Modelling Sampling Distributions of Test Statistics with Autograd
2405.02488
0
0
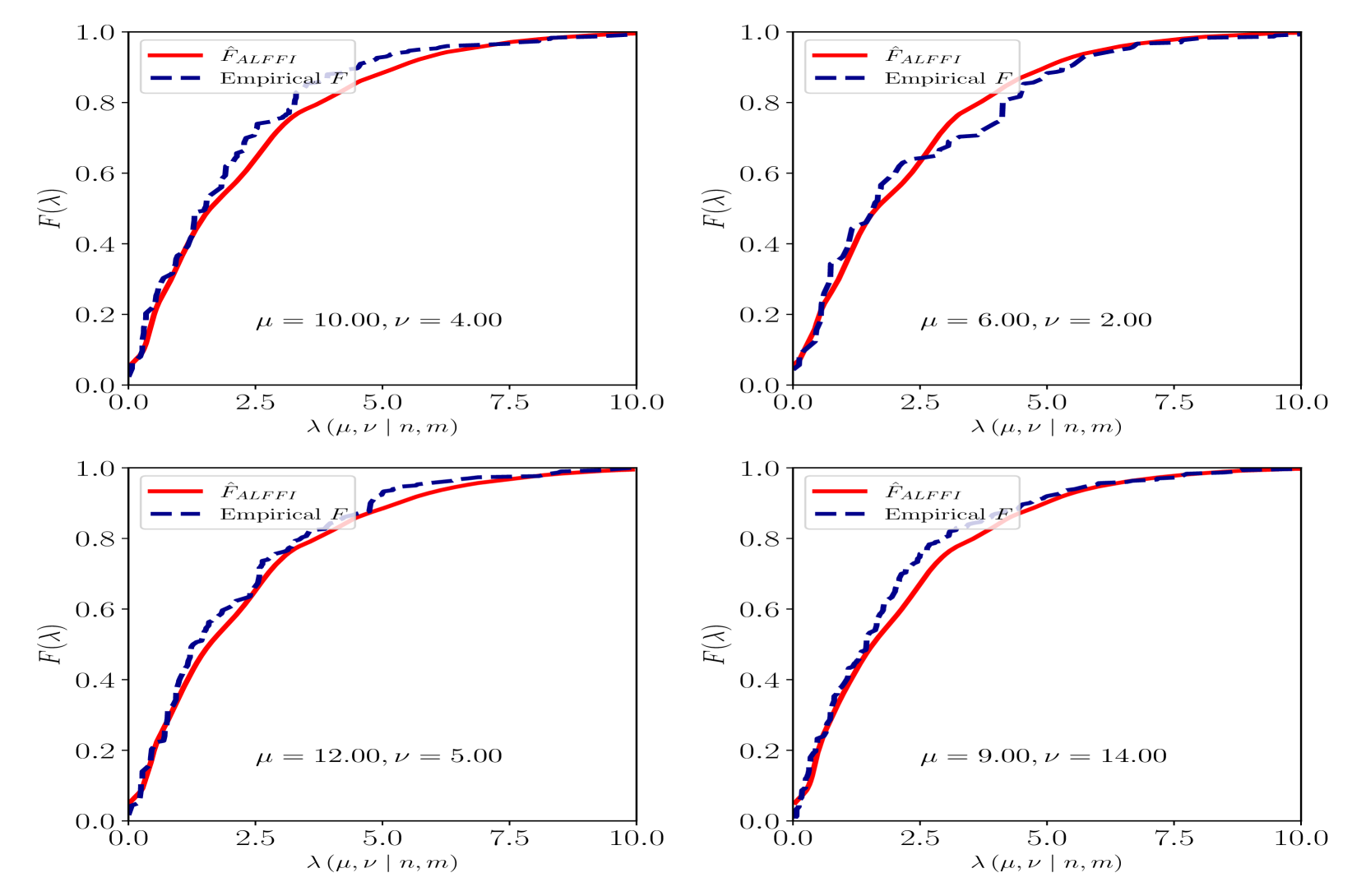
Abstract
Simulation-based inference methods that feature correct conditional coverage of confidence sets based on observations that have been compressed to a scalar test statistic require accurate modelling of either the p-value function or the cumulative distribution function (cdf) of the test statistic. If the model of the cdf, which is typically a deep neural network, is a function of the test statistic then the derivative of the neural network with respect to the test statistic furnishes an approximation of the sampling distribution of the test statistic. We explore whether this approach to modelling conditional 1-dimensional sampling distributions is a viable alternative to the probability density-ratio method, also known as the likelihood-ratio trick. Relatively simple, yet effective, neural network models are used whose predictive uncertainty is quantified through a variety of methods.
Create account to get full access
Overview
- This paper presents a method for modeling the sampling distributions of test statistics using the Autograd library in Python.
- The authors demonstrate how Autograd can be used to efficiently compute the gradients of test statistics, which enables the modeling of their sampling distributions.
- The proposed approach is shown to be more computationally efficient and accurate than traditional Monte Carlo simulation methods for a range of test statistics.
Plain English Explanation
The paper discusses a new way to model the statistical properties of certain mathematical calculations, known as "test statistics." Test statistics are commonly used in fields like statistics and machine learning to make decisions or draw conclusions from data.
Traditionally, researchers have used a technique called "Monte Carlo simulation" to understand the behavior of test statistics. This involves running the same calculation many times with different random data, and then analyzing the results. However, this can be time-consuming and computationally expensive, especially for complex test statistics.
The authors of this paper propose a different approach using a library called Autograd. Autograd is a tool that can automatically calculate the "gradients" or sensitivity of a calculation to its inputs. By leveraging Autograd, the researchers show they can model the sampling distribution of a test statistic much more efficiently than Monte Carlo simulation.
This is a valuable contribution because it allows researchers to better understand the statistical properties of the tools they use, without having to run costly simulations. The paper on new methods for computing the generalized chi-square distribution and the paper on sample-efficient neural likelihood-free Bayesian inference discuss related techniques that could complement this work.
Technical Explanation
The core idea of the paper is to use the Autograd library to compute the gradients of test statistics with respect to their inputs. This allows the authors to efficiently model the sampling distribution of these statistics, without relying on computationally intensive Monte Carlo simulation.
Specifically, the authors show how Autograd can be used to calculate the Jacobian matrix of a test statistic, which encodes the sensitivity of the statistic to changes in its inputs. By sampling from the distribution of the inputs and propagating these samples through the Jacobian, they are able to generate samples from the sampling distribution of the test statistic.
The authors demonstrate this approach on several common test statistics, including the t-statistic, F-statistic, and chi-square statistic. They show that their Autograd-based method is more accurate and computationally efficient than Monte Carlo simulation, especially for complex test statistics like the generalized chi-square distribution.
Additionally, the authors discuss how their approach can be extended to model the sampling distributions of integer-valued time series and causal representation learning tasks, where accurate modeling of test statistics is crucial.
Critical Analysis
The paper presents a compelling and well-executed approach for modeling the sampling distributions of test statistics using Autograd. The authors provide a thorough theoretical justification for their method and demonstrate its effectiveness through extensive experiments.
One potential limitation of the approach is that it relies on the availability of analytical expressions for the test statistics of interest. While the authors show that this is the case for many common test statistics, there may be some more complex statistics where such expressions are not readily available.
Additionally, the paper does not address the potential issues that could arise when the assumptions underlying the test statistics (e.g., normality, independence) are violated. In such cases, the sampling distributions may be more complex, and the Autograd-based approach may not be as effective.
Despite these minor caveats, the paper represents a significant advancement in the efficient modeling of test statistic sampling distributions. The authors' work could have important implications for a wide range of fields that rely on statistical inference, such as Bayesian inference and stochastic dynamical systems.
Conclusion
This paper introduces a novel approach for modeling the sampling distributions of test statistics using the Autograd library. By leveraging Autograd's ability to efficiently compute gradients, the authors demonstrate a more accurate and computationally efficient alternative to traditional Monte Carlo simulation methods.
The proposed technique has the potential to significantly streamline statistical inference and hypothesis testing across a variety of scientific and engineering disciplines. By better characterizing the behavior of test statistics, researchers can make more informed decisions and draw more reliable conclusions from their data.
Overall, this work represents an important contribution to the field of statistical computing and numerical analysis, with promising applications in areas such as Bayesian inference, time series analysis, and causal representation learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
Model Free Prediction with Uncertainty Assessment
Yuling Jiao, Lican Kang, Jin Liu, Heng Peng, Heng Zuo
0
0
Deep nonparametric regression, characterized by the utilization of deep neural networks to learn target functions, has emerged as a focus of research attention in recent years. Despite considerable progress in understanding convergence rates, the absence of asymptotic properties hinders rigorous statistical inference. To address this gap, we propose a novel framework that transforms the deep estimation paradigm into a platform conducive to conditional mean estimation, leveraging the conditional diffusion model. Theoretically, we develop an end-to-end convergence rate for the conditional diffusion model and establish the asymptotic normality of the generated samples. Consequently, we are equipped to construct confidence regions, facilitating robust statistical inference. Furthermore, through numerical experiments, we empirically validate the efficacy of our proposed methodology.
6/18/2024
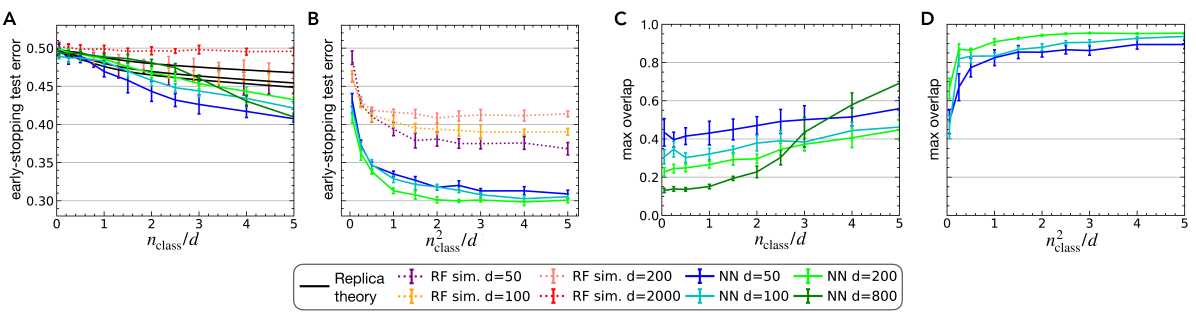
Learning from higher-order statistics, efficiently: hypothesis tests, random features, and neural networks
Eszter Sz'ekely, Lorenzo Bardone, Federica Gerace, Sebastian Goldt
0
0
Neural networks excel at discovering statistical patterns in high-dimensional data sets. In practice, higher-order cumulants, which quantify the non-Gaussian correlations between three or more variables, are particularly important for the performance of neural networks. But how efficient are neural networks at extracting features from higher-order cumulants? We study this question in the spiked cumulant model, where the statistician needs to recover a privileged direction or spike from the order-$pge 4$ cumulants of $d$-dimensional inputs. Existing literature established the presence of a wide statistical-to-computational gap in this problem. We deepen this line of work by finding an exact formula for the likelihood ratio norm which proves that statistical distinguishability requires $ngtrsim d$ samples, while distinguishing the two distributions in polynomial time requires $n gtrsim d^2$ samples for a wide class of algorithms, i.e. those covered by the low-degree conjecture. Numerical experiments show that neural networks do indeed learn to distinguish the two distributions with quadratic sample complexity, while lazy methods like random features are not better than random guessing in this regime. Our results show that neural networks extract information from higher-ordercorrelations in the spiked cumulant model efficiently, and reveal a large gap in the amount of data required by neural networks and random features to learn from higher-order cumulants.
6/7/2024

New methods for computing the generalized chi-square distribution
Abhranil Das
0
0
We present several exact and approximate mathematical methods and open-source software to compute the cdf, pdf and inverse cdf of the generalized chi-square distribution, which appears in Bayesian classification problems. Some methods are geared for speed, while others are designed to be accurate far into the tails, using which we can also measure large values of the discriminability index $d'$ between multinormals. We compare the accuracy and speed of these methods against the best existing methods.
4/9/2024
🤯
Scalable Subsampling Inference for Deep Neural Networks
Kejin Wu, Dimitris N. Politis
0
0
Deep neural networks (DNN) has received increasing attention in machine learning applications in the last several years. Recently, a non-asymptotic error bound has been developed to measure the performance of the fully connected DNN estimator with ReLU activation functions for estimating regression models. The paper at hand gives a small improvement on the current error bound based on the latest results on the approximation ability of DNN. More importantly, however, a non-random subsampling technique--scalable subsampling--is applied to construct a `subagged' DNN estimator. Under regularity conditions, it is shown that the subagged DNN estimator is computationally efficient without sacrificing accuracy for either estimation or prediction tasks. Beyond point estimation/prediction, we propose different approaches to build confidence and prediction intervals based on the subagged DNN estimator. In addition to being asymptotically valid, the proposed confidence/prediction intervals appear to work well in finite samples. All in all, the scalable subsampling DNN estimator offers the complete package in terms of statistical inference, i.e., (a) computational efficiency; (b) point estimation/prediction accuracy; and (c) allowing for the construction of practically useful confidence and prediction intervals.
5/15/2024