TRACE: TRansformer-based Attribution using Contrastive Embeddings in LLMs

0

Sign in to get full access
Overview
- Presents a new method called TRACE (TRansformer-based Attribution using Contrastive Embeddings) for interpreting the inner workings of large language models (LLMs)
- Aims to provide faithful and robust attributions that can explain the model's reasoning process
- Leverages contrastive embeddings to capture the semantic relationships between input tokens and the model's predictions
- Demonstrates improved performance over existing attribution methods on a variety of tasks
Plain English Explanation
<TRACE: TRansformer-based Attribution using Contrastive Embeddings in LLMs> is a new technique that helps us understand how large language models (LLMs) make their decisions. These models, like GPT-3, are incredibly powerful but can be difficult to interpret. TRACE aims to provide more faithful and robust explanations of the model's reasoning process.
The key idea behind TRACE is to use contrastive embeddings - a way of capturing the semantic relationships between the input tokens and the model's predictions. By looking at how the embeddings change when the model makes a decision, TRACE can highlight the most important parts of the input that influenced the output.
This is important because it can help us trust the model's decisions and understand its strengths and weaknesses. It also opens the door to using LLMs in more specialized and robust ways, like attributing knowledge to specific sources or reasoning about multi-step problems.
Overall, TRACE is a promising step towards making language models more transparent and trustworthy, which is crucial as they become increasingly influential in our lives.
Technical Explanation
<TRACE: TRansformer-based Attribution using Contrastive Embeddings in LLMs> proposes a new attribution method that leverages contrastive embeddings to explain the decision-making process of large language models (LLMs).
The core idea of TRACE is to capture the semantic relationships between the input tokens and the model's predictions using contrastive embeddings. These embeddings are obtained by comparing the model's representations of the input with a set of counterfactual inputs, where specific tokens are replaced or removed. By analyzing how the embeddings change in response to these perturbations, TRACE can identify the most influential input tokens that contributed to the model's output.
The authors evaluate TRACE on a range of tasks, including sentiment analysis, question answering, and natural language inference. They compare its performance to existing attribution methods, such as gradient-based and attention-based approaches, and demonstrate that TRACE provides more faithful and robust attributions.
One key advantage of TRACE is its ability to handle complex reasoning tasks, where the model's decision-making process may involve multiple steps or rely on implicit background knowledge. By leveraging the model's contrastive embeddings, TRACE can shed light on how the model integrates different pieces of information to arrive at its final prediction.
Critical Analysis
The authors of <TRACE: TRansformer-based Attribution using Contrastive Embeddings in LLMs> acknowledge several limitations and areas for future research. One key concern is the computational overhead of TRACE, as the method requires generating and analyzing multiple counterfactual inputs. This could limit its scalability to very large models or high-throughput applications.
Additionally, the authors note that TRACE may be sensitive to the choice of counterfactual inputs and the specific perturbation strategies employed. Further research is needed to explore more robust and generalizable approaches to generating these counterfactuals.
Another potential issue is the interpretability of the TRACE attributions themselves. While the method provides more faithful explanations than existing approaches, the underlying contrastive embeddings may still be complex and difficult for human users to intuitively understand. Bridging the gap between model interpretability and human-understandable explanations remains an active area of research in the field of explainable AI.
Despite these challenges, <TRACE: TRansformer-based Attribution using Contrastive Embeddings in LLMs> represents a significant step forward in the quest to make large language models more transparent and trustworthy. By providing detailed, faithful explanations of the models' decision-making processes, TRACE has the potential to unlock new applications and use cases for these powerful AI systems.
Conclusion
<TRACE: TRansformer-based Attribution using Contrastive Embeddings in LLMs> presents a novel method for interpreting the inner workings of large language models. By leveraging contrastive embeddings, TRACE can provide faithful and robust attributions that shed light on the model's reasoning process.
The authors demonstrate that TRACE outperforms existing attribution techniques on a variety of tasks, making it a promising tool for understanding and trusting language models. As these models become increasingly influential in our lives, the ability to attribute their knowledge and reasoning to specific sources and explain their decision-making process will be crucial for their responsible development and deployment.
While TRACE has some limitations that require further research, it represents an important step forward in the field of explainable AI and the quest to make language models more transparent and trustworthy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TRACE: TRansformer-based Attribution using Contrastive Embeddings in LLMs
Cheng Wang, Xinyang Lu, See-Kiong Ng, Bryan Kian Hsiang Low
The rapid evolution of large language models (LLMs) represents a substantial leap forward in natural language understanding and generation. However, alongside these advancements come significant challenges related to the accountability and transparency of LLM responses. Reliable source attribution is essential to adhering to stringent legal and regulatory standards, including those set forth by the General Data Protection Regulation. Despite the well-established methods in source attribution within the computer vision domain, the application of robust attribution frameworks to natural language processing remains underexplored. To bridge this gap, we propose a novel and versatile TRansformer-based Attribution framework using Contrastive Embeddings called TRACE that, in particular, exploits contrastive learning for source attribution. We perform an extensive empirical evaluation to demonstrate the performance and efficiency of TRACE in various settings and show that TRACE significantly improves the ability to attribute sources accurately, making it a valuable tool for enhancing the reliability and trustworthiness of LLMs.
Read more7/9/2024
0
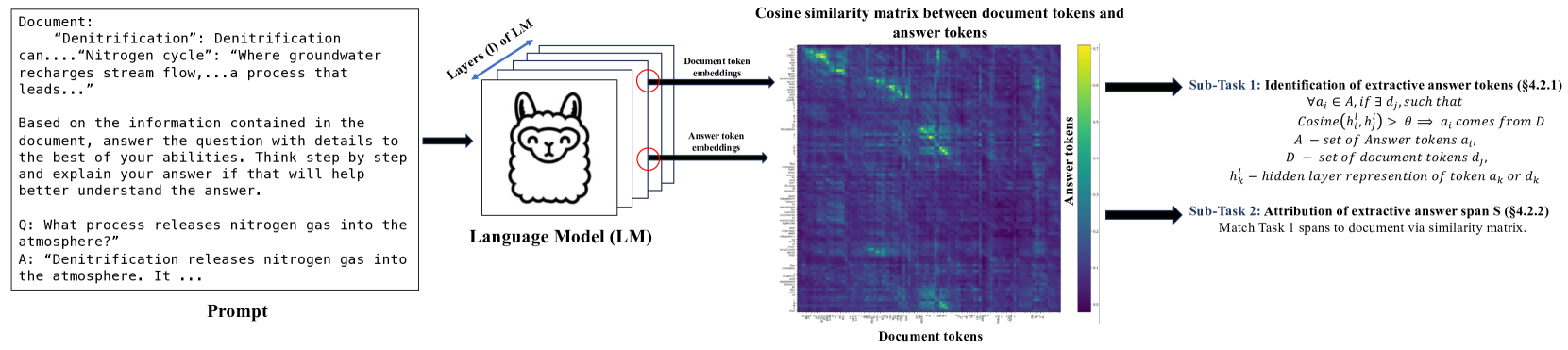
Peering into the Mind of Language Models: An Approach for Attribution in Contextual Question Answering
Anirudh Phukan, Shwetha Somasundaram, Apoorv Saxena, Koustava Goswami, Balaji Vasan Srinivasan
With the enhancement in the field of generative artificial intelligence (AI), contextual question answering has become extremely relevant. Attributing model generations to the input source document is essential to ensure trustworthiness and reliability. We observe that when large language models (LLMs) are used for contextual question answering, the output answer often consists of text copied verbatim from the input prompt which is linked together with glue text generated by the LLM. Motivated by this, we propose that LLMs have an inherent awareness from where the text was copied, likely captured in the hidden states of the LLM. We introduce a novel method for attribution in contextual question answering, leveraging the hidden state representations of LLMs. Our approach bypasses the need for extensive model retraining and retrieval model overhead, offering granular attributions and preserving the quality of generated answers. Our experimental results demonstrate that our method performs on par or better than GPT-4 at identifying verbatim copied segments in LLM generations and in attributing these segments to their source. Importantly, our method shows robust performance across various LLM architectures, highlighting its broad applicability. Additionally, we present Verifiability-granular, an attribution dataset which has token level annotations for LLM generations in the contextual question answering setup.
Read more5/29/2024
0
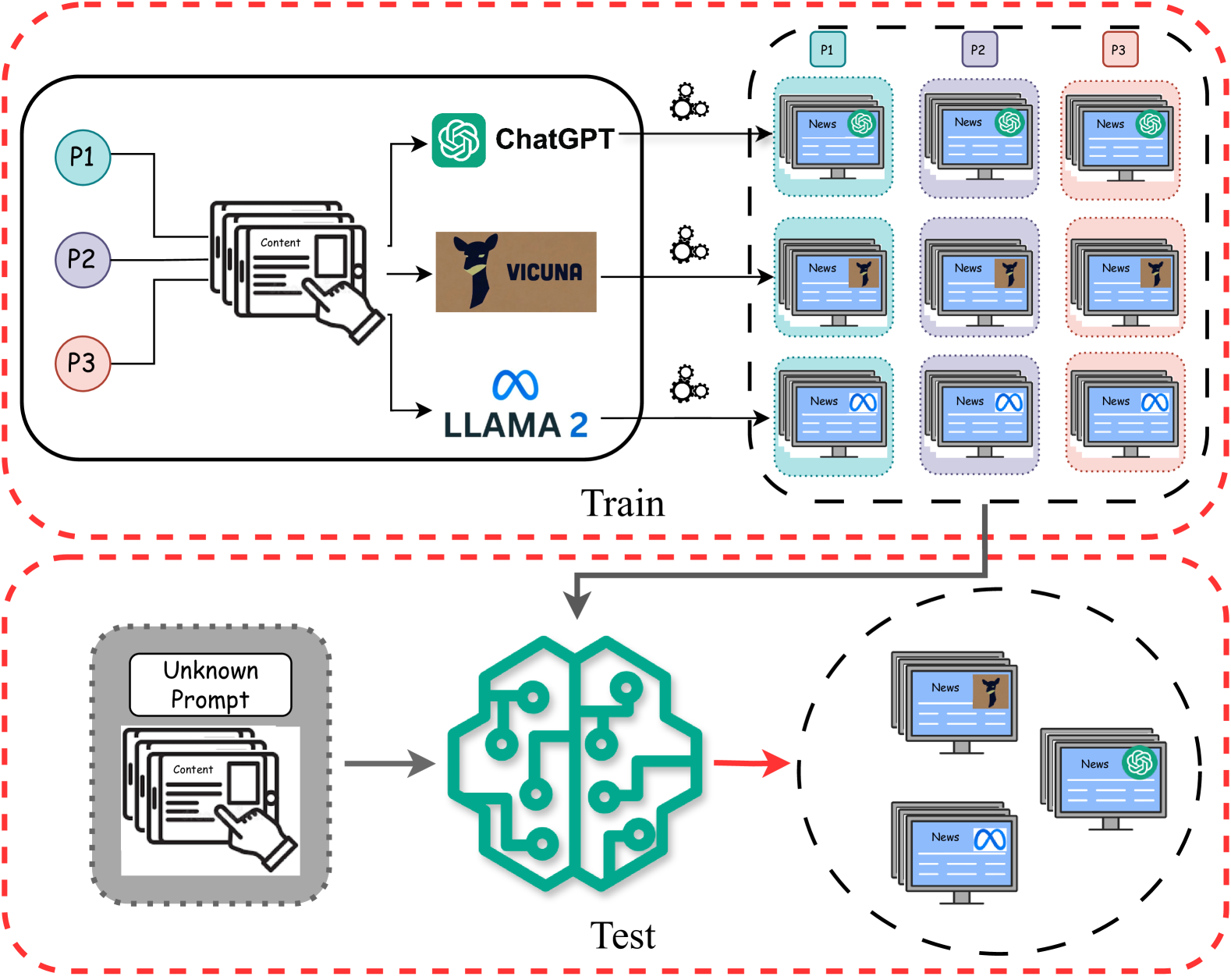
Model Attribution in Machine-Generated Disinformation: A Domain Generalization Approach with Supervised Contrastive Learning
Alimohammad Beigi, Zhen Tan, Nivedh Mudiam, Canyu Chen, Kai Shu, Huan Liu
Model attribution for LLM-generated disinformation poses a significant challenge in understanding its origins and mitigating its spread. This task is especially challenging because modern large language models (LLMs) produce disinformation with human-like quality. Additionally, the diversity in prompting methods used to generate disinformation complicates accurate source attribution. These methods introduce domain-specific features that can mask the fundamental characteristics of the models. In this paper, we introduce the concept of model attribution as a domain generalization problem, where each prompting method represents a unique domain. We argue that an effective attribution model must be invariant to these domain-specific features. It should also be proficient in identifying the originating models across all scenarios, reflecting real-world detection challenges. To address this, we introduce a novel approach based on Supervised Contrastive Learning. This method is designed to enhance the model's robustness to variations in prompts and focuses on distinguishing between different source LLMs. We evaluate our model through rigorous experiments involving three common prompting methods: ``open-ended'', ``rewriting'', and ``paraphrasing'', and three advanced LLMs: ``llama 2'', ``chatgpt'', and ``vicuna''. Our results demonstrate the effectiveness of our approach in model attribution tasks, achieving state-of-the-art performance across diverse and unseen datasets.
Read more8/15/2024
📉
0
Towards Faithful and Robust LLM Specialists for Evidence-Based Question-Answering
Tobias Schimanski, Jingwei Ni, Mathias Kraus, Elliott Ash, Markus Leippold
Advances towards more faithful and traceable answers of Large Language Models (LLMs) are crucial for various research and practical endeavors. One avenue in reaching this goal is basing the answers on reliable sources. However, this Evidence-Based QA has proven to work insufficiently with LLMs in terms of citing the correct sources (source quality) and truthfully representing the information within sources (answer attributability). In this work, we systematically investigate how to robustly fine-tune LLMs for better source quality and answer attributability. Specifically, we introduce a data generation pipeline with automated data quality filters, which can synthesize diversified high-quality training and testing data at scale. We further introduce four test sets to benchmark the robustness of fine-tuned specialist models. Extensive evaluation shows that fine-tuning on synthetic data improves performance on both in- and out-of-distribution. Furthermore, we show that data quality, which can be drastically improved by proposed quality filters, matters more than quantity in improving Evidence-Based QA.
Read more6/4/2024