MoE-LLaVA: Mixture of Experts for Large Vision-Language Models

1

Sign in to get full access
Overview
- This paper introduces a novel approach called MoE-LLaVA (Mixture of Experts for Large Vision-Language Models) to improve the performance and efficiency of large vision-language models.
- The key idea is to use a Mixture of Experts (MoE) architecture, where the model is divided into multiple specialized "experts" that work together to process inputs more effectively.
- This contrasts with traditional "one-size-fits-all" models that try to handle all tasks and inputs with a single monolithic architecture.
Plain English Explanation
The researchers propose a new way to build large vision-language models that can handle a wide variety of tasks and inputs more effectively. Instead of having a single, generic model try to do everything, they split the model into multiple "experts" - specialized sub-models that each focus on a particular type of task or input.
When presented with a new input, the model dynamically selects the most appropriate experts to process it, rather than forcing the whole model to handle everything. This Mixture of Experts (MoE) approach allows the model to leverage the strengths of different sub-components, leading to improved performance and efficiency.
The researchers show that this MoE-LLaVA architecture outperforms traditional large vision-language models on a range of benchmarks, demonstrating the benefits of this modular, specialized approach. This builds on prior work exploring MoE techniques for scaling up language models and applying MoE to multimodal tasks.
Technical Explanation
The core idea behind MoE-LLaVA is to leverage a Mixture of Experts (MoE) architecture to improve the performance and efficiency of large vision-language models. In a traditional monolithic model, a single architecture is tasked with handling all inputs and tasks. In contrast, MoE-LLaVA divides the model into multiple specialized "expert" sub-models, each of which is trained to excel at a particular type of input or task.
When presented with a new input, the MoE-LLaVA model dynamically selects the most appropriate experts to process it, rather than forcing the entire model to handle everything. This allows the model to leverage the strengths of different sub-components, leading to improved performance and efficiency. The researchers show that this approach outperforms traditional large vision-language models on a range of benchmarks.
The MoE-LLaVA architecture builds on prior work exploring the use of MoE techniques for scaling up language models and applying MoE to multimodal tasks. By adapting these ideas to the vision-language domain, the researchers demonstrate the potential of MoE approaches to enhance the capabilities of large multimodal models.
Critical Analysis
The researchers provide a thorough evaluation of the MoE-LLaVA approach, including comparisons to state-of-the-art vision-language models on a variety of benchmarks. The results are compelling, showing clear performance improvements across multiple tasks.
However, the paper does not delve deeply into the potential limitations or downsides of the MoE-LLaVA approach. For example, it is unclear how the model's complexity and training requirements scale as the number of experts increases, or how the expert selection process might impact interpretability and transparency.
Additionally, while the paper discusses the benefits of the MoE architecture, it does not provide much insight into how the individual expert models are trained or how their specializations emerge. More details on the training process and the factors that influence expert specialization could help readers better understand the inner workings of the model.
Overall, the MoE-LLaVA approach appears to be a promising direction for improving the performance and efficiency of large vision-language models. However, further research is needed to fully understand the tradeoffs and limitations of this approach, as well as its broader implications for the development of advanced multimodal AI systems.
Conclusion
The MoE-LLaVA paper introduces a novel approach to enhancing the capabilities of large vision-language models by leveraging a Mixture of Experts (MoE) architecture. This modular, specialized design allows the model to dynamically select the most appropriate sub-components to process each input, leading to improved performance and efficiency compared to traditional monolithic models.
The researchers demonstrate the effectiveness of the MoE-LLaVA approach through extensive benchmarking, showing that it outperforms state-of-the-art vision-language models on a range of tasks. This work builds on previous advancements in using MoE techniques to scale up language models and apply them to multimodal domains.
While the paper provides a compelling proof-of-concept, further research is needed to fully understand the tradeoffs and limitations of the MoE-LLaVA approach. Nonetheless, this research represents an important step forward in the development of more capable and efficient large-scale vision-language models, with potential implications for a wide range of AI applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
MoE-LLaVA: Mixture of Experts for Large Vision-Language Models
Bin Lin, Zhenyu Tang, Yang Ye, Jiaxi Cui, Bin Zhu, Peng Jin, Jinfa Huang, Junwu Zhang, Yatian Pang, Munan Ning, Li Yuan
Recent advances demonstrate that scaling Large Vision-Language Models (LVLMs) effectively improves downstream task performances. However, existing scaling methods enable all model parameters to be active for each token in the calculation, which brings massive training and inferring costs. In this work, we propose a simple yet effective training strategy MoE-Tuning for LVLMs. This strategy innovatively addresses the common issue of performance degradation in multi-modal sparsity learning, consequently constructing a sparse model with an outrageous number of parameters but a constant computational cost. Furthermore, we present the MoE-LLaVA, a MoE-based sparse LVLM architecture, which uniquely activates only the top-k experts through routers during deployment, keeping the remaining experts inactive. Extensive experiments show the significant performance of MoE-LLaVA in a variety of visual understanding and object hallucination benchmarks. Remarkably, with only approximately 3B sparsely activated parameters, MoE-LLaVA demonstrates performance comparable to the LLaVA-1.5-7B on various visual understanding datasets and even surpasses the LLaVA-1.5-13B in object hallucination benchmark. Through MoE-LLaVA, we aim to establish a baseline for sparse LVLMs and provide valuable insights for future research in developing more efficient and effective multi-modal learning systems. Code is released at https://github.com/PKU-YuanGroup/MoE-LLaVA.
Read more7/9/2024

0
LLaVA-MoD: Making LLaVA Tiny via MoE Knowledge Distillation
Fangxun Shu, Yue Liao, Le Zhuo, Chenning Xu, Guanghao Zhang, Haonan Shi, Long Chen, Tao Zhong, Wanggui He, Siming Fu, Haoyuan Li, Bolin Li, Zhelun Yu, Si Liu, Hongsheng Li, Hao Jiang
We introduce LLaVA-MoD, a novel framework designed to enable the efficient training of small-scale Multimodal Language Models (s-MLLM) by distilling knowledge from large-scale MLLM (l-MLLM). Our approach tackles two fundamental challenges in MLLM distillation. First, we optimize the network structure of s-MLLM by integrating a sparse Mixture of Experts (MoE) architecture into the language model, striking a balance between computational efficiency and model expressiveness. Second, we propose a progressive knowledge transfer strategy to ensure comprehensive knowledge migration. This strategy begins with mimic distillation, where we minimize the Kullback-Leibler (KL) divergence between output distributions to enable the student model to emulate the teacher network's understanding. Following this, we introduce preference distillation via Direct Preference Optimization (DPO), where the key lies in treating l-MLLM as the reference model. During this phase, the s-MLLM's ability to discriminate between superior and inferior examples is significantly enhanced beyond l-MLLM, leading to a better student that surpasses its teacher, particularly in hallucination benchmarks. Extensive experiments demonstrate that LLaVA-MoD outperforms existing models across various multimodal benchmarks while maintaining a minimal number of activated parameters and low computational costs. Remarkably, LLaVA-MoD, with only 2B activated parameters, surpasses Qwen-VL-Chat-7B by an average of 8.8% across benchmarks, using merely 0.3% of the training data and 23% trainable parameters. These results underscore LLaVA-MoD's ability to effectively distill comprehensive knowledge from its teacher model, paving the way for the development of more efficient MLLMs. The code will be available on: https://github.com/shufangxun/LLaVA-MoD.
Read more8/29/2024
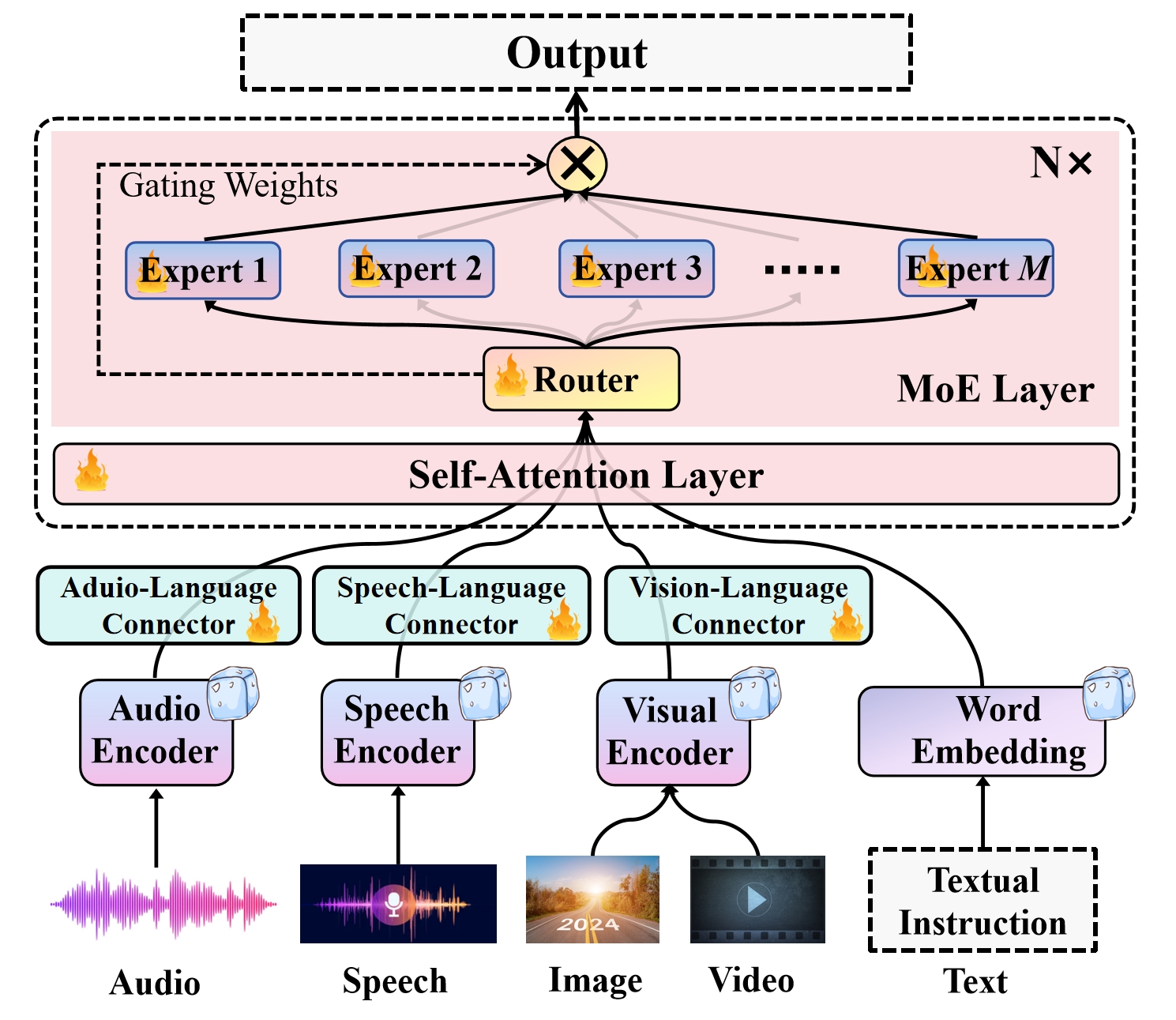
0
Uni-MoE: Scaling Unified Multimodal LLMs with Mixture of Experts
Yunxin Li, Shenyuan Jiang, Baotian Hu, Longyue Wang, Wanqi Zhong, Wenhan Luo, Lin Ma, Min Zhang
Recent advancements in Multimodal Large Language Models (MLLMs) underscore the significance of scalable models and data to boost performance, yet this often incurs substantial computational costs. Although the Mixture of Experts (MoE) architecture has been employed to efficiently scale large language and image-text models, these efforts typically involve fewer experts and limited modalities. To address this, our work presents the pioneering attempt to develop a unified MLLM with the MoE architecture, named Uni-MoE that can handle a wide array of modalities. Specifically, it features modality-specific encoders with connectors for a unified multimodal representation. We also implement a sparse MoE architecture within the LLMs to enable efficient training and inference through modality-level data parallelism and expert-level model parallelism. To enhance the multi-expert collaboration and generalization, we present a progressive training strategy: 1) Cross-modality alignment using various connectors with different cross-modality data, 2) Training modality-specific experts with cross-modality instruction data to activate experts' preferences, and 3) Tuning the Uni-MoE framework utilizing Low-Rank Adaptation (LoRA) on mixed multimodal instruction data. We evaluate the instruction-tuned Uni-MoE on a comprehensive set of multimodal datasets. The extensive experimental results demonstrate Uni-MoE's principal advantage of significantly reducing performance bias in handling mixed multimodal datasets, alongside improved multi-expert collaboration and generalization. Our findings highlight the substantial potential of MoE frameworks in advancing MLLMs and the code is available at https://github.com/HITsz-TMG/UMOE-Scaling-Unified-Multimodal-LLMs.
Read more5/21/2024

0
MoE-TinyMed: Mixture of Experts for Tiny Medical Large Vision-Language Models
Songtao Jiang, Tuo Zheng, Yan Zhang, Yeying Jin, Li Yuan, Zuozhu Liu
Recent advancements in general-purpose or domain-specific multimodal large language models (LLMs) have witnessed remarkable progress for medical decision-making. However, they are designated for specific classification or generative tasks, and require model training or finetuning on large-scale datasets with sizeable parameters and tremendous computing, hindering their clinical utility across diverse resource-constrained scenarios in practice. In this paper, we propose a novel and lightweight framework Med-MoE (Mixture-of-Experts) that tackles both discriminative and generative multimodal medical tasks. The learning of Med-MoE consists of three steps: multimodal medical alignment, instruction tuning and routing, and domain-specific MoE tuning. After aligning multimodal medical images with LLM tokens, we then enable the model for different multimodal medical tasks with instruction tuning, together with a trainable router tailored for expert selection across input modalities. Finally, the model is tuned by integrating the router with multiple domain-specific experts, which are selectively activated and further empowered by meta expert. Comprehensive experiments on both open- and close-end medical question answering (Med-VQA) and image classification tasks across datasets such as VQA-RAD, SLAKE and Path-VQA demonstrate that our model can achieve performance superior to or on par with state-of-the-art baselines, while only requiring approximately 30%-50% of activated model parameters. Extensive analysis and ablations corroborate the effectiveness and practical utility of our method.
Read more9/4/2024