MOSEAC: Streamlined Variable Time Step Reinforcement Learning
2406.01521
0
0
Abstract
Traditional reinforcement learning (RL) methods typically employ a fixed control loop, where each cycle corresponds to an action. This rigidity poses challenges in practical applications, as the optimal control frequency is task-dependent. A suboptimal choice can lead to high computational demands and reduced exploration efficiency. Variable Time Step Reinforcement Learning (VTS-RL) addresses these issues by using adaptive frequencies for the control loop, executing actions only when necessary. This approach, rooted in reactive programming principles, reduces computational load and extends the action space by including action durations. However, VTS-RL's implementation is often complicated by the need to tune multiple hyperparameters that govern exploration in the multi-objective action-duration space (i.e., balancing task performance and number of time steps to achieve a goal). To overcome these challenges, we introduce the Multi-Objective Soft Elastic Actor-Critic (MOSEAC) method. This method features an adaptive reward scheme that adjusts hyperparameters based on observed trends in task rewards during training. This scheme reduces the complexity of hyperparameter tuning, requiring a single hyperparameter to guide exploration, thereby simplifying the learning process and lowering deployment costs. We validate the MOSEAC method through simulations in a Newtonian kinematics environment, demonstrating high task and training performance with fewer time steps, ultimately lowering energy consumption. This validation shows that MOSEAC streamlines RL algorithm deployment by automatically tuning the agent control loop frequency using a single parameter. Its principles can be applied to enhance any RL algorithm, making it a versatile solution for various applications.
Create account to get full access
Overview
- This paper introduces a new reinforcement learning algorithm called MOSEAC that uses a variable time step approach for more efficient and deployable reinforcement learning.
- MOSEAC aims to address limitations of existing reinforcement learning methods by allowing the agent to take variable-length time steps, which can improve sample efficiency and performance.
- The authors demonstrate the effectiveness of MOSEAC on several challenging reinforcement learning benchmark tasks and highlight its potential for real-world applications.
Plain English Explanation
Reinforcement learning is a type of machine learning where an agent learns to make decisions by interacting with an environment and receiving rewards or penalties. Traditional reinforcement learning algorithms often use a fixed time step, meaning the agent takes an action and receives feedback at regular, predefined intervals.
The MOSEAC algorithm introduced in this paper takes a different approach. MOSEAC allows the agent to take variable-length time steps, meaning it can choose when to act and receive feedback based on the current state of the environment. This can be more efficient than a fixed time step, as the agent can focus its efforts on the most important or urgent decisions.
For example, imagine a self-driving car navigating a busy city. With a fixed time step, the car would have to make decisions at a regular interval, even if the environment was relatively stable. With a variable time step approach like MOSEAC, the car could choose to act more frequently when the environment is changing rapidly (e.g., when merging into traffic) and less frequently when the environment is more stable (e.g., when driving on an empty road).
By allowing for this type of variable control rate, the MOSEAC algorithm can potentially improve the performance and efficiency of reinforcement learning systems, making them more suitable for real-world applications. The authors demonstrate the effectiveness of MOSEAC on several challenging reinforcement learning benchmarks and highlight its potential for multi-task learning and adaptive control.
Technical Explanation
The MOSEAC algorithm introduced in this paper uses a variable time step approach to improve the efficiency and performance of reinforcement learning. Instead of taking actions at a fixed interval, the MOSEAC agent can choose when to act based on the current state of the environment.
The key components of the MOSEAC algorithm are:
- State Encoding: The agent encodes the current state of the environment into a low-dimensional representation using a neural network.
- Action Selection: The agent uses another neural network to select an action based on the current state encoding. However, the agent does not immediately take the action. Instead, it computes a value function, which estimates the expected future reward for taking that action.
- Time Step Adaptation: The agent then compares the value function for the selected action to a predefined threshold. If the value function exceeds the threshold, the agent takes the action and receives the corresponding reward from the environment. If the value function does not exceed the threshold, the agent waits and reevaluates the state in the next time step.
This variable time step approach allows the MOSEAC agent to focus its efforts on the most important or urgent decisions, potentially improving sample efficiency and overall performance compared to traditional fixed-step reinforcement learning algorithms.
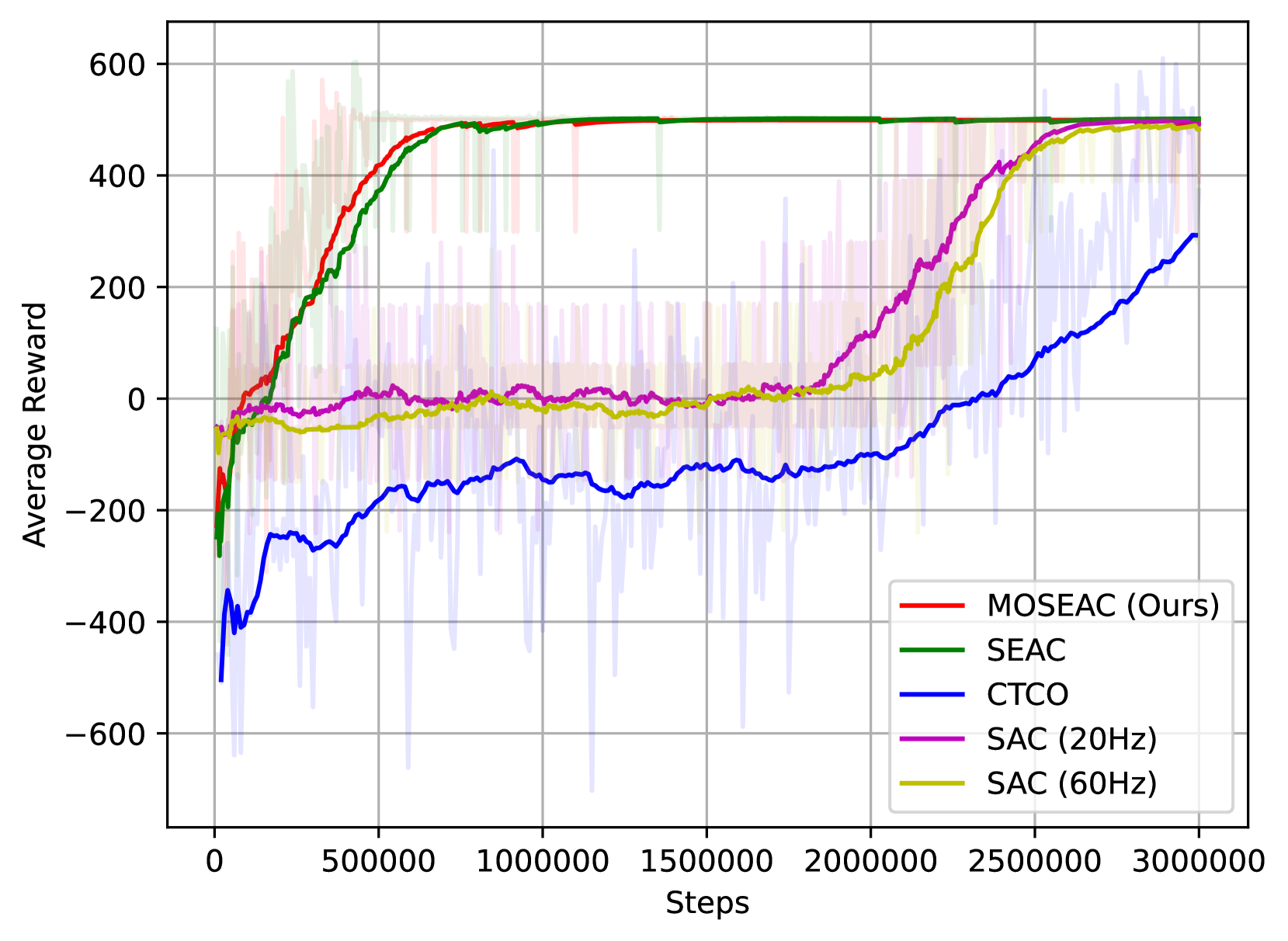
The authors evaluate MOSEAC on several challenging reinforcement learning benchmark tasks, including classic control problems and more complex 3D navigation environments. The results show that MOSEAC can outperform state-of-the-art fixed-step reinforcement learning algorithms, particularly in tasks where the optimal time step varies over the course of the episode.
Critical Analysis
The MOSEAC algorithm presented in this paper offers a promising approach to improving the efficiency and performance of reinforcement learning systems. By allowing for variable time steps, the agent can focus its efforts on the most critical decisions, potentially leading to faster convergence and better overall performance.
One potential limitation of the MOSEAC approach is the need to carefully tune the value function threshold, which determines when the agent will take an action. If the threshold is set too high, the agent may wait too long before acting, leading to suboptimal performance. Conversely, if the threshold is set too low, the agent may act too frequently, reducing the potential benefits of the variable time step approach.
Additionally, the authors note that the MOSEAC algorithm may be less suitable for environments with very fast-changing dynamics, where the agent may need to act at a fixed, high frequency to maintain optimal performance. In such cases, a more traditional fixed-step reinforcement learning algorithm may be more appropriate.
Overall, the MOSEAC algorithm represents an interesting and potentially impactful contribution to the field of reinforcement learning. Further research and experimentation will be needed to fully understand the strengths, limitations, and appropriate use cases of this approach.
Conclusion
The MOSEAC algorithm introduced in this paper offers a novel approach to reinforcement learning that uses a variable time step to improve sample efficiency and performance. By allowing the agent to choose when to act based on the current state of the environment, MOSEAC can potentially outperform traditional fixed-step reinforcement learning algorithms, particularly in tasks with varying optimal time scales.
The authors demonstrate the effectiveness of MOSEAC on several challenging reinforcement learning benchmark tasks and highlight its potential for real-world applications, such as adaptive control and multi-task learning. While the MOSEAC approach may not be suitable for all environments, it represents an important step forward in the ongoing effort to develop more efficient and deployable reinforcement learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Reinforcement Learning with Elastic Time Steps
Dong Wang, Giovanni Beltrame
0
0
Traditional Reinforcement Learning (RL) algorithms are usually applied in robotics to learn controllers that act with a fixed control rate. Given the discrete nature of RL algorithms, they are oblivious to the effects of the choice of control rate: finding the correct control rate can be difficult and mistakes often result in excessive use of computing resources or even lack of convergence. We propose Soft Elastic Actor-Critic (SEAC), a novel off-policy actor-critic algorithm to address this issue. SEAC implements elastic time steps, time steps with a known, variable duration, which allow the agent to change its control frequency to adapt to the situation. In practice, SEAC applies control only when necessary, minimizing computational resources and data usage. We evaluate SEAC's capabilities in simulation in a Newtonian kinematics maze navigation task and on a 3D racing video game, Trackmania. SEAC outperforms the SAC baseline in terms of energy efficiency and overall time management, and most importantly without the need to identify a control frequency for the learned controller. SEAC demonstrated faster and more stable training speeds than SAC, especially at control rates where SAC struggled to converge. We also compared SEAC with a similar approach, the Continuous-Time Continuous-Options (CTCO) model, and SEAC resulted in better task performance. These findings highlight the potential of SEAC for practical, real-world RL applications in robotics.
4/3/2024
Deployable Reinforcement Learning with Variable Control Rate
Dong Wang, Giovanni Beltrame
0
0
Deploying controllers trained with Reinforcement Learning (RL) on real robots can be challenging: RL relies on agents' policies being modeled as Markov Decision Processes (MDPs), which assume an inherently discrete passage of time. The use of MDPs results in that nearly all RL-based control systems employ a fixed-rate control strategy with a period (or time step) typically chosen based on the developer's experience or specific characteristics of the application environment. Unfortunately, the system should be controlled at the highest, worst-case frequency to ensure stability, which can demand significant computational and energy resources and hinder the deployability of the controller on onboard hardware. Adhering to the principles of reactive programming, we surmise that applying control actions only when necessary enables the use of simpler hardware and helps reduce energy consumption. We challenge the fixed frequency assumption by proposing a variant of RL with variable control rate. In this approach, the policy decides the action the agent should take as well as the duration of the time step associated with that action. In our new setting, we expand Soft Actor-Critic (SAC) to compute the optimal policy with a variable control rate, introducing the Soft Elastic Actor-Critic (SEAC) algorithm. We show the efficacy of SEAC through a proof-of-concept simulation driving an agent with Newtonian kinematics. Our experiments show higher average returns, shorter task completion times, and reduced computational resources when compared to fixed rate policies.
4/3/2024
🛠️
End-to-End Streaming Video Temporal Action Segmentation with Reinforce Learning
Jinrong Zhang, Wujun Wen, Shenglan Liu, Yunheng Li, Qifeng Li, Lin Feng
0
0
The streaming temporal action segmentation (STAS) task, a supplementary task of temporal action segmentation (TAS), has not received adequate attention in the field of video understanding. Existing TAS methods are constrained to offline scenarios due to their heavy reliance on multimodal features and complete contextual information. The STAS task requires the model to classify each frame of the entire untrimmed video sequence clip by clip in time, thereby extending the applicability of TAS methods to online scenarios. However, directly applying existing TAS methods to SATS tasks results in significantly poor segmentation outcomes. In this paper, we thoroughly analyze the fundamental differences between STAS tasks and TAS tasks, attributing the severe performance degradation when transferring models to model bias and optimization dilemmas. We introduce an end-to-end streaming video temporal action segmentation model with reinforcement learning (SVTAS-RL). The end-to-end modeling method mitigates the modeling bias introduced by the change in task nature and enhances the feasibility of online solutions. Reinforcement learning is utilized to alleviate the optimization dilemma. Through extensive experiments, the SVTAS-RL model significantly outperforms existing STAS models and achieves competitive performance to the state-of-the-art TAS model on multiple datasets under the same evaluation criteria, demonstrating notable advantages on the ultra-long video dataset EGTEA. Code is available at https://github.com/Thinksky5124/SVTAS.
5/24/2024

Efficient Multi-Task Reinforcement Learning via Task-Specific Action Correction
Jinyuan Feng, Min Chen, Zhiqiang Pu, Tenghai Qiu, Jianqiang Yi
0
0
Multi-task reinforcement learning (MTRL) demonstrate potential for enhancing the generalization of a robot, enabling it to perform multiple tasks concurrently. However, the performance of MTRL may still be susceptible to conflicts between tasks and negative interference. To facilitate efficient MTRL, we propose Task-Specific Action Correction (TSAC), a general and complementary approach designed for simultaneous learning of multiple tasks. TSAC decomposes policy learning into two separate policies: a shared policy (SP) and an action correction policy (ACP). To alleviate conflicts resulting from excessive focus on specific tasks' details in SP, ACP incorporates goal-oriented sparse rewards, enabling an agent to adopt a long-term perspective and achieve generalization across tasks. Additional rewards transform the original problem into a multi-objective MTRL problem. Furthermore, to convert the multi-objective MTRL into a single-objective formulation, TSAC assigns a virtual expected budget to the sparse rewards and employs Lagrangian method to transform a constrained single-objective optimization into an unconstrained one. Experimental evaluations conducted on Meta-World's MT10 and MT50 benchmarks demonstrate that TSAC outperforms existing state-of-the-art methods, achieving significant improvements in both sample efficiency and effective action execution.
4/10/2024