A Billion-scale Foundation Model for Remote Sensing Images
2304.05215
0
0
📈
Abstract
As the potential of foundation models in visual tasks has garnered significant attention, pretraining these models before downstream tasks has become a crucial step. The three key factors in pretraining foundation models are the pretraining method, the size of the pretraining dataset, and the number of model parameters. Recently, research in the remote sensing field has focused primarily on the pretraining method and the size of the dataset, with limited emphasis on the number of model parameters. This paper addresses this gap by examining the effect of increasing the number of model parameters on the performance of foundation models in downstream tasks such as rotated object detection and semantic segmentation. We pretrained foundation models with varying numbers of parameters, including 86M, 605.26M, 1.3B, and 2.4B, to determine whether performance in downstream tasks improved with an increase in parameters. To the best of our knowledge, this is the first billion-scale foundation model in the remote sensing field. Furthermore, we propose an effective method for scaling up and fine-tuning a vision transformer in the remote sensing field. To evaluate general performance in downstream tasks, we employed the DOTA v2.0 and DIOR-R benchmark datasets for rotated object detection, and the Potsdam and LoveDA datasets for semantic segmentation. Experimental results demonstrated that, across all benchmark datasets and downstream tasks, the performance of the foundation models and data efficiency improved as the number of parameters increased. Moreover, our models achieve the state-of-the-art performance on several datasets including DIOR-R, Postdam, and LoveDA.
Create account to get full access
Overview
- This paper explores the impact of increasing the number of parameters in foundation models on their performance in downstream visual tasks like object detection and semantic segmentation.
- The researchers pretrained foundation models with varying parameter counts (86M, 605.26M, 1.3B, and 2.4B) and evaluated their performance on remote sensing benchmark datasets.
- This is the first time a billion-scale foundation model has been introduced in the remote sensing field.
- The study demonstrates that increasing model size consistently improves performance and data efficiency across the tested downstream tasks and datasets.
Plain English Explanation
Foundation models are powerful machine learning models that can be trained on large, diverse datasets and then fine-tuned for specific tasks. When it comes to visual tasks like object detection and semantic segmentation, the size of the foundation model (i.e., the number of parameters) is an important factor in determining its performance.
In this study, the researchers explored how increasing the size of a foundation model affects its ability to excel at downstream visual tasks in the remote sensing domain. They pretrained models with 86 million, 605 million, 1.3 billion, and 2.4 billion parameters, and then evaluated the models' performance on benchmark datasets for rotated object detection and semantic segmentation.
The key finding is that as the foundation model size increased, the models performed better and were more data-efficient on the downstream tasks. In other words, the larger models were able to achieve higher accuracy with less training data. This is an important result, as it suggests that investing in the development of large-scale foundation models can lead to significant improvements in the performance of downstream visual applications in the remote sensing field.
Notably, the researchers created the first billion-scale foundation model for remote sensing, which is a major milestone for the field. This demonstrates the potential for applying large, powerful models to solve complex remote sensing problems.
Technical Explanation
The paper focuses on the pretraining of foundation models for visual tasks, which is a crucial step before fine-tuning the models for downstream applications. The researchers examined three key factors in pretraining: the pretraining method, the size of the pretraining dataset, and the number of model parameters.
While previous research in the remote sensing field has primarily focused on the pretraining method and dataset size, this paper addresses the gap in understanding the impact of model size. The researchers pretrained foundation models with varying numbers of parameters (86M, 605.26M, 1.3B, and 2.4B) and evaluated their performance on benchmark datasets for rotated object detection and semantic segmentation.
The experiments demonstrated that as the number of model parameters increased, the foundation models' performance and data efficiency improved across all the tested benchmark datasets and downstream tasks. This is the first time a billion-scale foundation model has been introduced in the remote sensing field.
Additionally, the researchers proposed an effective method for scaling up and fine-tuning a vision transformer, which is a type of neural network architecture, for the remote sensing domain. This contributed to the state-of-the-art performance achieved by the models on several datasets, including DIOR-R, Postdam, and LoveDA.
Critical Analysis
The paper presents a thorough and rigorous investigation into the impact of model size on the performance of foundation models in the remote sensing domain. The experimental design and analysis are well-executed, and the results provide valuable insights for the research community.
One potential limitation of the study is the reliance on a few specific benchmark datasets, which may not fully capture the diversity and complexity of real-world remote sensing tasks. Additionally, the paper does not delve into the computational and resource requirements for training and deploying these large-scale foundation models, which could be a practical concern for some applications.
Further research could explore the tradeoffs between model size, training efficiency, and inference speed, as well as investigate the generalization capabilities of these large-scale models across a wider range of remote sensing tasks and datasets. Exploring the interpretability and explainability of these foundation models could also be a fruitful area of investigation.
Conclusion
This study demonstrates the significant benefits of increasing the size of foundation models for visual tasks in the remote sensing field. By pretraining models with up to 2.4 billion parameters, the researchers were able to achieve state-of-the-art performance on benchmark datasets for rotated object detection and semantic segmentation.
The findings highlight the potential of large-scale foundation models to drive substantial improvements in the accuracy and data efficiency of remote sensing applications. As the remote sensing field continues to evolve, the development of powerful, scalable foundation models could become a key enabler for unlocking new capabilities and advancing the state of the art.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Pretraining Billion-scale Geospatial Foundational Models on Frontier
Aristeidis Tsaris, Philipe Ambrozio Dias, Abhishek Potnis, Junqi Yin, Feiyi Wang, Dalton Lunga
0
0
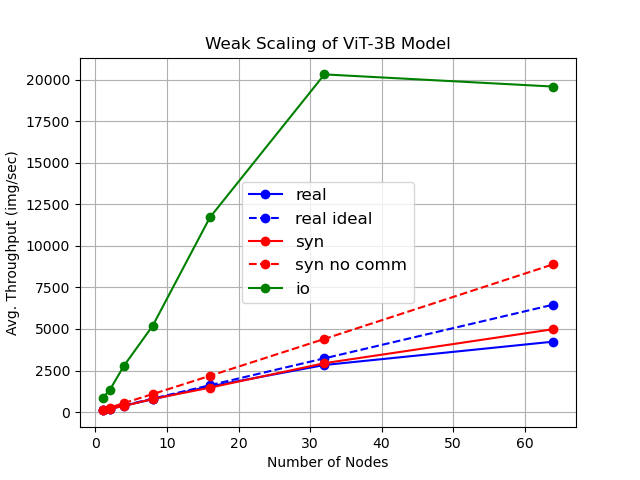
As AI workloads increase in scope, generalization capability becomes challenging for small task-specific models and their demand for large amounts of labeled training samples increases. On the contrary, Foundation Models (FMs) are trained with internet-scale unlabeled data via self-supervised learning and have been shown to adapt to various tasks with minimal fine-tuning. Although large FMs have demonstrated significant impact in natural language processing and computer vision, efforts toward FMs for geospatial applications have been restricted to smaller size models, as pretraining larger models requires very large computing resources equipped with state-of-the-art hardware accelerators. Current satellite constellations collect 100+TBs of data a day, resulting in images that are billions of pixels and multimodal in nature. Such geospatial data poses unique challenges opening up new opportunities to develop FMs. We investigate billion scale FMs and HPC training profiles for geospatial applications by pretraining on publicly available data. We studied from end-to-end the performance and impact in the solution by scaling the model size. Our larger 3B parameter size model achieves up to 30% improvement in top1 scene classification accuracy when comparing a 100M parameter model. Moreover, we detail performance experiments on the Frontier supercomputer, America's first exascale system, where we study different model and data parallel approaches using PyTorch's Fully Sharded Data Parallel library. Specifically, we study variants of the Vision Transformer architecture (ViT), conducting performance analysis for ViT models with size up to 15B parameters. By discussing throughput and performance bottlenecks under different parallelism configurations, we offer insights on how to leverage such leadership-class HPC resources when developing large models for geospatial imagery applications.
4/19/2024
When are Foundation Models Effective? Understanding the Suitability for Pixel-Level Classification Using Multispectral Imagery
Yiqun Xie, Zhihao Wang, Weiye Chen, Zhili Li, Xiaowei Jia, Yanhua Li, Ruichen Wang, Kangyang Chai, Ruohan Li, Sergii Skakun
0
0
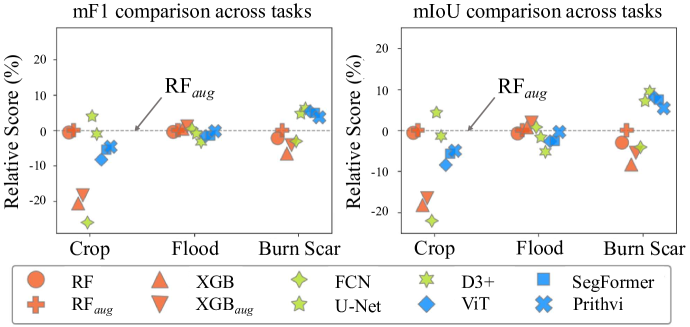
Foundation models, i.e., very large deep learning models, have demonstrated impressive performances in various language and vision tasks that are otherwise difficult to reach using smaller-size models. The major success of GPT-type of language models is particularly exciting and raises expectations on the potential of foundation models in other domains including satellite remote sensing. In this context, great efforts have been made to build foundation models to test their capabilities in broader applications, and examples include Prithvi by NASA-IBM, Segment-Anything-Model, ViT, etc. This leads to an important question: Are foundation models always a suitable choice for different remote sensing tasks, and when or when not? This work aims to enhance the understanding of the status and suitability of foundation models for pixel-level classification using multispectral imagery at moderate resolution, through comparisons with traditional machine learning (ML) and regular-size deep learning models. Interestingly, the results reveal that in many scenarios traditional ML models still have similar or better performance compared to foundation models, especially for tasks where texture is less useful for classification. On the other hand, deep learning models did show more promising results for tasks where labels partially depend on texture (e.g., burn scar), while the difference in performance between foundation models and deep learning models is not obvious. The results conform with our analysis: The suitability of foundation models depend on the alignment between the self-supervised learning tasks and the real downstream tasks, and the typical masked autoencoder paradigm is not necessarily suitable for many remote sensing problems.
4/19/2024

MTP: Advancing Remote Sensing Foundation Model via Multi-Task Pretraining
Di Wang, Jing Zhang, Minqiang Xu, Lin Liu, Dongsheng Wang, Erzhong Gao, Chengxi Han, Haonan Guo, Bo Du, Dacheng Tao, Liangpei Zhang
0
0
Foundation models have reshaped the landscape of Remote Sensing (RS) by enhancing various image interpretation tasks. Pretraining is an active research topic, encompassing supervised and self-supervised learning methods to initialize model weights effectively. However, transferring the pretrained models to downstream tasks may encounter task discrepancy due to their formulation of pretraining as image classification or object discrimination tasks. In this study, we explore the Multi-Task Pretraining (MTP) paradigm for RS foundation models to address this issue. Using a shared encoder and task-specific decoder architecture, we conduct multi-task supervised pretraining on the SAMRS dataset, encompassing semantic segmentation, instance segmentation, and rotated object detection. MTP supports both convolutional neural networks and vision transformer foundation models with over 300 million parameters. The pretrained models are finetuned on various RS downstream tasks, such as scene classification, horizontal and rotated object detection, semantic segmentation, and change detection. Extensive experiments across 14 datasets demonstrate the superiority of our models over existing ones of similar size and their competitive performance compared to larger state-of-the-art models, thus validating the effectiveness of MTP.
5/31/2024

One for All: Toward Unified Foundation Models for Earth Vision
Zhitong Xiong, Yi Wang, Fahong Zhang, Xiao Xiang Zhu
0
0
Foundation models characterized by extensive parameters and trained on large-scale datasets have demonstrated remarkable efficacy across various downstream tasks for remote sensing data. Current remote sensing foundation models typically specialize in a single modality or a specific spatial resolution range, limiting their versatility for downstream datasets. While there have been attempts to develop multi-modal remote sensing foundation models, they typically employ separate vision encoders for each modality or spatial resolution, necessitating a switch in backbones contingent upon the input data. To address this issue, we introduce a simple yet effective method, termed OFA-Net (One-For-All Network): employing a single, shared Transformer backbone for multiple data modalities with different spatial resolutions. Using the masked image modeling mechanism, we pre-train a single Transformer backbone on a curated multi-modal dataset with this simple design. Then the backbone model can be used in different downstream tasks, thus forging a path towards a unified foundation backbone model in Earth vision. The proposed method is evaluated on 12 distinct downstream tasks and demonstrates promising performance.
5/29/2024