Model Attribution in Machine-Generated Disinformation: A Domain Generalization Approach with Supervised Contrastive Learning

0
Sign in to get full access
Overview
- This paper explores a novel approach to detecting the origin of machine-generated disinformation using supervised contrastive learning.
- The key idea is to train a model to distinguish between text generated by different language models, even when the models produce similar output.
- The proposed method aims to achieve "domain generalization" - the ability to apply the model to new, unseen language models.
Plain English Explanation
The paper presents a way to determine whether a given piece of text was written by a human or generated by a machine learning model. This is an important problem, as machine-generated text can be used to spread disinformation online.
The researchers' approach is to train a model that can <a href="https://aimodels.fyi/papers/arxiv/peering-into-mind-language-models-approach-attribution">recognize the "fingerprints" left by different language models</a>. Even if two models produce similar-sounding text, the researchers believe there are subtle differences that can be detected.
The key innovation is to use <a href="https://aimodels.fyi/papers/arxiv/supervised-knowledge-makes-large-language-models-better">supervised contrastive learning</a> - a technique that forces the model to learn representations that maximize the differences between text from different sources. This allows the model to <a href="https://aimodels.fyi/papers/arxiv/trace-transformer-based-attribution-using-contrastive-embeddings">generalize to new language models</a> it hasn't seen before.
The goal is to create a system that can reliably <a href="https://aimodels.fyi/papers/arxiv/unmasking-imposters-domain-detection-human-vs-machine">distinguish human-written text from machine-generated text</a>, even when the machine output is designed to be deceptive. This could help combat the growing problem of online <a href="https://aimodels.fyi/papers/arxiv/unsupervised-distractor-generation-via-large-language-model">disinformation spread by AI systems</a>.
Technical Explanation
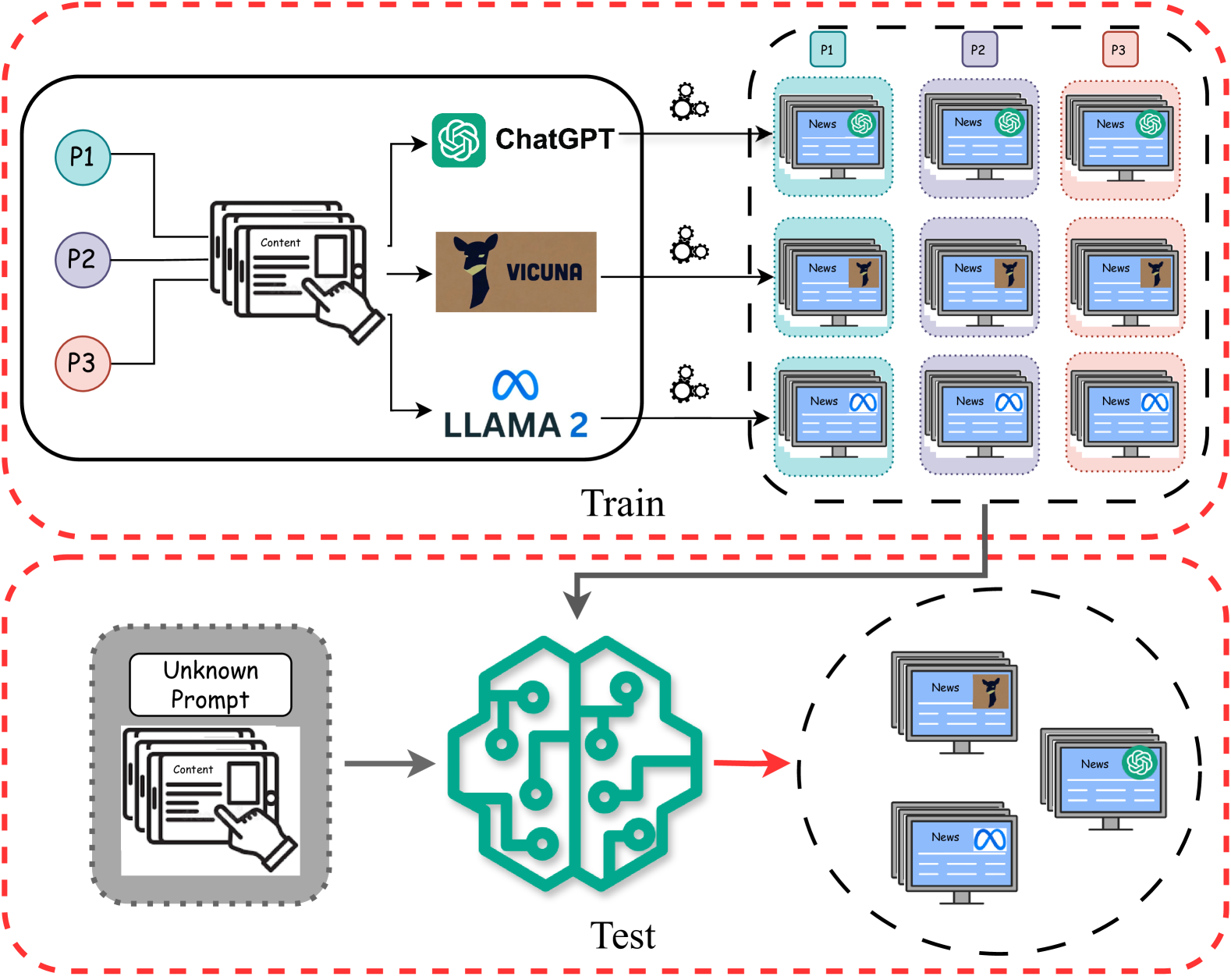
The paper proposes a novel approach for detecting the origin of machine-generated text, using a supervised contrastive learning framework. The key idea is to train a model to learn representations that maximize the differences between text generated by different language models, even when the models produce similar-sounding output.
The researchers first collect a dataset of text from a variety of language models, as well as human-written text. They then train a neural network classifier using supervised contrastive learning, which encourages the model to learn embeddings that cluster text from the same source (i.e., the same language model) while pushing apart text from different sources.
This approach allows the model to generalize to new, unseen language models - a property the authors call "domain generalization." The intuition is that by learning to differentiate between the subtle linguistic fingerprints of different models, the classifier can apply this knowledge to accurately attribute text, even when faced with novel language models.
The paper demonstrates the effectiveness of this approach through experiments on several datasets, showing that the supervised contrastive model outperforms alternative techniques for model attribution. The authors also provide analysis and insights into the learned representations, highlighting how the model is able to capture distinctive patterns in the language model outputs.
Critical Analysis
The paper presents a compelling approach to the important problem of detecting machine-generated disinformation. The use of supervised contrastive learning is a novel and promising technique, as it allows the model to learn robust representations that can generalize to new, unseen language models.
One potential limitation is the reliance on a curated dataset of language model outputs. In a real-world setting, the landscape of language models is constantly evolving, and the model would need to be able to adapt to this changing environment. The authors acknowledge this challenge and suggest avenues for future research to address it, such as exploring self-supervised or few-shot learning approaches.
Additionally, the paper focuses on the technical performance of the model, but does not delve into the societal implications of this technology. While detecting machine-generated disinformation is an important goal, there could be concerns around the potential misuse of such a system, or unintended consequences. The authors could have discussed these issues in more depth to provide a more holistic perspective.
Overall, this paper makes a valuable contribution to the field of machine-generated text detection and serves as a foundation for further research in this critical area.
Conclusion
This paper presents a novel approach to detecting the origin of machine-generated text using supervised contrastive learning. The key innovation is the ability to learn representations that can generalize to new, unseen language models, allowing the model to accurately attribute text even in the face of evolving disinformation threats.
The technical results are promising, but the paper could have delved deeper into the societal implications of this technology. Nevertheless, this work represents an important step forward in the battle against online disinformation and serves as a solid foundation for future research in this critical domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Model Attribution in Machine-Generated Disinformation: A Domain Generalization Approach with Supervised Contrastive Learning
Alimohammad Beigi, Zhen Tan, Nivedh Mudiam, Canyu Chen, Kai Shu, Huan Liu
Model attribution for LLM-generated disinformation poses a significant challenge in understanding its origins and mitigating its spread. This task is especially challenging because modern large language models (LLMs) produce disinformation with human-like quality. Additionally, the diversity in prompting methods used to generate disinformation complicates accurate source attribution. These methods introduce domain-specific features that can mask the fundamental characteristics of the models. In this paper, we introduce the concept of model attribution as a domain generalization problem, where each prompting method represents a unique domain. We argue that an effective attribution model must be invariant to these domain-specific features. It should also be proficient in identifying the originating models across all scenarios, reflecting real-world detection challenges. To address this, we introduce a novel approach based on Supervised Contrastive Learning. This method is designed to enhance the model's robustness to variations in prompts and focuses on distinguishing between different source LLMs. We evaluate our model through rigorous experiments involving three common prompting methods: ``open-ended'', ``rewriting'', and ``paraphrasing'', and three advanced LLMs: ``llama 2'', ``chatgpt'', and ``vicuna''. Our results demonstrate the effectiveness of our approach in model attribution tasks, achieving state-of-the-art performance across diverse and unseen datasets.
Read more8/15/2024
0
Peering into the Mind of Language Models: An Approach for Attribution in Contextual Question Answering
Anirudh Phukan, Shwetha Somasundaram, Apoorv Saxena, Koustava Goswami, Balaji Vasan Srinivasan
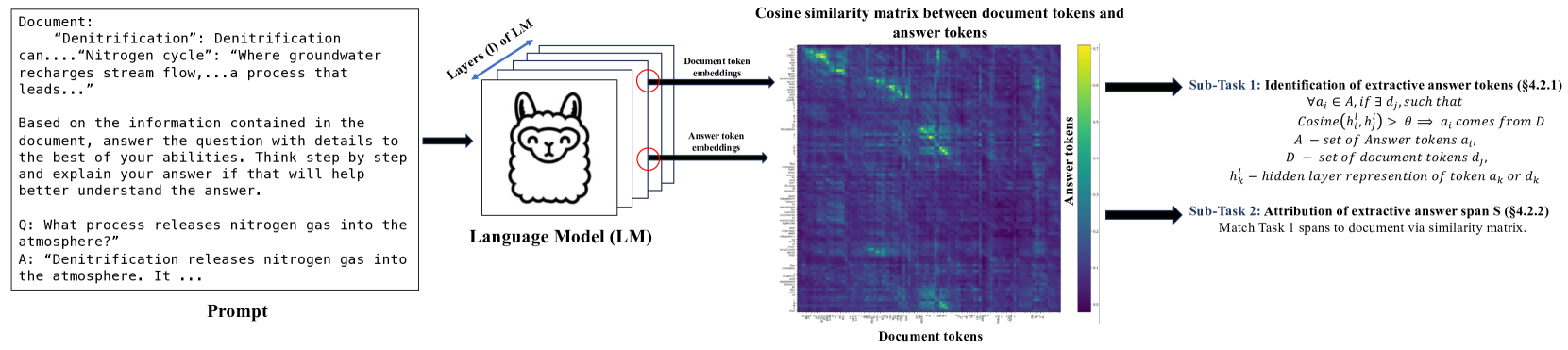
With the enhancement in the field of generative artificial intelligence (AI), contextual question answering has become extremely relevant. Attributing model generations to the input source document is essential to ensure trustworthiness and reliability. We observe that when large language models (LLMs) are used for contextual question answering, the output answer often consists of text copied verbatim from the input prompt which is linked together with glue text generated by the LLM. Motivated by this, we propose that LLMs have an inherent awareness from where the text was copied, likely captured in the hidden states of the LLM. We introduce a novel method for attribution in contextual question answering, leveraging the hidden state representations of LLMs. Our approach bypasses the need for extensive model retraining and retrieval model overhead, offering granular attributions and preserving the quality of generated answers. Our experimental results demonstrate that our method performs on par or better than GPT-4 at identifying verbatim copied segments in LLM generations and in attributing these segments to their source. Importantly, our method shows robust performance across various LLM architectures, highlighting its broad applicability. Additionally, we present Verifiability-granular, an attribution dataset which has token level annotations for LLM generations in the contextual question answering setup.
Read more5/29/2024

0
Supervised Knowledge Makes Large Language Models Better In-context Learners
Linyi Yang, Shuibai Zhang, Zhuohao Yu, Guangsheng Bao, Yidong Wang, Jindong Wang, Ruochen Xu, Wei Ye, Xing Xie, Weizhu Chen, Yue Zhang
Large Language Models (LLMs) exhibit emerging in-context learning abilities through prompt engineering. The recent progress in large-scale generative models has further expanded their use in real-world language applications. However, the critical challenge of improving the generalizability and factuality of LLMs in natural language understanding and question answering remains under-explored. While previous in-context learning research has focused on enhancing models to adhere to users' specific instructions and quality expectations, and to avoid undesired outputs, little to no work has explored the use of task-Specific fine-tuned Language Models (SLMs) to improve LLMs' in-context learning during the inference stage. Our primary contribution is the establishment of a simple yet effective framework that enhances the reliability of LLMs as it: 1) generalizes out-of-distribution data, 2) elucidates how LLMs benefit from discriminative models, and 3) minimizes hallucinations in generative tasks. Using our proposed plug-in method, enhanced versions of Llama 2 and ChatGPT surpass their original versions regarding generalizability and factuality. We offer a comprehensive suite of resources, including 16 curated datasets, prompts, model checkpoints, and LLM outputs across 9 distinct tasks. The code and data are released at: https://github.com/YangLinyi/Supervised-Knowledge-Makes-Large-Language-Models-Better-In-context-Learners. Our empirical analysis sheds light on the advantages of incorporating discriminative models into LLMs and highlights the potential of our methodology in fostering more reliable LLMs.
Read more4/12/2024

0
TRACE: TRansformer-based Attribution using Contrastive Embeddings in LLMs
Cheng Wang, Xinyang Lu, See-Kiong Ng, Bryan Kian Hsiang Low
The rapid evolution of large language models (LLMs) represents a substantial leap forward in natural language understanding and generation. However, alongside these advancements come significant challenges related to the accountability and transparency of LLM responses. Reliable source attribution is essential to adhering to stringent legal and regulatory standards, including those set forth by the General Data Protection Regulation. Despite the well-established methods in source attribution within the computer vision domain, the application of robust attribution frameworks to natural language processing remains underexplored. To bridge this gap, we propose a novel and versatile TRansformer-based Attribution framework using Contrastive Embeddings called TRACE that, in particular, exploits contrastive learning for source attribution. We perform an extensive empirical evaluation to demonstrate the performance and efficiency of TRACE in various settings and show that TRACE significantly improves the ability to attribute sources accurately, making it a valuable tool for enhancing the reliability and trustworthiness of LLMs.
Read more7/9/2024