MTP: Advancing Remote Sensing Foundation Model via Multi-Task Pretraining
2403.13430
0
0

Abstract
Foundation models have reshaped the landscape of Remote Sensing (RS) by enhancing various image interpretation tasks. Pretraining is an active research topic, encompassing supervised and self-supervised learning methods to initialize model weights effectively. However, transferring the pretrained models to downstream tasks may encounter task discrepancy due to their formulation of pretraining as image classification or object discrimination tasks. In this study, we explore the Multi-Task Pretraining (MTP) paradigm for RS foundation models to address this issue. Using a shared encoder and task-specific decoder architecture, we conduct multi-task supervised pretraining on the SAMRS dataset, encompassing semantic segmentation, instance segmentation, and rotated object detection. MTP supports both convolutional neural networks and vision transformer foundation models with over 300 million parameters. The pretrained models are finetuned on various RS downstream tasks, such as scene classification, horizontal and rotated object detection, semantic segmentation, and change detection. Extensive experiments across 14 datasets demonstrate the superiority of our models over existing ones of similar size and their competitive performance compared to larger state-of-the-art models, thus validating the effectiveness of MTP.
Create account to get full access
Overview
- This paper introduces a multi-task pretraining (MTP) approach to advance remote sensing foundation models.
- MTP aims to improve the performance of remote sensing models by jointly training them on multiple tasks, including scene classification, semantic segmentation, object detection, and change detection.
- The authors claim that MTP can lead to more robust and generalizable remote sensing models compared to single-task pretraining.
Plain English Explanation
The paper presents a new way to train remote sensing models, called multi-task pretraining (MTP). Remote sensing is the science of gathering information about the Earth's surface without physically being there, using satellites or other sensors.
Typically, remote sensing models are trained to perform a single task, like classifying the type of scene in an image (e.g., urban, forest, farmland). The authors argue that training a model to do multiple tasks at once can make it more capable and versatile.
In the MTP approach, the model is first trained on a diverse set of remote sensing tasks, such as identifying objects, detecting changes over time, and segmenting different land cover types. This "multi-task pretraining" teaches the model to extract useful features and representations that are relevant across many remote sensing applications.
After this initial multi-task training, the model can then be fine-tuned or adapted to perform well on specific downstream tasks, like a particular type of scene classification. The authors claim this leads to models that are more robust and can generalize better to new situations, compared to models trained only on a single task.
Technical Explanation
The key innovation of this paper is the proposed multi-task pretraining (MTP) approach for training remote sensing foundation models. The authors argue that joint training on multiple remote sensing tasks can result in models that are more capable and generalizable than those trained on a single task.
The MTP framework consists of two main stages:
- Multi-task pretraining: The model is trained simultaneously on a diverse set of remote sensing tasks, including scene classification, semantic segmentation, object detection, and change detection. This allows the model to learn rich, transferable representations.
- Downstream task fine-tuning: The pretrained model is then fine-tuned on a specific downstream task of interest, leveraging the knowledge gained during the multi-task pretraining stage.
The authors evaluate the MTP approach on several popular remote sensing benchmarks and demonstrate its superiority over single-task pretraining in terms of performance and generalization.
Critical Analysis
The authors provide a comprehensive evaluation of the MTP approach and its benefits compared to single-task pretraining. However, there are a few potential limitations and areas for further research:
-
Task Selection: The choice of tasks included in the multi-task pretraining stage can have a significant impact on the model's performance. The authors do not provide a detailed analysis on how the selection of tasks affects the final results.
-
Dataset Diversity: The effectiveness of MTP may be dependent on the diversity and breadth of the datasets used for pretraining. Further research could explore the impact of dataset size and heterogeneity on the MTP approach.
-
Computational Efficiency: Training a model on multiple tasks simultaneously can be computationally expensive. The authors do not discuss the trade-offs between the performance gains and the increased computational requirements of MTP.
-
Real-world Applicability: While the paper demonstrates the advantages of MTP on established benchmarks, more research is needed to understand its practical implications and deployment in real-world remote sensing applications.
Overall, the MTP approach presented in this paper is a promising direction for advancing remote sensing foundation models, but further investigation is warranted to address the potential limitations and expand the understanding of its practical applications.
Conclusion
This paper introduces a multi-task pretraining (MTP) framework for training remote sensing foundation models. The key idea is to jointly train the model on multiple remote sensing tasks, such as scene classification, semantic segmentation, object detection, and change detection, during the pretraining stage.
The authors show that this MTP approach can lead to more robust and generalizable remote sensing models compared to traditional single-task pretraining. The proposed framework has the potential to significantly improve the performance and versatility of remote sensing models, with applications in a wide range of domains, from environmental monitoring to urban planning and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
A Billion-scale Foundation Model for Remote Sensing Images
Keumgang Cha, Junghoon Seo, Taekyung Lee
0
0
As the potential of foundation models in visual tasks has garnered significant attention, pretraining these models before downstream tasks has become a crucial step. The three key factors in pretraining foundation models are the pretraining method, the size of the pretraining dataset, and the number of model parameters. Recently, research in the remote sensing field has focused primarily on the pretraining method and the size of the dataset, with limited emphasis on the number of model parameters. This paper addresses this gap by examining the effect of increasing the number of model parameters on the performance of foundation models in downstream tasks such as rotated object detection and semantic segmentation. We pretrained foundation models with varying numbers of parameters, including 86M, 605.26M, 1.3B, and 2.4B, to determine whether performance in downstream tasks improved with an increase in parameters. To the best of our knowledge, this is the first billion-scale foundation model in the remote sensing field. Furthermore, we propose an effective method for scaling up and fine-tuning a vision transformer in the remote sensing field. To evaluate general performance in downstream tasks, we employed the DOTA v2.0 and DIOR-R benchmark datasets for rotated object detection, and the Potsdam and LoveDA datasets for semantic segmentation. Experimental results demonstrated that, across all benchmark datasets and downstream tasks, the performance of the foundation models and data efficiency improved as the number of parameters increased. Moreover, our models achieve the state-of-the-art performance on several datasets including DIOR-R, Postdam, and LoveDA.
5/15/2024
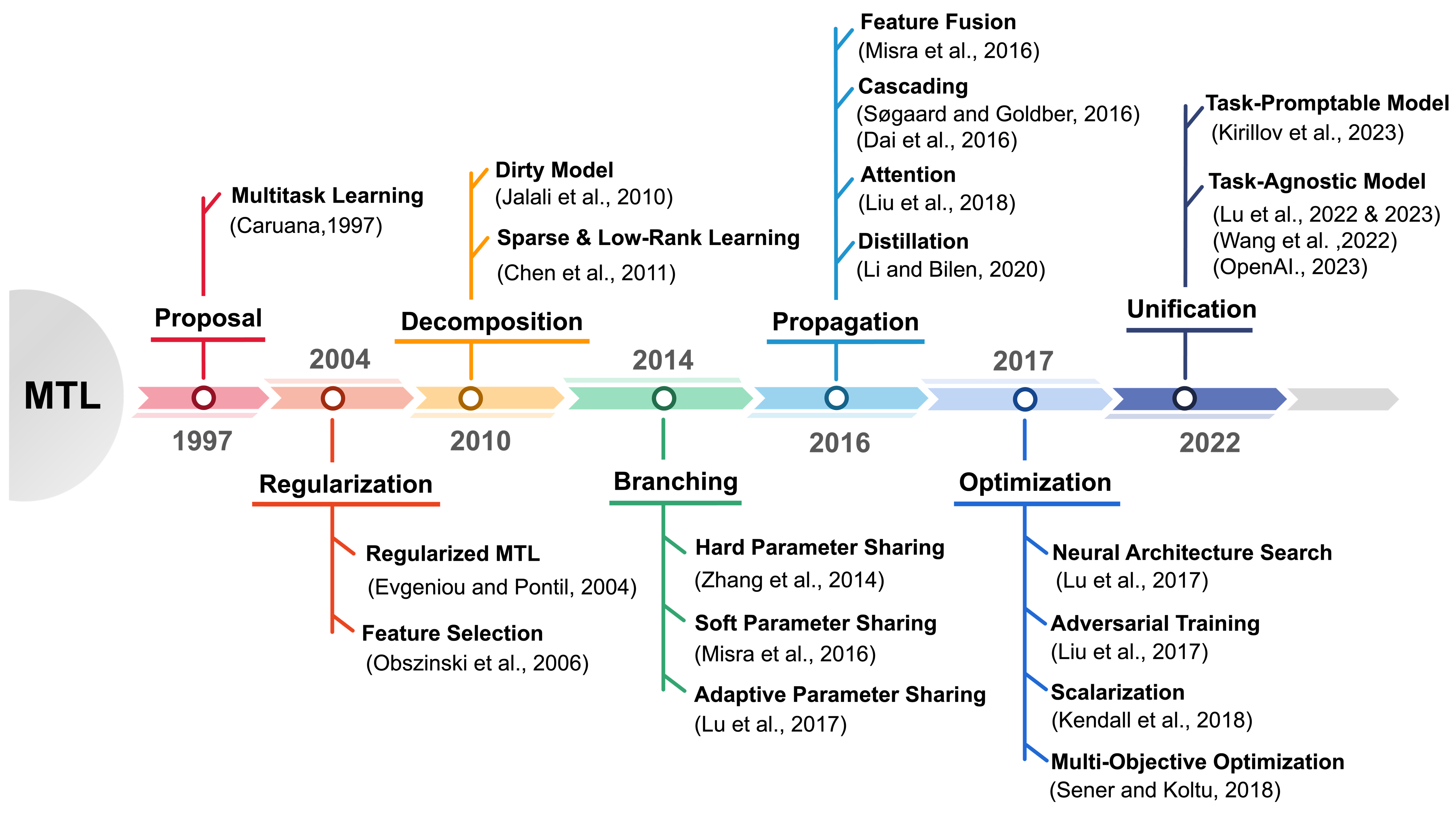
Unleashing the Power of Multi-Task Learning: A Comprehensive Survey Spanning Traditional, Deep, and Pretrained Foundation Model Eras
Jun Yu, Yutong Dai, Xiaokang Liu, Jin Huang, Yishan Shen, Ke Zhang, Rong Zhou, Eashan Adhikarla, Wenxuan Ye, Yixin Liu, Zhaoming Kong, Kai Zhang, Yilong Yin, Vinod Namboodiri, Brian D. Davison, Jason H. Moore, Yong Chen
0
0
MTL is a learning paradigm that effectively leverages both task-specific and shared information to address multiple related tasks simultaneously. In contrast to STL, MTL offers a suite of benefits that enhance both the training process and the inference efficiency. MTL's key advantages encompass streamlined model architecture, performance enhancement, and cross-domain generalizability. Over the past twenty years, MTL has become widely recognized as a flexible and effective approach in various fields, including CV, NLP, recommendation systems, disease prognosis and diagnosis, and robotics. This survey provides a comprehensive overview of the evolution of MTL, encompassing the technical aspects of cutting-edge methods from traditional approaches to deep learning and the latest trend of pretrained foundation models. Our survey methodically categorizes MTL techniques into five key areas: regularization, relationship learning, feature propagation, optimization, and pre-training. This categorization not only chronologically outlines the development of MTL but also dives into various specialized strategies within each category. Furthermore, the survey reveals how the MTL evolves from handling a fixed set of tasks to embracing a more flexible approach free from task or modality constraints. It explores the concepts of task-promptable and -agnostic training, along with the capacity for ZSL, which unleashes the untapped potential of this historically coveted learning paradigm. Overall, we hope this survey provides the research community with a comprehensive overview of the advancements in MTL from its inception in 1997 to the present in 2023. We address present challenges and look ahead to future possibilities, shedding light on the opportunities and potential avenues for MTL research in a broad manner. This project is publicly available at https://github.com/junfish/Awesome-Multitask-Learning.
5/1/2024

MMEarth: Exploring Multi-Modal Pretext Tasks For Geospatial Representation Learning
Vishal Nedungadi, Ankit Kariryaa, Stefan Oehmcke, Serge Belongie, Christian Igel, Nico Lang
0
0
The volume of unlabelled Earth observation (EO) data is huge, but many important applications lack labelled training data. However, EO data offers the unique opportunity to pair data from different modalities and sensors automatically based on geographic location and time, at virtually no human labor cost. We seize this opportunity to create a diverse multi-modal pretraining dataset at global scale. Using this new corpus of 1.2 million locations, we propose a Multi-Pretext Masked Autoencoder (MP-MAE) approach to learn general-purpose representations for optical satellite images. Our approach builds on the ConvNeXt V2 architecture, a fully convolutional masked autoencoder (MAE). Drawing upon a suite of multi-modal pretext tasks, we demonstrate that our MP-MAE approach outperforms both MAEs pretrained on ImageNet and MAEs pretrained on domain-specific satellite images. This is shown on several downstream tasks including image classification and semantic segmentation. We find that multi-modal pretraining notably improves the linear probing performance, e.g. 4pp on BigEarthNet and 16pp on So2Sat, compared to pretraining on optical satellite images only. We show that this also leads to better label and parameter efficiency which are crucial aspects in global scale applications.
5/7/2024
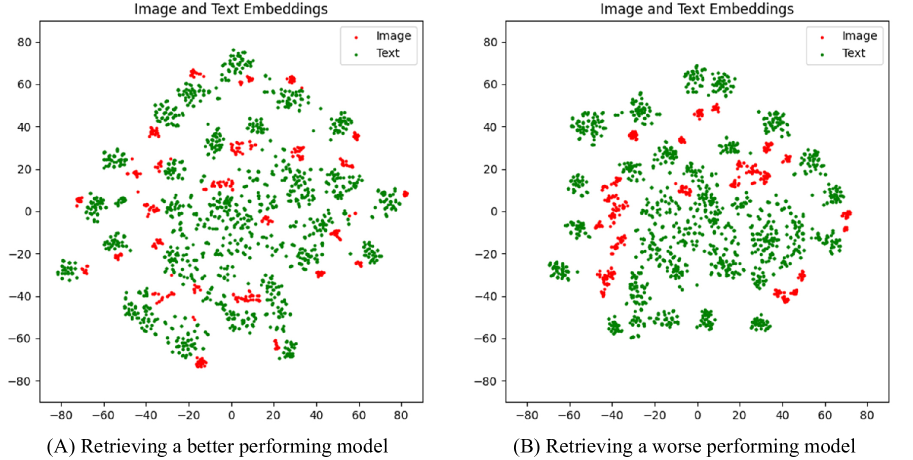
Efficient Remote Sensing with Harmonized Transfer Learning and Modality Alignment
Tengjun Huang
0
0
With the rise of Visual and Language Pretraining (VLP), an increasing number of downstream tasks are adopting the paradigm of pretraining followed by fine-tuning. Although this paradigm has demonstrated potential in various multimodal downstream tasks, its implementation in the remote sensing domain encounters some obstacles. Specifically, the tendency for same-modality embeddings to cluster together impedes efficient transfer learning. To tackle this issue, we review the aim of multimodal transfer learning for downstream tasks from a unified perspective, and rethink the optimization process based on three distinct objectives. We propose Harmonized Transfer Learning and Modality Alignment (HarMA), a method that simultaneously satisfies task constraints, modality alignment, and single-modality uniform alignment, while minimizing training overhead through parameter-efficient fine-tuning. Remarkably, without the need for external data for training, HarMA achieves state-of-the-art performance in two popular multimodal retrieval tasks in the field of remote sensing. Our experiments reveal that HarMA achieves competitive and even superior performance to fully fine-tuned models with only minimal adjustable parameters. Due to its simplicity, HarMA can be integrated into almost all existing multimodal pretraining models. We hope this method can facilitate the efficient application of large models to a wide range of downstream tasks while significantly reducing the resource consumption. Code is available at https://github.com/seekerhuang/HarMA.
5/29/2024