MolecularGPT: Open Large Language Model (LLM) for Few-Shot Molecular Property Prediction

0

Sign in to get full access
Overview
- MolecularGPT: Open Large Language Model (LLM) for Few-Shot Molecular Property Prediction
- Presents an open-source, large language model called MolecularGPT that can perform few-shot learning for molecular property prediction tasks
- Demonstrates the model's capabilities on a range of molecular tasks, including property prediction, molecule generation, and molecular optimization
Plain English Explanation
MolecularGPT is a powerful AI model that can learn to predict the properties of molecules with just a few examples. This is useful for drug discovery and other fields where we need to understand the behavior of molecules.
The researchers who developed MolecularGPT wanted to create an open-source model that anyone can use, rather than a proprietary model that is hard to access. They trained the model on a huge amount of data about molecules, so it has a deep understanding of how they behave.
When you give MolecularGPT a few examples of a certain type of molecule, it can quickly learn to predict the properties of other similar molecules. This "few-shot learning" capability is really valuable because it means you don't need huge datasets to train the model - just a few examples can get it started.
The researchers tested MolecularGPT on a variety of molecular tasks, like predicting properties, generating new molecules, and optimizing the properties of existing molecules. The model performed very well, showing that it has learned a lot about the fundamental rules that govern molecular behavior.
Overall, MolecularGPT is an exciting development that could help speed up drug discovery and other chemical research by making it easier to understand how molecules work. The fact that it's open-source means that scientists and researchers around the world can use and improve it.
Technical Explanation
The researchers present MolecularGPT, an open-source, large language model (LLM) trained on a massive dataset of molecular data. The model is designed for few-shot learning, meaning it can quickly adapt to new molecular property prediction tasks using just a small number of examples.
To train MolecularGPT, the researchers used a novel self-supervised pretraining approach, where the model learns to predict the next token in a sequence of molecular representations. This allows the model to build a deep understanding of the underlying chemical rules and patterns in the data.
The researchers then evaluate MolecularGPT on a range of molecular tasks, including property prediction, molecule generation, and molecular optimization. They demonstrate the model's strong few-shot learning capabilities, as well as its ability to explain its predictions in an interpretable way.
Critical Analysis
The researchers acknowledge several limitations of MolecularGPT. For example, the model's performance may be biased by the training data, which may not fully capture the diversity of molecular structures and properties. Additionally, the researchers note that the model's interpretability, while improved compared to black-box models, could be further enhanced.
Future research could explore ways to make MolecularGPT more robust and generalizable, such as by incorporating additional data sources or developing novel training techniques. Additionally, the researchers suggest that the model could be extended to handle more complex molecular tasks, such as reaction prediction and retrosynthesis.
Overall, MolecularGPT represents an important step forward in the development of open, few-shot learning models for molecular property prediction. By making the model freely available, the researchers are enabling wider access and continued improvement by the research community.
Conclusion
MolecularGPT is a groundbreaking open-source model that can rapidly learn to predict the properties of molecules using just a few examples. This capability has the potential to accelerate drug discovery and other areas of chemical research by making it easier to understand how molecules behave.
The researchers have demonstrated the model's strong performance on a range of molecular tasks, and have made the model freely available for others to use and build upon. While the model has some limitations, the researchers have identified several avenues for future research to address these challenges.
Overall, MolecularGPT represents an exciting advancement in the field of few-shot learning for molecular property prediction, and its open-source nature may lead to further innovations and breakthroughs in this important area of scientific research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MolecularGPT: Open Large Language Model (LLM) for Few-Shot Molecular Property Prediction
Yuyan Liu, Sirui Ding, Sheng Zhou, Wenqi Fan, Qiaoyu Tan
Molecular property prediction (MPP) is a fundamental and crucial task in drug discovery. However, prior methods are limited by the requirement for a large number of labeled molecules and their restricted ability to generalize for unseen and new tasks, both of which are essential for real-world applications. To address these challenges, we present MolecularGPT for few-shot MPP. From a perspective on instruction tuning, we fine-tune large language models (LLMs) based on curated molecular instructions spanning over 1000 property prediction tasks. This enables building a versatile and specialized LLM that can be adapted to novel MPP tasks without any fine-tuning through zero- and few-shot in-context learning (ICL). MolecularGPT exhibits competitive in-context reasoning capabilities across 10 downstream evaluation datasets, setting new benchmarks for few-shot molecular prediction tasks. More importantly, with just two-shot examples, MolecularGPT can outperform standard supervised graph neural network methods on 4 out of 7 datasets. It also excels state-of-the-art LLM baselines by up to 16.6% increase on classification accuracy and decrease of 199.17 on regression metrics (e.g., RMSE) under zero-shot. This study demonstrates the potential of LLMs as effective few-shot molecular property predictors. The code is available at https://github.com/NYUSHCS/MolecularGPT.
Read more6/21/2024
0
DrugLLM: Open Large Language Model for Few-shot Molecule Generation
Xianggen Liu, Yan Guo, Haoran Li, Jin Liu, Shudong Huang, Bowen Ke, Jiancheng Lv
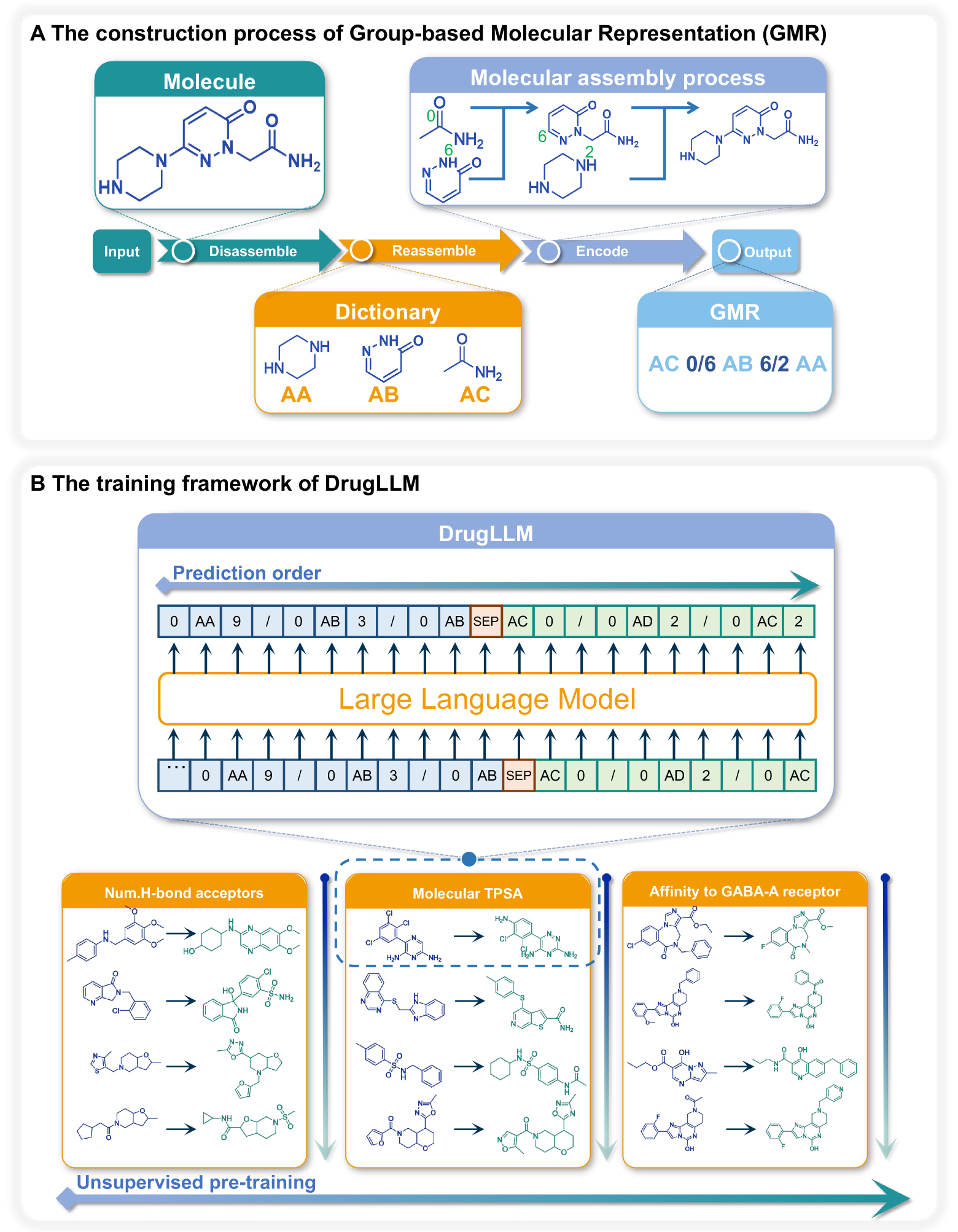
Large Language Models (LLMs) have made great strides in areas such as language processing and computer vision. Despite the emergence of diverse techniques to improve few-shot learning capacity, current LLMs fall short in handling the languages in biology and chemistry. For example, they are struggling to capture the relationship between molecule structure and pharmacochemical properties. Consequently, the few-shot learning capacity of small-molecule drug modification remains impeded. In this work, we introduced DrugLLM, a LLM tailored for drug design. During the training process, we employed Group-based Molecular Representation (GMR) to represent molecules, arranging them in sequences that reflect modifications aimed at enhancing specific molecular properties. DrugLLM learns how to modify molecules in drug discovery by predicting the next molecule based on past modifications. Extensive computational experiments demonstrate that DrugLLM can generate new molecules with expected properties based on limited examples, presenting a powerful few-shot molecule generation capacity.
Read more5/14/2024

0
Empowering Molecule Discovery for Molecule-Caption Translation with Large Language Models: A ChatGPT Perspective
Jiatong Li, Yunqing Liu, Wenqi Fan, Xiao-Yong Wei, Hui Liu, Jiliang Tang, Qing Li
Molecule discovery plays a crucial role in various scientific fields, advancing the design of tailored materials and drugs. However, most of the existing methods heavily rely on domain experts, require excessive computational cost, or suffer from sub-optimal performance. On the other hand, Large Language Models (LLMs), like ChatGPT, have shown remarkable performance in various cross-modal tasks due to their powerful capabilities in natural language understanding, generalization, and in-context learning (ICL), which provides unprecedented opportunities to advance molecule discovery. Despite several previous works trying to apply LLMs in this task, the lack of domain-specific corpus and difficulties in training specialized LLMs still remain challenges. In this work, we propose a novel LLM-based framework (MolReGPT) for molecule-caption translation, where an In-Context Few-Shot Molecule Learning paradigm is introduced to empower molecule discovery with LLMs like ChatGPT to perform their in-context learning capability without domain-specific pre-training and fine-tuning. MolReGPT leverages the principle of molecular similarity to retrieve similar molecules and their text descriptions from a local database to enable LLMs to learn the task knowledge from context examples. We evaluate the effectiveness of MolReGPT on molecule-caption translation, including molecule understanding and text-based molecule generation. Experimental results show that compared to fine-tuned models, MolReGPT outperforms MolT5-base and is comparable to MolT5-large without additional training. To the best of our knowledge, MolReGPT is the first work to leverage LLMs via in-context learning in molecule-caption translation for advancing molecule discovery. Our work expands the scope of LLM applications, as well as providing a new paradigm for molecule discovery and design.
Read more4/23/2024

0
Cross-Modal Learning for Chemistry Property Prediction: Large Language Models Meet Graph Machine Learning
Sakhinana Sagar Srinivas, Venkataramana Runkana
In the field of chemistry, the objective is to create novel molecules with desired properties, facilitating accurate property predictions for applications such as material design and drug screening. However, existing graph deep learning methods face limitations that curb their expressive power. To address this, we explore the integration of vast molecular domain knowledge from Large Language Models (LLMs) with the complementary strengths of Graph Neural Networks (GNNs) to enhance performance in property prediction tasks. We introduce a Multi-Modal Fusion (MMF) framework that synergistically harnesses the analytical prowess of GNNs and the linguistic generative and predictive abilities of LLMs, thereby improving accuracy and robustness in predicting molecular properties. Our framework combines the effectiveness of GNNs in modeling graph-structured data with the zero-shot and few-shot learning capabilities of LLMs, enabling improved predictions while reducing the risk of overfitting. Furthermore, our approach effectively addresses distributional shifts, a common challenge in real-world applications, and showcases the efficacy of learning cross-modal representations, surpassing state-of-the-art baselines on benchmark datasets for property prediction tasks.
Read more8/28/2024