Modular Control Architecture for Safe Marine Navigation: Reinforcement Learning and Predictive Safety Filters

0
🏅
Sign in to get full access
Overview
- Autonomous systems, like self-driving ships, face safety challenges due to complex environments and physical limitations.
- Reinforcement learning can help these systems adapt, but ensuring safety and stability is difficult.
- Predictive Safety Filters (PSF) offer a solution by monitoring and adjusting control actions to meet safety constraints, without hindering the learning process.
Plain English Explanation
Imagine you're trying to teach a robot to navigate a busy harbor, avoiding collisions with other ships. This is a complex task, with constantly changing conditions and physical constraints. A standard control system might struggle to handle all the unpredictable situations.
That's where reinforcement learning comes in. By training the robot to learn from its experiences, it can adapt and become more skilled at tasks like path following and collision avoidance. However, reinforcement learning alone doesn't guarantee the robot will always stay within safe boundaries - it might try risky maneuvers that could lead to accidents.
This is where the Predictive Safety Filter (PSF) steps in. It's like a safety net that monitors the robot's proposed actions and makes adjustments to ensure it stays within the physical and safety limits, without interfering too much with the robot's learning process. Think of it as a co-pilot that watches out for the robot, stepping in only when necessary to prevent accidents.
By combining reinforcement learning with the PSF, the researchers were able to train a simulated autonomous ship to navigate a complex harbor environment safely and effectively. The PSF kept the ship under control, while still allowing the reinforcement learning agent to learn and improve over time.
Technical Explanation
The researchers applied the Predictive Safety Filter (PSF) approach to a simulated autonomous ship (the Cybership II model) to handle its complex, nonlinear dynamics and environmental disturbances.
The PSF is a modular system that works alongside the ship's control policy, which in this case was a reinforcement learning (RL) agent. The RL agent was trained to perform tasks like path following and collision avoidance, while the PSF monitored the RL agent's proposed actions and modified them as needed to ensure safety and stability constraints were met.
The key innovation is that the PSF can work with any control policy, including the RL agent, without requiring explicit constraint handling. This makes the approach more flexible and easier to apply to a wide range of autonomous systems.
The researchers evaluated the performance of the RL agent with and without the PSF, demonstrating that the PSF was able to maintain safety without significantly hindering the RL agent's learning rate or overall performance.
Critical Analysis
The paper presents a promising approach for ensuring safety in autonomous systems that rely on reinforcement learning. By using the Predictive Safety Filter, the researchers were able to address the challenge of maintaining stability and constraint satisfaction, which is a common issue for real-world autonomous systems.
One potential limitation mentioned in the paper is that the PSF relies on accurate models of the system's dynamics and constraints. In a real-world scenario, these models may not be perfect, which could affect the PSF's performance. The researchers suggest that further research is needed to explore the robustness of the PSF to model uncertainties.
Additionally, the paper focuses on a simulated environment, and more testing would be required to validate the approach in real-world conditions. The researchers acknowledge that the Cybership II model may not fully capture the complexity of a real autonomous ship, and field trials would be necessary to assess the PSF's effectiveness in a live setting.
Overall, the Predictive Safety Filter presents an interesting and practical solution for enhancing the safety of reinforcement learning-based autonomous systems. Continued research and development in this area could have significant implications for the deployment of these systems in the real world.
Conclusion
The research presented in this paper demonstrates a promising approach for ensuring the safety of autonomous systems, like self-driving ships, that rely on reinforcement learning. By using a Predictive Safety Filter (PSF) to monitor and adjust the control actions proposed by the reinforcement learning agent, the researchers were able to maintain safety and stability without hindering the agent's learning and performance.
This modular and flexible solution could have widespread applications in the development of robust and reliable autonomous systems that must operate in complex, real-world environments. As the capabilities of these systems continue to grow, the importance of addressing safety challenges will only become more critical. The insights and techniques presented in this paper represent an important step forward in this crucial area of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
Modular Control Architecture for Safe Marine Navigation: Reinforcement Learning and Predictive Safety Filters
Aksel Vaaler, Svein Jostein Husa, Daniel Menges, Thomas Nakken Larsen, Adil Rasheed
Many autonomous systems face safety challenges, requiring robust closed-loop control to handle physical limitations and safety constraints. Real-world systems, like autonomous ships, encounter nonlinear dynamics and environmental disturbances. Reinforcement learning is increasingly used to adapt to complex scenarios, but standard frameworks ensuring safety and stability are lacking. Predictive Safety Filters (PSF) offer a promising solution, ensuring constraint satisfaction in learning-based control without explicit constraint handling. This modular approach allows using arbitrary control policies, with the safety filter optimizing proposed actions to meet physical and safety constraints. We apply this approach to marine navigation, combining RL with PSF on a simulated Cybership II model. The RL agent is trained on path following and collision avpodance, while the PSF monitors and modifies control actions for safety. Results demonstrate the PSF's effectiveness in maintaining safety without hindering the RL agent's learning rate and performance, evaluated against a standard RL agent without PSF.
Read more4/3/2024

0
Gameplay Filters: Safe Robot Walking through Adversarial Imagination
Duy P. Nguyen, Kai-Chieh Hsu, Wenhao Yu, Jie Tan, Jaime F. Fisac
Despite the impressive recent advances in learning-based robot control, ensuring robustness to out-of-distribution conditions remains an open challenge. Safety filters can, in principle, keep arbitrary control policies from incurring catastrophic failures by overriding unsafe actions, but existing solutions for complex (e.g., legged) robot dynamics do not span the full motion envelope and instead rely on local, reduced-order models. These filters tend to overly restrict agility and can still fail when perturbed away from nominal conditions. This paper presents the gameplay filter, a new class of predictive safety filter that continually plays out hypothetical matches between its simulation-trained safety strategy and a virtual adversary co-trained to invoke worst-case events and sim-to-real error, and precludes actions that would cause it to fail down the line. We demonstrate the scalability and robustness of the approach with a first-of-its-kind full-order safety filter for (36-D) quadrupedal dynamics. Physical experiments on two different quadruped platforms demonstrate the superior zero-shot effectiveness of the gameplay filter under large perturbations such as tugging and unmodeled terrain.
Read more8/30/2024
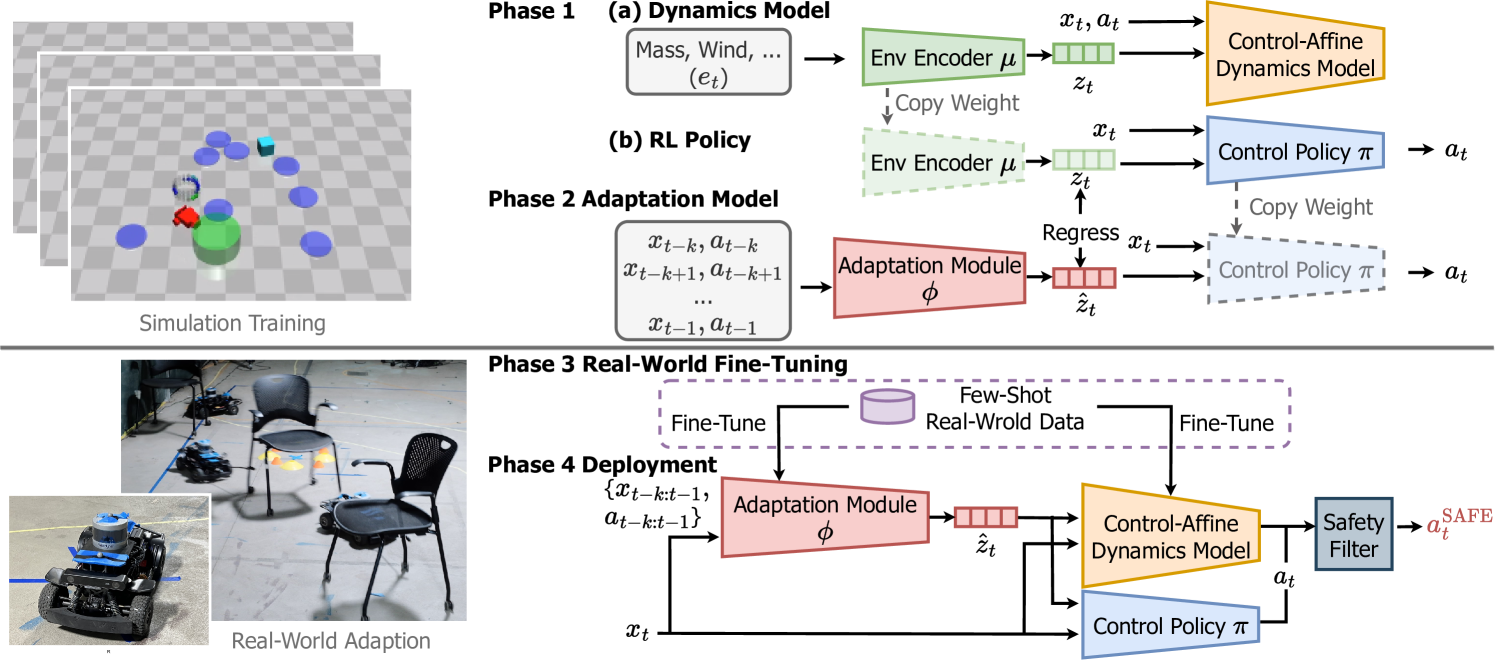
0
Safe Deep Policy Adaptation
Wenli Xiao, Tairan He, John Dolan, Guanya Shi
A critical goal of autonomy and artificial intelligence is enabling autonomous robots to rapidly adapt in dynamic and uncertain environments. Classic adaptive control and safe control provide stability and safety guarantees but are limited to specific system classes. In contrast, policy adaptation based on reinforcement learning (RL) offers versatility and generalizability but presents safety and robustness challenges. We propose SafeDPA, a novel RL and control framework that simultaneously tackles the problems of policy adaptation and safe reinforcement learning. SafeDPA jointly learns adaptive policy and dynamics models in simulation, predicts environment configurations, and fine-tunes dynamics models with few-shot real-world data. A safety filter based on the Control Barrier Function (CBF) on top of the RL policy is introduced to ensure safety during real-world deployment. We provide theoretical safety guarantees of SafeDPA and show the robustness of SafeDPA against learning errors and extra perturbations. Comprehensive experiments on (1) classic control problems (Inverted Pendulum), (2) simulation benchmarks (Safety Gym), and (3) a real-world agile robotics platform (RC Car) demonstrate great superiority of SafeDPA in both safety and task performance, over state-of-the-art baselines. Particularly, SafeDPA demonstrates notable generalizability, achieving a 300% increase in safety rate compared to the baselines, under unseen disturbances in real-world experiments.
Read more4/30/2024
🚀
0
ISAACS: Iterative Soft Adversarial Actor-Critic for Safety
Kai-Chieh Hsu, Duy Phuong Nguyen, Jaime Fern'andez Fisac
The deployment of robots in uncontrolled environments requires them to operate robustly under previously unseen scenarios, like irregular terrain and wind conditions. Unfortunately, while rigorous safety frameworks from robust optimal control theory scale poorly to high-dimensional nonlinear dynamics, control policies computed by more tractable deep methods lack guarantees and tend to exhibit little robustness to uncertain operating conditions. This work introduces a novel approach enabling scalable synthesis of robust safety-preserving controllers for robotic systems with general nonlinear dynamics subject to bounded modeling error by combining game-theoretic safety analysis with adversarial reinforcement learning in simulation. Following a soft actor-critic scheme, a safety-seeking fallback policy is co-trained with an adversarial disturbance agent that aims to invoke the worst-case realization of model error and training-to-deployment discrepancy allowed by the designer's uncertainty. While the learned control policy does not intrinsically guarantee safety, it is used to construct a real-time safety filter (or shield) with robust safety guarantees based on forward reachability rollouts. This shield can be used in conjunction with a safety-agnostic control policy, precluding any task-driven actions that could result in loss of safety. We evaluate our learning-based safety approach in a 5D race car simulator, compare the learned safety policy to the numerically obtained optimal solution, and empirically validate the robust safety guarantee of our proposed safety shield against worst-case model discrepancy.
Read more6/11/2024