MoNDE: Mixture of Near-Data Experts for Large-Scale Sparse Models

0

Sign in to get full access
Overview
- The paper proposes a novel model architecture called MoNDE (Mixture of Near-Data Experts) for efficient inference of large-scale sparse models.
- MoNDE leverages the concept of Mixture of Experts (MoE) to distribute the computation across multiple specialized "experts" and selectively activate the most relevant experts for a given input.
- The key innovation is the "near-data" aspect, where the experts are placed close to the data sources to minimize data movement and maximize computational efficiency.
Plain English Explanation
The paper introduces a new way to run large, complex machine learning models more efficiently. These types of models, known as "sparse models," can have billions of parameters and require a lot of computing power to use.
MoNDE works by dividing up the model into smaller "expert" components, each of which specializes in a different part of the problem. When you need to use the model, it selects the most relevant experts for that particular input, rather than running the entire model. This makes the process faster and more efficient.
The key insight is that the expert components should be placed physically close to the data they need to operate on. This minimizes the amount of data that needs to be moved around, which is often a major bottleneck in running these large models. By keeping the experts and data together, MoNDE can run much more efficiently.
Technical Explanation
The paper proposes a Mixture of Near-Data Experts (MoNDE) architecture to address the challenges of efficient inference for large-scale sparse models. MoNDE builds on the Mixture of Experts (MoE) paradigm, where the model is divided into multiple specialized "expert" components that are selectively activated based on the input.
The key innovation in MoNDE is the "near-data" aspect, where the expert components are placed in close proximity to the data sources. This minimizes the data movement required during inference, a major bottleneck in running large sparse models. MoNDE also incorporates techniques like pre-gating and sparsity-aware routing to further optimize the inference process.
The paper evaluates MoNDE on large-scale language and recommendation tasks, demonstrating significant improvements in inference latency and throughput compared to baseline approaches. The authors also explore the trade-offs between dense training and sparse inference and the implications for optimal mixture of experts design.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the MoNDE architecture, exploring its performance across a range of large-scale tasks and settings. The authors acknowledge some limitations, such as the potential need for specialized hardware or infrastructure to fully realize the benefits of the near-data placement.
One area for further exploration could be the impact of the expert specialization on model interpretability and explainability. While the selective activation of experts can improve efficiency, it may also introduce challenges in understanding the model's decision-making process, particularly for complex, high-stakes applications.
Additionally, the paper does not delve deeply into the potential energy or environmental implications of the MoNDE approach. As large language models and recommendation systems become increasingly power-hungry, it will be important to consider the sustainability and carbon footprint of such architectures.
Overall, the MoNDE paper presents a promising direction for improving the efficiency of large-scale sparse models, with the potential to unlock new capabilities and applications. However, as with any research, there are opportunities to further refine and expand upon the ideas to address emerging challenges and concerns.
Conclusion
The MoNDE paper introduces a novel architecture for efficient inference of large-scale sparse models, leveraging the Mixture of Experts (MoE) paradigm and the concept of "near-data" placement of expert components. By minimizing data movement and selectively activating the most relevant experts, MoNDE demonstrates significant improvements in inference latency and throughput compared to traditional approaches.
The research highlights the importance of carefully designing model architectures and deployment strategies to address the growing computational demands of large-scale machine learning. As the field continues to push the boundaries of model size and complexity, innovative solutions like MoNDE will be crucial in making these powerful models more practical and accessible for real-world applications.
While the paper presents a strong technical contribution, there are also important considerations around model interpretability, energy efficiency, and broader societal impacts that warrant further exploration. By addressing these challenges, the research community can ensure that advances in large-scale sparse modeling truly benefit society and align with our ethical principles.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MoNDE: Mixture of Near-Data Experts for Large-Scale Sparse Models
Taehyun Kim, Kwanseok Choi, Youngmock Cho, Jaehoon Cho, Hyuk-Jae Lee, Jaewoong Sim
Mixture-of-Experts (MoE) large language models (LLM) have memory requirements that often exceed the GPU memory capacity, requiring costly parameter movement from secondary memories to the GPU for expert computation. In this work, we present Mixture of Near-Data Experts (MoNDE), a near-data computing solution that efficiently enables MoE LLM inference. MoNDE reduces the volume of MoE parameter movement by transferring only the $textit{hot}$ experts to the GPU, while computing the remaining $textit{cold}$ experts inside the host memory device. By replacing the transfers of massive expert parameters with the ones of small activations, MoNDE enables far more communication-efficient MoE inference, thereby resulting in substantial speedups over the existing parameter offloading frameworks for both encoder and decoder operations.
Read more5/30/2024
0
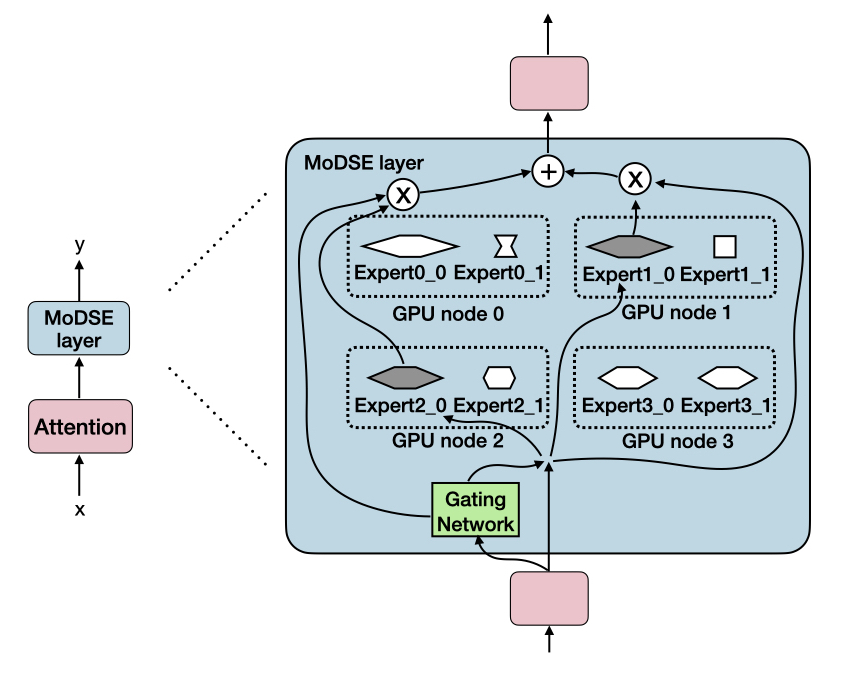
Mixture of Diverse Size Experts
Manxi Sun, Wei Liu, Jian Luan, Pengzhi Gao, Bin Wang
The Sparsely-Activated Mixture-of-Experts (MoE) has gained increasing popularity for scaling up large language models (LLMs) without exploding computational costs. Despite its success, the current design faces a challenge where all experts have the same size, limiting the ability of tokens to choose the experts with the most appropriate size for generating the next token. In this paper, we propose the Mixture of Diverse Size Experts (MoDSE), a new MoE architecture with layers designed to have experts of different sizes. Our analysis of difficult token generation tasks shows that experts of various sizes achieve better predictions, and the routing path of the experts tends to be stable after a training period. However, having experts of diverse sizes can lead to uneven workload distribution. To tackle this limitation, we introduce an expert-pair allocation strategy to evenly distribute the workload across multiple GPUs. Comprehensive evaluations across multiple benchmarks demonstrate the effectiveness of MoDSE, as it outperforms existing MoEs by allocating the parameter budget to experts adaptively while maintaining the same total parameter size and the number of experts.
Read more9/20/2024
💬
0
SwapMoE: Serving Off-the-shelf MoE-based Language Models with Tunable Memory Budget
Rui Kong, Yuanchun Li, Qingtian Feng, Weijun Wang, Xiaozhou Ye, Ye Ouyang, Linghe Kong, Yunxin Liu
Mixture of experts (MoE) is a popular technique to improve capacity of Large Language Models (LLMs) with conditionally-activated parallel experts. However, serving MoE models on memory-constrained devices is challenging due to the large parameter size. Typical solutions such as memory swapping or expert pruning may lead to significantly higher latency or severe accuracy loss. In this paper, we introduce SwapMoE, a framework for efficient serving of MoE-based large language models with tunable memory budgets. The main idea of SwapMoE is to keep a small dynamic set of important experts, namely Virtual Experts, in the main memory for inference, while seamlessly maintaining how the Virtual Experts map to the actual experts. Experiments have shown that SwapMoE can reduce the memory footprint while maintaining reasonable accuracy. For example, on text summarization tasks with Switch Transformer, SwapMoE can reduce the memory consumption from 14.2 GiB to 4.7 GiB, together with 50% latency reduction and a slight Rouge-2 score drop of 0.041.
Read more5/30/2024
🏅
0
SiDA-MoE: Sparsity-Inspired Data-Aware Serving for Efficient and Scalable Large Mixture-of-Experts Models
Zhixu Du, Shiyu Li, Yuhao Wu, Xiangyu Jiang, Jingwei Sun, Qilin Zheng, Yongkai Wu, Ang Li, Hai Helen Li, Yiran Chen
Mixture-of-Experts (MoE) has emerged as a favorable architecture in the era of large models due to its inherent advantage, i.e., enlarging model capacity without incurring notable computational overhead. Yet, the realization of such benefits often results in ineffective GPU memory utilization, as large portions of the model parameters remain dormant during inference. Moreover, the memory demands of large models consistently outpace the memory capacity of contemporary GPUs. Addressing this, we introduce SiDA-MoE ($textbf{S}$parsity-$textbf{i}$nspired $textbf{D}$ata-$textbf{A}$ware), an efficient inference approach tailored for large MoE models. SiDA-MoE judiciously exploits both the system's main memory, which is now abundant and readily scalable, and GPU memory by capitalizing on the inherent sparsity on expert activation in MoE models. By adopting a data-aware perspective, SiDA-MoE achieves enhanced model efficiency with a neglectable performance drop. Specifically, SiDA-MoE attains a remarkable speedup in MoE inference with up to $3.93times$ throughput increasing, up to $72%$ latency reduction, and up to $80%$ GPU memory saving with down to $1%$ performance drop. This work paves the way for scalable and efficient deployment of large MoE models, even with constrained resources. Code is available at: https://github.com/timlee0212/SiDA-MoE.
Read more5/21/2024