Momentum-Based Federated Reinforcement Learning with Interaction and Communication Efficiency

0
Sign in to get full access
Overview
- This paper proposes a new federated reinforcement learning (FRL) algorithm called Momentum-Based Federated Reinforcement Learning (MFRL) that aims to improve interaction and communication efficiency.
- The key ideas are to leverage momentum-based optimization and to reduce the number of interactions and communications between the central server and client agents.
- The paper compares MFRL to other FRL approaches and demonstrates its performance on various reinforcement learning tasks.
Plain English Explanation
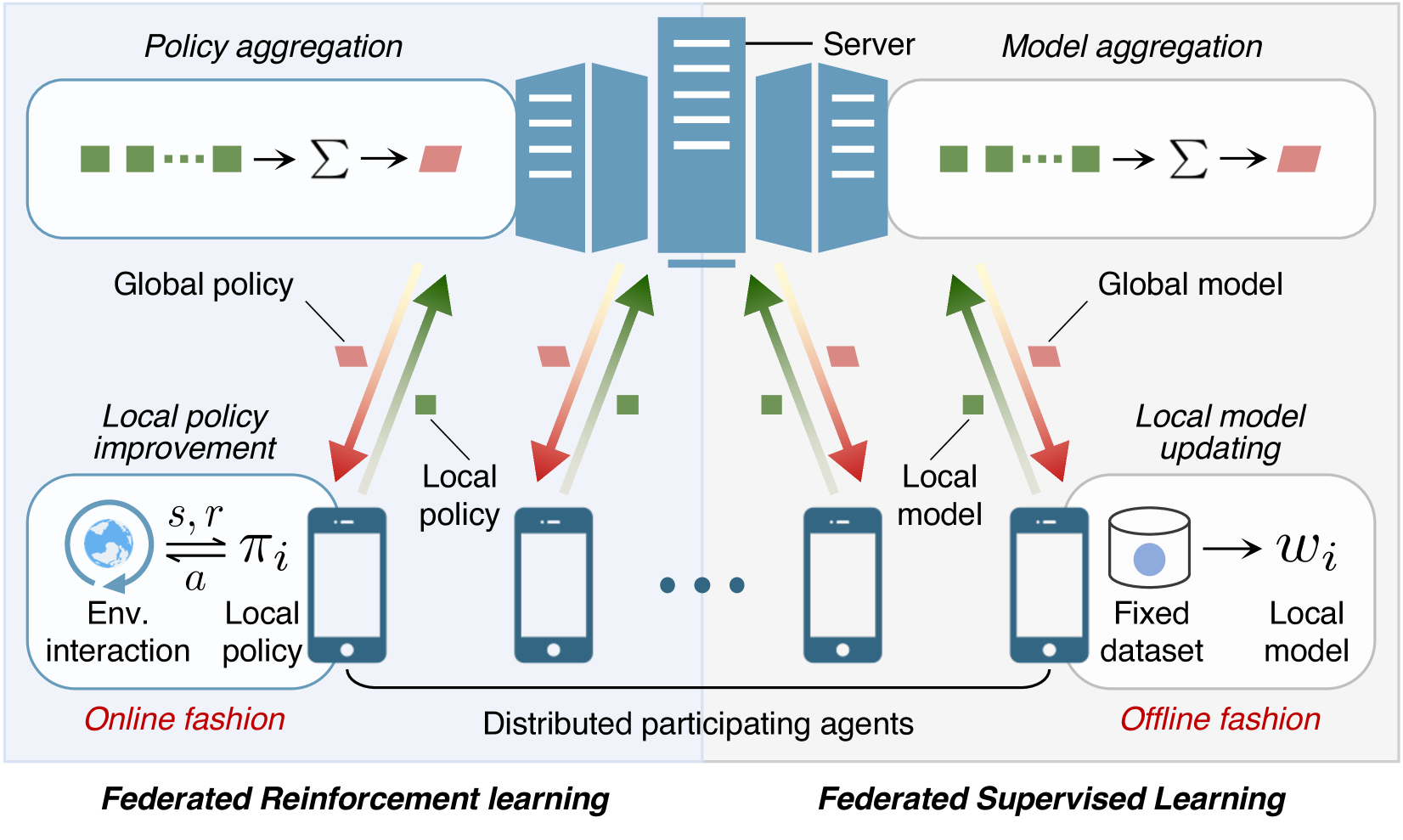
Reinforcement learning is a type of machine learning where software agents learn by interacting with their environment and receiving rewards or punishments for their actions. Federated reinforcement learning is a version of this where multiple agents work together, coordinated by a central server, to learn a shared policy.
The challenge with federated reinforcement learning is that the agents need to frequently communicate with the central server, which can be slow and costly. This paper introduces a new algorithm called Momentum-Based Federated Reinforcement Learning (MFRL) that aims to reduce the number of interactions and communications required.
The key idea is to use a "momentum" term, similar to what is used in some optimization algorithms. This allows the agents to make progress locally without needing to communicate as often with the central server. The paper shows that this can improve the overall efficiency and performance of the federated reinforcement learning system.
Technical Explanation
The paper proposes a new federated reinforcement learning (FRL) algorithm called Momentum-Based Federated Reinforcement Learning (MFRL). The core idea is to leverage momentum-based optimization to reduce the number of interactions and communications required between the central server and client agents.
Typical FRL approaches require frequent synchronization between the server and agents, which can be slow and costly. MFRL addresses this by incorporating a momentum term into the optimization process. This allows the agents to make progress locally without needing to communicate as often with the server.
The paper provides a detailed mathematical formulation of the MFRL algorithm and analyzes its theoretical properties. They show that MFRL can achieve better sample and communication efficiency compared to other FRL methods like FedRL and HFRL.
The authors also conduct extensive experiments on a variety of reinforcement learning benchmarks, including compressed federated reinforcement learning, finite-time analysis of policy learning in heterogeneous federated reinforcement learning, and federated combinatorial multi-agent multi-armed bandits. The results demonstrate the improved performance and efficiency of MFRL compared to baseline approaches.
Critical Analysis
The paper provides a well-designed and thorough evaluation of the proposed MFRL algorithm. The authors carefully compare it to relevant baselines and demonstrate its advantages across multiple benchmarks.
One potential limitation is that the analysis is primarily focused on improving the interaction and communication efficiency, rather than the final task performance. It would be interesting to see how MFRL compares to other FRL methods in terms of the ultimate learning outcomes, especially on more complex or real-world reinforcement learning problems.
Additionally, the paper does not deeply explore the potential drawbacks or failure modes of the momentum-based approach. For example, it's unclear how MFRL would behave in scenarios with high agent heterogeneity or non-stationary environments, where the momentum term might hinder the agents' ability to adapt.
Overall, this is a promising piece of research that makes a meaningful contribution to the field of federated reinforcement learning. The ideas presented here could potentially be extended or combined with other techniques to further enhance the efficiency and performance of federated learning systems.
Conclusion
This paper introduces a new federated reinforcement learning algorithm called Momentum-Based Federated Reinforcement Learning (MFRL) that aims to improve interaction and communication efficiency. The key innovation is the incorporation of a momentum term into the optimization process, which allows the client agents to make progress locally without needing to communicate as often with the central server.
The paper provides a thorough theoretical and empirical analysis of MFRL, demonstrating its advantages over other FRL approaches in terms of sample and communication efficiency. The results suggest that MFRL could be a valuable tool for building more scalable and practical federated reinforcement learning systems, with potential applications in areas like multi-agent robotics, personalized recommendation systems, and edge computing.
While the paper focuses primarily on improving the efficiency of the learning process, further research is needed to fully understand the implications of the momentum-based approach, especially in more complex or dynamic environments. Nevertheless, this work represents an important step forward in the field of federated reinforcement learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Momentum-Based Federated Reinforcement Learning with Interaction and Communication Efficiency
Sheng Yue, Xingyuan Hua, Lili Chen, Ju Ren
Federated Reinforcement Learning (FRL) has garnered increasing attention recently. However, due to the intrinsic spatio-temporal non-stationarity of data distributions, the current approaches typically suffer from high interaction and communication costs. In this paper, we introduce a new FRL algorithm, named $texttt{MFPO}$, that utilizes momentum, importance sampling, and additional server-side adjustment to control the shift of stochastic policy gradients and enhance the efficiency of data utilization. We prove that by proper selection of momentum parameters and interaction frequency, $texttt{MFPO}$ can achieve $tilde{mathcal{O}}(H N^{-1}epsilon^{-3/2})$ and $tilde{mathcal{O}}(epsilon^{-1})$ interaction and communication complexities ($N$ represents the number of agents), where the interaction complexity achieves linear speedup with the number of agents, and the communication complexity aligns the best achievable of existing first-order FL algorithms. Extensive experiments corroborate the substantial performance gains of $texttt{MFPO}$ over existing methods on a suite of complex and high-dimensional benchmarks.
Read more5/30/2024

0
Momentum for the Win: Collaborative Federated Reinforcement Learning across Heterogeneous Environments
Han Wang, Sihong He, Zhili Zhang, Fei Miao, James Anderson
We explore a Federated Reinforcement Learning (FRL) problem where $N$ agents collaboratively learn a common policy without sharing their trajectory data. To date, existing FRL work has primarily focused on agents operating in the same or ``similar environments. In contrast, our problem setup allows for arbitrarily large levels of environment heterogeneity. To obtain the optimal policy which maximizes the average performance across all potentially completely different environments, we propose two algorithms: FedSVRPG-M and FedHAPG-M. In contrast to existing results, we demonstrate that both FedSVRPG-M and FedHAPG-M, both of which leverage momentum mechanisms, can exactly converge to a stationary point of the average performance function, regardless of the magnitude of environment heterogeneity. Furthermore, by incorporating the benefits of variance-reduction techniques or Hessian approximation, both algorithms achieve state-of-the-art convergence results, characterized by a sample complexity of $mathcal{O}left(epsilon^{-frac{3}{2}}/Nright)$. Notably, our algorithms enjoy linear convergence speedups with respect to the number of agents, highlighting the benefit of collaboration among agents in finding a common policy.
Read more5/31/2024
🏅
0
Compressed Federated Reinforcement Learning with a Generative Model
Ali Beikmohammadi, Sarit Khirirat, Sindri Magn'usson
Reinforcement learning has recently gained unprecedented popularity, yet it still grapples with sample inefficiency. Addressing this challenge, federated reinforcement learning (FedRL) has emerged, wherein agents collaboratively learn a single policy by aggregating local estimations. However, this aggregation step incurs significant communication costs. In this paper, we propose CompFedRL, a communication-efficient FedRL approach incorporating both textit{periodic aggregation} and (direct/error-feedback) compression mechanisms. Specifically, we consider compressed federated $Q$-learning with a generative model setup, where a central server learns an optimal $Q$-function by periodically aggregating compressed $Q$-estimates from local agents. For the first time, we characterize the impact of these two mechanisms (which have remained elusive) by providing a finite-time analysis of our algorithm, demonstrating strong convergence behaviors when utilizing either direct or error-feedback compression. Our bounds indicate improved solution accuracy concerning the number of agents and other federated hyperparameters while simultaneously reducing communication costs. To corroborate our theory, we also conduct in-depth numerical experiments to verify our findings, considering Top-$K$ and Sparsified-$K$ sparsification operators.
Read more8/28/2024

0
Finite-Time Analysis of On-Policy Heterogeneous Federated Reinforcement Learning
Chenyu Zhang, Han Wang, Aritra Mitra, James Anderson
Federated reinforcement learning (FRL) has emerged as a promising paradigm for reducing the sample complexity of reinforcement learning tasks by exploiting information from different agents. However, when each agent interacts with a potentially different environment, little to nothing is known theoretically about the non-asymptotic performance of FRL algorithms. The lack of such results can be attributed to various technical challenges and their intricate interplay: Markovian sampling, linear function approximation, multiple local updates to save communication, heterogeneity in the reward functions and transition kernels of the agents' MDPs, and continuous state-action spaces. Moreover, in the on-policy setting, the behavior policies vary with time, further complicating the analysis. In response, we introduce FedSARSA, a novel federated on-policy reinforcement learning scheme, equipped with linear function approximation, to address these challenges and provide a comprehensive finite-time error analysis. Notably, we establish that FedSARSA converges to a policy that is near-optimal for all agents, with the extent of near-optimality proportional to the level of heterogeneity. Furthermore, we prove that FedSARSA leverages agent collaboration to enable linear speedups as the number of agents increases, which holds for both fixed and adaptive step-size configurations.
Read more4/16/2024