MorpheuS: Neural Dynamic 360{deg} Surface Reconstruction from Monocular RGB-D Video

0

Sign in to get full access
Overview
- This paper presents MorpheuS, a neural network system for reconstructing 360-degree surfaces from monocular RGB-D video.
- The system can capture dynamic 3D scenes in high detail by combining information from color and depth data.
- It uses a novel neural network architecture to efficiently process video frames and produce a continuously updating 3D surface model.
Plain English Explanation
MorpheuS is a new technology that can create detailed 3D models of the world around us using just a single video camera. Unlike traditional 3D scanning methods that require multiple cameras or depth sensors, MorpheuS can reconstruct 360-degree surfaces from a single RGB-D (color and depth) video.
The key innovation is the neural network architecture that powers MorpheuS. This neural network is able to efficiently process each video frame and update the 3D model in real-time as the camera moves. This allows MorpheuS to capture dynamic scenes, like a person moving around a room, in high detail.
The system combines the color information from the video with the depth data to build a complete 3D representation of the environment. This 3D model can be used for a variety of applications, such as virtual reality, robotics, or 3D content creation.
Compared to other 3D reconstruction methods, MorpheuS stands out by its ability to work with a single camera and generate detailed, continuously updating 3D models. This makes it a practical solution for many real-world scenarios where traditional 3D scanning is not feasible.
Technical Explanation
MorpheuS uses a novel neural network architecture to efficiently process monocular RGB-D video and reconstruct a continuously updating 3D surface model. The key components are:
- Feature Extraction: The system extracts visual features from each video frame using a convolutional neural network.
- Temporal Fusion: The features are combined with information from previous frames using a recurrent neural network to capture the dynamic nature of the scene.
- Geometry Prediction: The fused features are used to predict the 3D geometry of the scene, including surface normals and depth maps.
- Mesh Generation: The predicted geometry is converted into a 3D mesh representation that can be updated over time as the camera moves.
The system is trained end-to-end on a large dataset of RGB-D videos, allowing it to learn how to effectively integrate color and depth information to produce high-quality 3D reconstructions.
Critical Analysis
The paper provides a thorough evaluation of the MorpheuS system, demonstrating its ability to outperform previous methods in terms of reconstruction quality and efficiency. However, there are a few aspects that could be explored further:
- The system is limited to reconstructing static scenes, and extending it to handle dynamic, moving objects could be an important next step.
- The paper does not deeply investigate the types of scenes or environments where MorpheuS performs best or struggles the most. Understanding these limitations is crucial for real-world applications.
- While the neural network architecture is novel, the authors do not provide much insight into the specific design choices and how they impact the system's performance.
Overall, MorpheuS represents an impressive advance in single-camera 3D reconstruction, but additional research is needed to fully understand its capabilities and limitations.
Conclusion
MorpheuS introduces a powerful neural network-based system for reconstructing detailed 360-degree 3D surfaces from monocular RGB-D video. By combining color and depth information in a novel way, the system can capture dynamic scenes with high fidelity, making it a promising tool for a variety of applications. While the paper highlights the system's strengths, further research is needed to explore its limitations and potential extensions. Nonetheless, MorpheuS demonstrates the potential of deep learning to revolutionize 3D reconstruction from a single camera.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MorpheuS: Neural Dynamic 360{deg} Surface Reconstruction from Monocular RGB-D Video
Hengyi Wang, Jingwen Wang, Lourdes Agapito
Neural rendering has demonstrated remarkable success in dynamic scene reconstruction. Thanks to the expressiveness of neural representations, prior works can accurately capture the motion and achieve high-fidelity reconstruction of the target object. Despite this, real-world video scenarios often feature large unobserved regions where neural representations struggle to achieve realistic completion. To tackle this challenge, we introduce MorpheuS, a framework for dynamic 360{deg} surface reconstruction from a casually captured RGB-D video. Our approach models the target scene as a canonical field that encodes its geometry and appearance, in conjunction with a deformation field that warps points from the current frame to the canonical space. We leverage a view-dependent diffusion prior and distill knowledge from it to achieve realistic completion of unobserved regions. Experimental results on various real-world and synthetic datasets show that our method can achieve high-fidelity 360{deg} surface reconstruction of a deformable object from a monocular RGB-D video.
Read more4/5/2024
0
High-Fidelity Mask-free Neural Surface Reconstruction for Virtual Reality
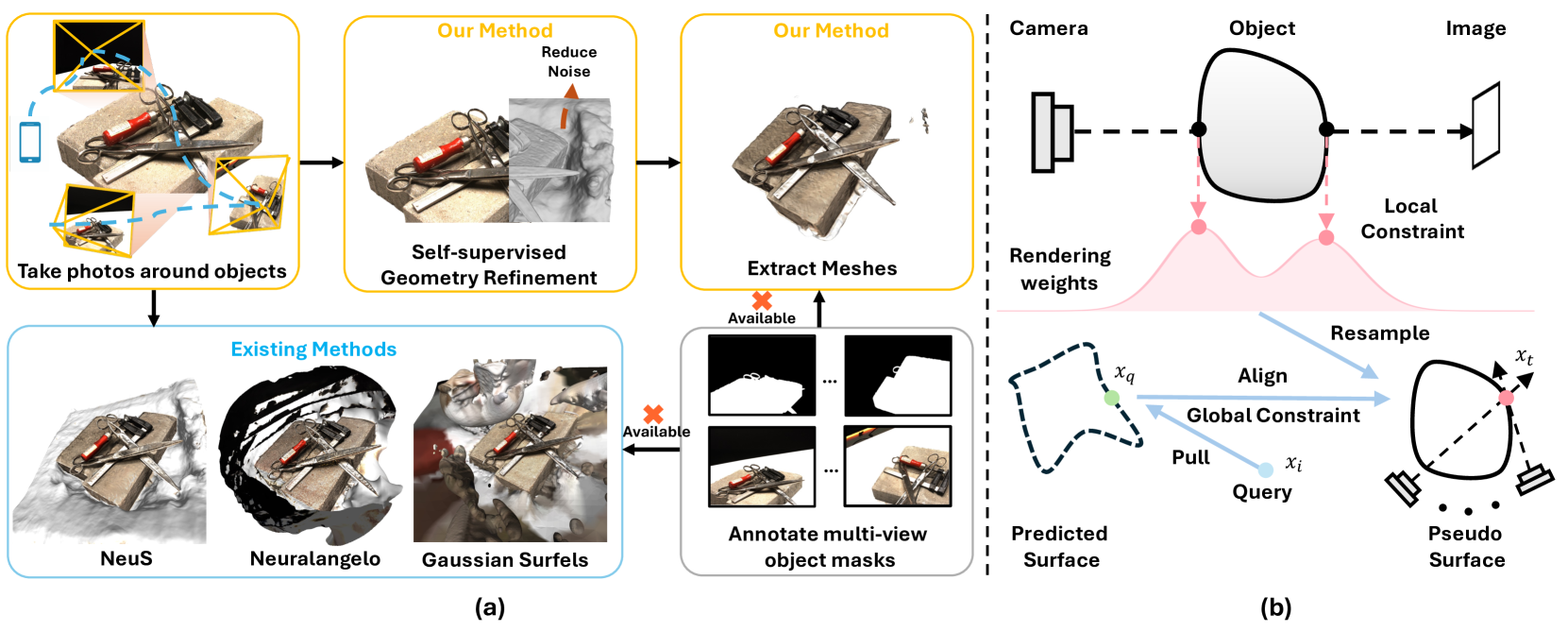
Haotian Bai, Yize Chen, Lin Wang
Object-centric surface reconstruction from multi-view images is crucial in creating editable digital assets for AR/VR. Due to the lack of geometric constraints, existing methods, e.g., NeuS necessitate annotating the object masks to reconstruct compact surfaces in mesh processing. Mask annotation, however, incurs considerable labor costs due to its cumbersome nature. This paper presents Hi-NeuS, a novel rendering-based framework for neural implicit surface reconstruction, aiming to recover compact and precise surfaces without multi-view object masks. Our key insight is that the overlapping regions in the object-centric views naturally highlight the object of interest as the camera orbits around objects. The object of interest can be specified by estimating the distribution of the rendering weights accumulated from multiple views, which implicitly identifies the surface that a user intends to capture. This inspires us to design a geometric refinement approach, which takes multi-view rendering weights to guide the signed distance functions (SDF) of neural surfaces in a self-supervised manner. Specifically, it retains these weights to resample a pseudo surface based on their distribution. This facilitates the alignment of the SDF to the object of interest. We then regularize the SDF's bias for geometric consistency. Moreover, we propose to use unmasked Chamfer Distance(CD) to measure the extracted mesh without post-processing for more precise evaluation. Our approach has been validated through NeuS and its variant Neuralangelo, demonstrating its adaptability across different NeuS backbones. Extensive benchmark on the DTU dataset shows that our method reduces surface noise by about 20%, and improves the unmasked CD by around 30%, achieving better surface details. The superiority of Hi-NeuS is further validated on BlendedMVS and handheld camera captures for content creation.
Read more9/23/2024

0
Shape of Motion: 4D Reconstruction from a Single Video
Qianqian Wang, Vickie Ye, Hang Gao, Jake Austin, Zhengqi Li, Angjoo Kanazawa
Monocular dynamic reconstruction is a challenging and long-standing vision problem due to the highly ill-posed nature of the task. Existing approaches are limited in that they either depend on templates, are effective only in quasi-static scenes, or fail to model 3D motion explicitly. In this work, we introduce a method capable of reconstructing generic dynamic scenes, featuring explicit, full-sequence-long 3D motion, from casually captured monocular videos. We tackle the under-constrained nature of the problem with two key insights: First, we exploit the low-dimensional structure of 3D motion by representing scene motion with a compact set of SE3 motion bases. Each point's motion is expressed as a linear combination of these bases, facilitating soft decomposition of the scene into multiple rigidly-moving groups. Second, we utilize a comprehensive set of data-driven priors, including monocular depth maps and long-range 2D tracks, and devise a method to effectively consolidate these noisy supervisory signals, resulting in a globally consistent representation of the dynamic scene. Experiments show that our method achieves state-of-the-art performance for both long-range 3D/2D motion estimation and novel view synthesis on dynamic scenes. Project Page: https://shape-of-motion.github.io/
Read more7/19/2024

0
RNb-NeuS: Reflectance and Normal-based Multi-View 3D Reconstruction
Baptiste Brument, Robin Bruneau, Yvain Qu'eau, Jean M'elou, Franc{c}ois Bernard Lauze, Jean-Denis, Jean-Denis Durou, Lilian Calvet
This paper introduces a versatile paradigm for integrating multi-view reflectance (optional) and normal maps acquired through photometric stereo. Our approach employs a pixel-wise joint re-parameterization of reflectance and normal, considering them as a vector of radiances rendered under simulated, varying illumination. This re-parameterization enables the seamless integration of reflectance and normal maps as input data in neural volume rendering-based 3D reconstruction while preserving a single optimization objective. In contrast, recent multi-view photometric stereo (MVPS) methods depend on multiple, potentially conflicting objectives. Despite its apparent simplicity, our proposed approach outperforms state-of-the-art approaches in MVPS benchmarks across F-score, Chamfer distance, and mean angular error metrics. Notably, it significantly improves the detailed 3D reconstruction of areas with high curvature or low visibility.
Read more4/1/2024