Modeling and Driving Human Body Soundfields through Acoustic Primitives

0

Sign in to get full access
Overview
- This paper presents a novel approach to modeling and driving human body soundfields using acoustic primitives.
- The researchers introduce a system that can synthesize realistic audio based on a person's body pose and movements, enabling new applications in AR/VR, spatial audio, and multimodal physical scene understanding.
- By leveraging acoustic wave theory and data-driven modeling, the system can generate personalized audio that faithfully reproduces the acoustic characteristics of a user's body.
Plain English Explanation
The paper describes a new way to create realistic audio that responds to a person's body movements and poses. Instead of using traditional audio recordings, the researchers developed a system that can generate unique sounds based on the shape and motion of a person's body.
The key idea is to break down the human body into smaller "acoustic primitives" - basic building blocks that each produce a specific type of sound. By combining these primitives in different ways, the system can model the complex soundfield surrounding a person and dynamically update the audio as they move.
This allows for some exciting applications, like integrating personalized audio into augmented and virtual reality experiences. Instead of just seeing a virtual object, you could also hear the realistic sounds it would make based on your body's interaction with it. The technology could also enable more natural spatial audio that seamlessly follows a person's movements, or help with understanding the physical world through multimodal cues.
Technical Explanation
The core of the system is a data-driven approach to modeling the acoustic soundfield around the human body. The researchers first capture detailed 3D scans and motion data of subjects, along with high-quality audio recordings of the sounds they produce.
They then use this data to train machine learning models that can predict the acoustic response of the body given its pose and movement. Specifically, they decompose the body into a set of "acoustic primitives" - basic geometric shapes like spheres and cylinders - that each have a characteristic acoustic signature.
By combining these primitive elements in different configurations, the models can synthesize the full soundfield surrounding a person. This allows the system to dynamically update the audio in real-time as the person's pose and motion change.
The researchers evaluate their approach through both objective and subjective metrics, showing that it can generate perceptually convincing audio that closely matches real-world recordings. They also demonstrate several applications, including using the system to drive spatial audio in an AR environment and enabling zero-shot transfer of sounds to new scenes.
Critical Analysis
The paper presents a compelling approach to modeling human body acoustics, but there are some potential limitations and areas for further research.
One key challenge is the reliance on detailed 3D scans and motion capture data, which may limit the scalability and accessibility of the system. The researchers mention the possibility of using more easily-obtained data like video, but it's unclear how this would impact the fidelity of the results.
Additionally, the current system only models the direct acoustic response of the body, without considering factors like clothing, environmental reflections, or interactions with other objects. Expanding the model to handle these more complex scenarios could be an important direction for future work.
Finally, while the paper demonstrates several promising applications, the ultimate value of this technology will depend on how well it integrates with and enhances larger interactive systems. Closer collaboration with researchers in multimodal physical scene understanding could help unlock the full potential of this approach.
Conclusion
This paper introduces a novel technique for modeling and driving human body soundfields using acoustic primitives. By decomposing the body into basic geometric elements and learning their acoustic characteristics, the researchers have developed a system that can generate realistic, personalized audio that responds to a person's movements.
The potential applications of this work are wide-ranging, from enhancing AR/VR experiences with more immersive spatial audio, to enabling new multimodal interaction paradigms that seamlessly blend visual and auditory cues. As the researchers continue to refine and expand their approach, this technology could have a transformative impact on how we experience and understand the physical world around us.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Modeling and Driving Human Body Soundfields through Acoustic Primitives
Chao Huang, Dejan Markovic, Chenliang Xu, Alexander Richard
While rendering and animation of photorealistic 3D human body models have matured and reached an impressive quality over the past years, modeling the spatial audio associated with such full body models has been largely ignored so far. In this work, we present a framework that allows for high-quality spatial audio generation, capable of rendering the full 3D soundfield generated by a human body, including speech, footsteps, hand-body interactions, and others. Given a basic audio-visual representation of the body in form of 3D body pose and audio from a head-mounted microphone, we demonstrate that we can render the full acoustic scene at any point in 3D space efficiently and accurately. To enable near-field and realtime rendering of sound, we borrow the idea of volumetric primitives from graphical neural rendering and transfer them into the acoustic domain. Our acoustic primitives result in an order of magnitude smaller soundfield representations and overcome deficiencies in near-field rendering compared to previous approaches.
Read more7/23/2024

0
Sound Field Synthesis with Acoustic Waves
Mohamed F. Mansour
We propose a practical framework to synthesize the broadband sound-field on a small rigid surface based on the physics of sound propagation. The sound-field is generated as a composite map of two components: the room component and the device component, with acoustic plane waves as the core tool for the generation. This decoupling of room and device components significantly reduces the problem complexity and provides accurate rendering of the sound-field. We describe in detail the theoretical foundations, and efficient procedures of the implementation. The effectiveness of the proposed framework is established through rigorous validation under different environment setups.
Read more7/16/2024
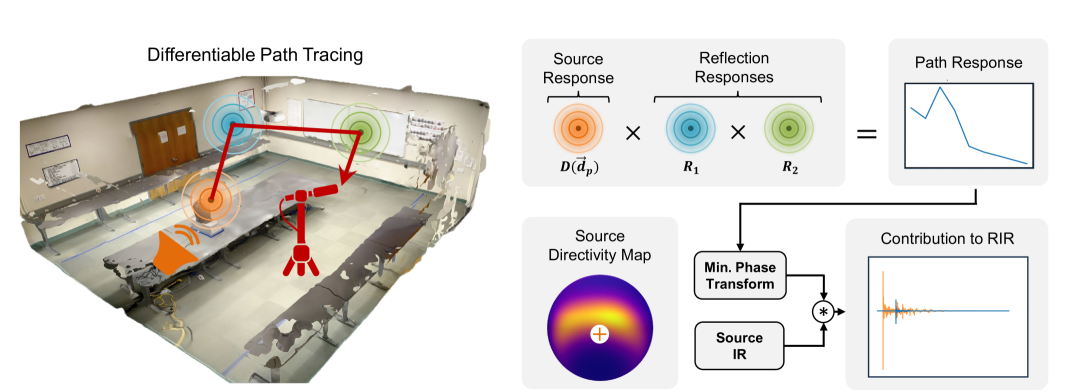
0
Hearing Anything Anywhere
Mason Wang, Ryosuke Sawata, Samuel Clarke, Ruohan Gao, Shangzhe Wu, Jiajun Wu
Recent years have seen immense progress in 3D computer vision and computer graphics, with emerging tools that can virtualize real-world 3D environments for numerous Mixed Reality (XR) applications. However, alongside immersive visual experiences, immersive auditory experiences are equally vital to our holistic perception of an environment. In this paper, we aim to reconstruct the spatial acoustic characteristics of an arbitrary environment given only a sparse set of (roughly 12) room impulse response (RIR) recordings and a planar reconstruction of the scene, a setup that is easily achievable by ordinary users. To this end, we introduce DiffRIR, a differentiable RIR rendering framework with interpretable parametric models of salient acoustic features of the scene, including sound source directivity and surface reflectivity. This allows us to synthesize novel auditory experiences through the space with any source audio. To evaluate our method, we collect a dataset of RIR recordings and music in four diverse, real environments. We show that our model outperforms state-ofthe-art baselines on rendering monaural and binaural RIRs and music at unseen locations, and learns physically interpretable parameters characterizing acoustic properties of the sound source and surfaces in the scene.
Read more6/12/2024

0
Content and Style Aware Audio-Driven Facial Animation
Qingju Liu, Hyeongwoo Kim, Gaurav Bharaj
Audio-driven 3D facial animation has several virtual humans applications for content creation and editing. While several existing methods provide solutions for speech-driven animation, precise control over content (what) and style (how) of the final performance is still challenging. We propose a novel approach that takes as input an audio, and the corresponding text to extract temporally-aligned content and disentangled style representations, in order to provide controls over 3D facial animation. Our method is trained in two stages, that evolves from audio prominent styles (how it sounds) to visual prominent styles (how it looks). We leverage a high-resource audio dataset in stage I to learn styles that control speech generation in a self-supervised learning framework, and then fine-tune this model with low-resource audio/3D mesh pairs in stage II to control 3D vertex generation. We employ a non-autoregressive seq2seq formulation to model sentence-level dependencies, and better mouth articulations. Our method provides flexibility that the style of a reference audio and the content of a source audio can be combined to enable audio style transfer. Similarly, the content can be modified, e.g. muting or swapping words, that enables style-preserving content editing.
Read more8/15/2024