-consuming to obtain. Unsupervised domain adaptation (UDA) aims to address this by adapting a model trained on one dataset (the source domain) to perform well on a different, unlabeled dataset (the target domain).
The key insight of this paper is that motion information from videos can provide useful cues to help bridge the gap between source and target domains. For example, the way cars or people move in a video can give clues about their semantic segmentation, even without labeled data.
The MoDA method proposed in this paper leverages these motion priors to improve UDA for semantic segmentation. It combines geometric learning (using video motion) and motion-guided adaptation to adapt the segmentation model from source to target domains.
The experiments show that MoDA achieves state-of-the-art UDA performance on several benchmark datasets, demonstrating the power of using motion information to tackle this challenging problem.
Technical Explanation
The paper introduces a novel unsupervised domain adaptation (UDA) method called MoDA that leverages motion priors from videos to improve semantic segmentation performance on target domains.
The key components of MoDA are:
-
Geometric Learning: The model learns a set of geometric transformations that map source and target video frames to a shared geometric space. This allows the model to capture motion patterns that are invariant to domain shifts.
-
Motion-Guided Adaptation: The model uses the learned geometric transformations to guide the adaptation of the segmentation network from source to target domains. This helps preserve semantic and motion consistency across domains.
The paper evaluates MoDA on several benchmark datasets for unsupervised domain adaptation in semantic segmentation, including CODA, GTA5-to-Cityscapes, and SYNTHIA-to-Cityscapes. The experiments show that MoDA achieves state-of-the-art performance, outperforming other UDA methods that do not leverage motion information.
Critical Analysis
The paper provides a thorough evaluation of the MoDA method and its performance on standard UDA benchmarks for semantic segmentation. The authors acknowledge some limitations, such as the need for video data in the target domain, which may not always be available in real-world scenarios.
Additionally, the paper does not extensively discuss the potential failure cases or edge cases where MoDA may not perform as well. It would be valuable to explore the limitations of the method and identify potential areas for further research.
Another aspect that could be explored further is the interpretability of the learned geometric transformations and how they relate to the underlying motion patterns in the data. Providing more insights into this could help build a better understanding of the model's inner workings and potentially lead to further improvements.
Conclusion
This paper presents a novel unsupervised domain adaptation method called MoDA that leverages motion priors from videos to improve semantic segmentation performance on target domains. By combining geometric learning and motion-guided adaptation, MoDA is able to effectively bridge the gap between source and target datasets, achieving state-of-the-art results on several benchmark UDA tasks.
The key innovation of this work is the use of motion information to guide the domain adaptation process, which demonstrates the potential of utilizing video data to tackle challenging computer vision problems like semantic segmentation. The promising results of MoDA suggest that further research into motion-based UDA methods could yield significant advancements in this field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MoDA: Leveraging Motion Priors from Videos for Advancing Unsupervised Domain Adaptation in Semantic Segmentation
Fei Pan, Xu Yin, Seokju Lee, Axi Niu, Sungeui Yoon, In So Kweon
Unsupervised domain adaptation (UDA) has been a potent technique to handle the lack of annotations in the target domain, particularly in semantic segmentation task. This study introduces a different UDA scenarios where the target domain contains unlabeled video frames. Drawing upon recent advancements of self-supervised learning of the object motion from unlabeled videos with geometric constraint, we design a textbf{Mo}tion-guided textbf{D}omain textbf{A}daptive semantic segmentation framework (MoDA). MoDA harnesses the self-supervised object motion cues to facilitate cross-domain alignment for segmentation task. First, we present an object discovery module to localize and segment target moving objects using object motion information. Then, we propose a semantic mining module that takes the object masks to refine the pseudo labels in the target domain. Subsequently, these high-quality pseudo labels are used in the self-training loop to bridge the cross-domain gap. On domain adaptive video and image segmentation experiments, MoDA shows the effectiveness utilizing object motion as guidance for domain alignment compared with optical flow information. Moreover, MoDA exhibits versatility as it can complement existing state-of-the-art UDA approaches. Code at https://github.com/feipanir/MoDA.
Read more4/16/2024
🤷
0
Video Unsupervised Domain Adaptation with Deep Learning: A Comprehensive Survey
Yuecong Xu, Haozhi Cao, Zhenghua Chen, Xiaoli Li, Lihua Xie, Jianfei Yang
Video analysis tasks such as action recognition have received increasing research interest with growing applications in fields such as smart healthcare, thanks to the introduction of large-scale datasets and deep learning-based representations. However, video models trained on existing datasets suffer from significant performance degradation when deployed directly to real-world applications due to domain shifts between the training public video datasets (source video domains) and real-world videos (target video domains). Further, with the high cost of video annotation, it is more practical to use unlabeled videos for training. To tackle performance degradation and address concerns in high video annotation cost uniformly, the video unsupervised domain adaptation (VUDA) is introduced to adapt video models from the labeled source domain to the unlabeled target domain by alleviating video domain shift, improving the generalizability and portability of video models. This paper surveys recent progress in VUDA with deep learning. We begin with the motivation of VUDA, followed by its definition, and recent progress of methods for both closed-set VUDA and VUDA under different scenarios, and current benchmark datasets for VUDA research. Eventually, future directions are provided to promote further VUDA research. The repository of this survey is provided at https://github.com/xuyu0010/awesome-video-domain-adaptation.
Read more7/30/2024
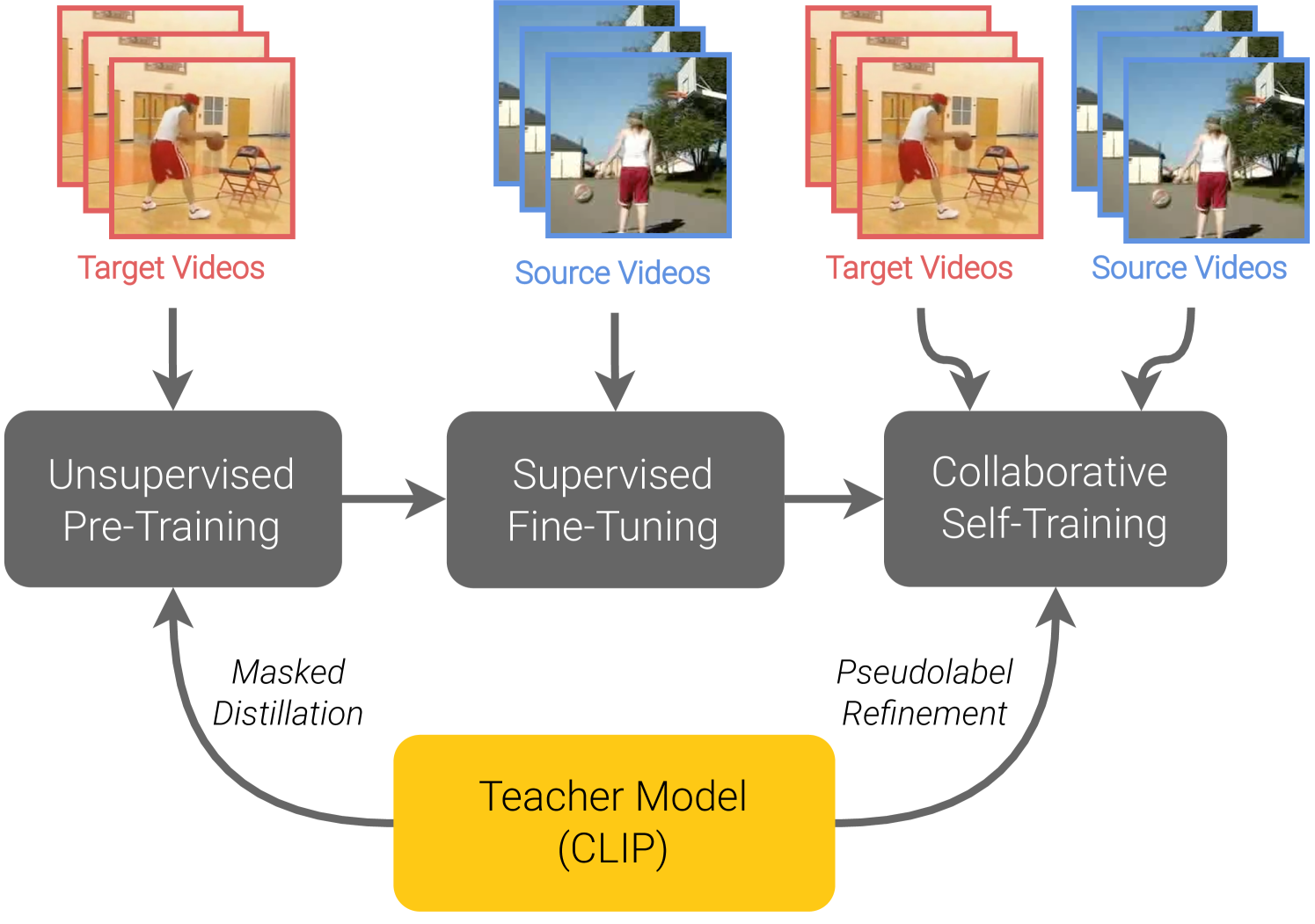
0
Unsupervised Video Domain Adaptation with Masked Pre-Training and Collaborative Self-Training
Arun Reddy, William Paul, Corban Rivera, Ketul Shah, Celso M. de Melo, Rama Chellappa
In this work, we tackle the problem of unsupervised domain adaptation (UDA) for video action recognition. Our approach, which we call UNITE, uses an image teacher model to adapt a video student model to the target domain. UNITE first employs self-supervised pre-training to promote discriminative feature learning on target domain videos using a teacher-guided masked distillation objective. We then perform self-training on masked target data, using the video student model and image teacher model together to generate improved pseudolabels for unlabeled target videos. Our self-training process successfully leverages the strengths of both models to achieve strong transfer performance across domains. We evaluate our approach on multiple video domain adaptation benchmarks and observe significant improvements upon previously reported results.
Read more4/23/2024
0
Style Adaptation for Domain-adaptive Semantic Segmentation
Ting Li, Jianshu Chao, Deyu An
Unsupervised Domain Adaptation (UDA) refers to the method that utilizes annotated source domain data and unlabeled target domain data to train a model capable of generalizing to the target domain data. Domain discrepancy leads to a significant decrease in the performance of general network models trained on the source domain data when applied to the target domain. We introduce a straightforward approach to mitigate the domain discrepancy, which necessitates no additional parameter calculations and seamlessly integrates with self-training-based UDA methods. Through the transfer of the target domain style to the source domain in the latent feature space, the model is trained to prioritize the target domain style during the decision-making process. We tackle the problem at both the image-level and shallow feature map level by transferring the style information from the target domain to the source domain data. As a result, we obtain a model that exhibits superior performance on the target domain. Our method yields remarkable enhancements in the state-of-the-art performance for synthetic-to-real UDA tasks. For example, our proposed method attains a noteworthy UDA performance of 76.93 mIoU on the GTA->Cityscapes dataset, representing a notable improvement of +1.03 percentage points over the previous state-of-the-art results.
Read more4/26/2024