MST5 -- Multilingual Question Answering over Knowledge Graphs

0
Sign in to get full access
Overview
- This paper presents MST5, a transformers-based approach to multilingual question answering over knowledge graphs.
- The key innovations include a multilingual language model fine-tuned on knowledge graph data and a SPARQL generation module for converting natural language questions into structured queries.
- The model is evaluated on several multilingual knowledge graph question answering benchmarks and achieves state-of-the-art performance.
Plain English Explanation
The researchers developed a system called MST5 that can answer questions in multiple languages by using information from knowledge graphs. Knowledge graphs are structured databases that store information about entities (like people, places, or things) and the relationships between them.
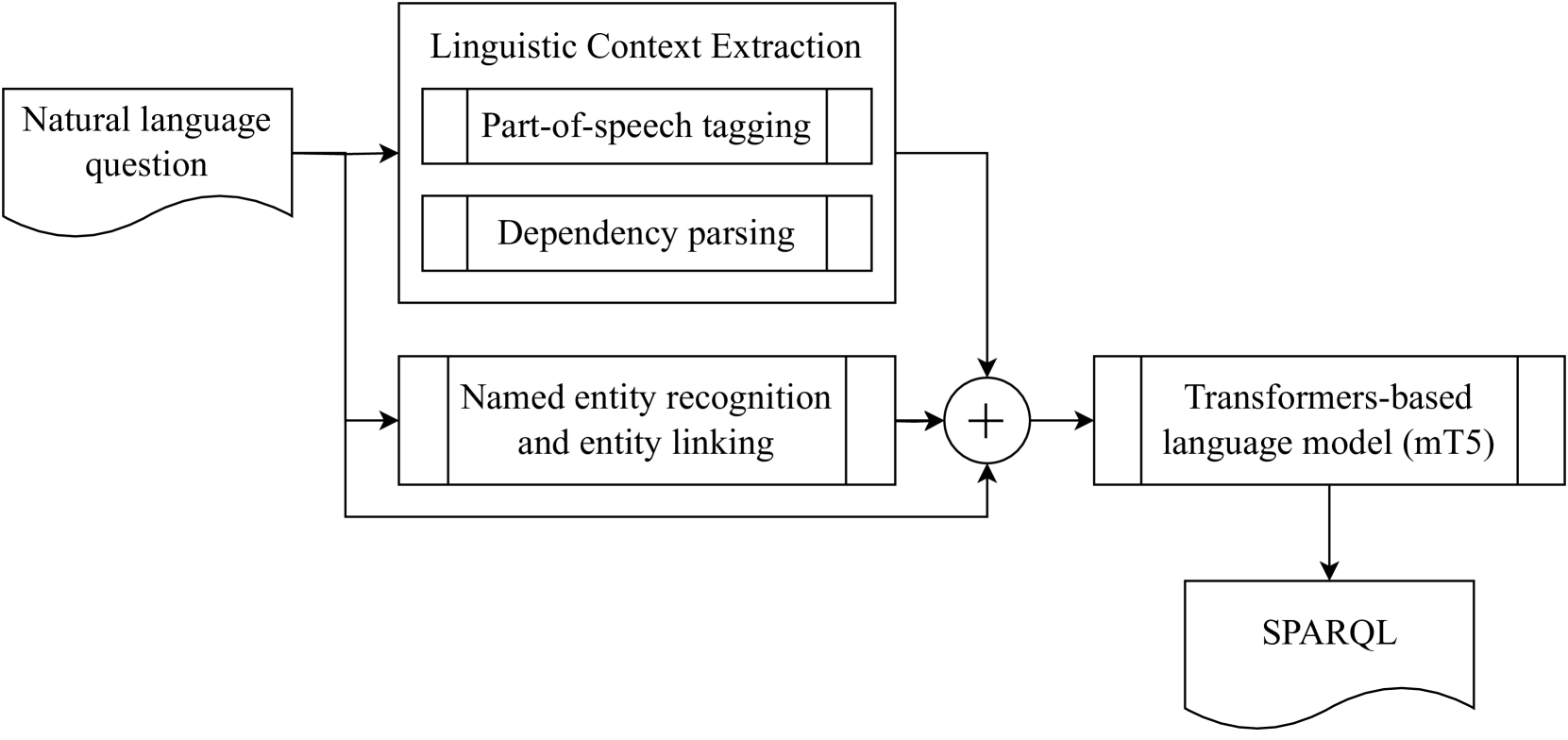
MST5 works by first using a large language model that has been trained on knowledge graph data to understand the meaning of the question, even when it's asked in a different language. Then, it generates a SPARQL query, which is a special language for asking questions of knowledge graphs. This query is used to retrieve the relevant information from the knowledge graph and provide an answer.
The key advantages of this approach are that it can handle questions in many languages, and it can directly access the structured information in knowledge graphs to give accurate answers, rather than just searching for keywords in text. The researchers evaluated MST5 on several benchmark datasets and found that it outperformed other state-of-the-art question answering systems.
This work is significant because it demonstrates how large language models and knowledge graphs can be combined to build multilingual question answering systems that are more powerful and flexible than previous approaches. It could have applications in areas like online customer support, virtual assistants, and information retrieval, where users need to be able to ask questions in their preferred language and get accurate answers.
Technical Explanation
The core of the MST5 model is a multilingual language model that has been fine-tuned on knowledge graph data. This allows the model to effectively understand the semantics of natural language questions and map them to the structured representations of knowledge graphs.
To convert the natural language question into a SPARQL query, the researchers use a multi-hop question answering approach. This involves breaking down the question into a sequence of sub-queries that can be executed over the knowledge graph to retrieve the final answer.
The SPARQL generation module is trained using a retrieve-then-generate framework, where the model first retrieves relevant information from the knowledge graph and then generates the corresponding SPARQL query.
The researchers also leverage large language model capabilities to better understand the semantics of the questions and the knowledge graph. This allows the model to handle complex, multi-hop queries more effectively than previous approaches.
Critical Analysis
One limitation of the MST5 approach is that it relies on the availability of a knowledge graph that covers the domain of interest. If the knowledge graph is incomplete or biased, the model's performance may be impacted. The researchers acknowledge this and suggest incorporating external knowledge sources to address this issue.
Additionally, the model's performance may degrade on questions that require complex reasoning or involve ambiguous or context-dependent language. Further research is needed to improve the model's ability to handle these more challenging cases.
Finally, the computational complexity of the SPARQL generation step may limit the scalability of the approach, especially for large knowledge graphs. Exploring more efficient query generation techniques could be an area for future work.
Conclusion
The MST5 model represents a significant advance in the field of multilingual knowledge graph question answering. By combining large language models, structured knowledge, and advanced query generation techniques, the researchers have developed a system that can accurately answer questions in multiple languages by directly leveraging the information in knowledge graphs.
This work has important implications for the development of more intelligent and accessible information retrieval systems, virtual assistants, and other applications that require multilingual question-answering capabilities. As knowledge graphs and language models continue to improve, we can expect to see further advancements in this area that will benefit a wide range of users and industries.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MST5 -- Multilingual Question Answering over Knowledge Graphs
Nikit Srivastava, Mengshi Ma, Daniel Vollmers, Hamada Zahera, Diego Moussallem, Axel-Cyrille Ngonga Ngomo
Knowledge Graph Question Answering (KGQA) simplifies querying vast amounts of knowledge stored in a graph-based model using natural language. However, the research has largely concentrated on English, putting non-English speakers at a disadvantage. Meanwhile, existing multilingual KGQA systems face challenges in achieving performance comparable to English systems, highlighting the difficulty of generating SPARQL queries from diverse languages. In this research, we propose a simplified approach to enhance multilingual KGQA systems by incorporating linguistic context and entity information directly into the processing pipeline of a language model. Unlike existing methods that rely on separate encoders for integrating auxiliary information, our strategy leverages a single, pretrained multilingual transformer-based language model to manage both the primary input and the auxiliary data. Our methodology significantly improves the language model's ability to accurately convert a natural language query into a relevant SPARQL query. It demonstrates promising results on the most recent QALD datasets, namely QALD-9-Plus and QALD-10. Furthermore, we introduce and evaluate our approach on Chinese and Japanese, thereby expanding the language diversity of the existing datasets.
Read more7/9/2024

0
Multilingual Knowledge Graph Completion from Pretrained Language Models with Knowledge Constraints
Ran Song, Shizhu He, Shengxiang Gao, Li Cai, Kang Liu, Zhengtao Yu, Jun Zhao
Multilingual Knowledge Graph Completion (mKGC) aim at solving queries like (h, r, ?) in different languages by reasoning a tail entity t thus improving multilingual knowledge graphs. Previous studies leverage multilingual pretrained language models (PLMs) and the generative paradigm to achieve mKGC. Although multilingual pretrained language models contain extensive knowledge of different languages, its pretraining tasks cannot be directly aligned with the mKGC tasks. Moreover, the majority of KGs and PLMs currently available exhibit a pronounced English-centric bias. This makes it difficult for mKGC to achieve good results, particularly in the context of low-resource languages. To overcome previous problems, this paper introduces global and local knowledge constraints for mKGC. The former is used to constrain the reasoning of answer entities, while the latter is used to enhance the representation of query contexts. The proposed method makes the pretrained model better adapt to the mKGC task. Experimental results on public datasets demonstrate that our method outperforms the previous SOTA on Hits@1 and Hits@10 by an average of 12.32% and 16.03%, which indicates that our proposed method has significant enhancement on mKGC.
Read more6/27/2024
💬
0
Multi-hop Question Answering over Knowledge Graphs using Large Language Models
Abir Chakraborty
Knowledge graphs (KGs) are large datasets with specific structures representing large knowledge bases (KB) where each node represents a key entity and relations amongst them are typed edges. Natural language queries formed to extract information from a KB entail starting from specific nodes and reasoning over multiple edges of the corresponding KG to arrive at the correct set of answer nodes. Traditional approaches of question answering on KG are based on (a) semantic parsing (SP), where a logical form (e.g., S-expression, SPARQL query, etc.) is generated using node and edge embeddings and then reasoning over these representations or tuning language models to generate the final answer directly, or (b) information-retrieval based that works by extracting entities and relations sequentially. In this work, we evaluate the capability of (LLMs) to answer questions over KG that involve multiple hops. We show that depending upon the size and nature of the KG we need different approaches to extract and feed the relevant information to an LLM since every LLM comes with a fixed context window. We evaluate our approach on six KGs with and without the availability of example-specific sub-graphs and show that both the IR and SP-based methods can be adopted by LLMs resulting in an extremely competitive performance.
Read more5/1/2024

0
Interactive-KBQA: Multi-Turn Interactions for Knowledge Base Question Answering with Large Language Models
Guanming Xiong, Junwei Bao, Wen Zhao
This study explores the realm of knowledge base question answering (KBQA). KBQA is considered a challenging task, particularly in parsing intricate questions into executable logical forms. Traditional semantic parsing (SP)-based methods require extensive data annotations, which result in significant costs. Recently, the advent of few-shot in-context learning, powered by large language models (LLMs), has showcased promising capabilities. However, fully leveraging LLMs to parse questions into logical forms in low-resource scenarios poses a substantial challenge. To tackle these hurdles, we introduce Interactive-KBQA, a framework designed to generate logical forms through direct interaction with knowledge bases (KBs). Within this framework, we have developed three generic APIs for KB interaction. For each category of complex question, we devised exemplars to guide LLMs through the reasoning processes. Our method achieves competitive results on the WebQuestionsSP, ComplexWebQuestions, KQA Pro, and MetaQA datasets with a minimal number of examples (shots). Importantly, our approach supports manual intervention, allowing for the iterative refinement of LLM outputs. By annotating a dataset with step-wise reasoning processes, we showcase our model's adaptability and highlight its potential for contributing significant enhancements to the field.
Read more7/22/2024