Multi-Agent Target Assignment and Path Finding for Intelligent Warehouse: A Cooperative Multi-Agent Deep Reinforcement Learning Perspective

0

Sign in to get full access
Overview
- This paper proposes a cooperative multi-agent deep reinforcement learning approach for solving the target assignment and path finding problem in intelligent warehouses.
- The goal is to coordinate a team of autonomous agents (e.g., robots or drones) to efficiently complete tasks in a warehouse environment.
- The approach uses a centralized training with decentralized execution framework, where a single neural network policy is trained to control all agents.
- Experiments show the method can achieve high task completion rates and navigate complex environments effectively.
Plain English Explanation
The paper tackles the challenge of coordinating multiple autonomous agents in a warehouse setting, with the goal of efficiently completing various tasks. To do this, the researchers use a deep reinforcement learning approach, where a single neural network policy is trained to control all the agents.
The key idea is to have a "centralized training with decentralized execution" framework. This means that during training, the agents work together as a team to learn the optimal behaviors. But during actual operation, each agent can make decisions independently based on the shared neural network policy. This allows the system to scale and respond flexibly to dynamic warehouse conditions.
The experiments show that this cooperative multi-agent approach can achieve high task completion rates and navigate complex warehouse environments effectively. By having the agents work together under a shared intelligence, they can coordinate their movements and actions to accomplish tasks more efficiently than if they were operating individually.
Technical Explanation
The paper presents a cooperative multi-agent deep reinforcement learning framework for the target assignment and path finding problem in intelligent warehouses. The key technical elements are:
-
Centralized Training with Decentralized Execution: The system uses a centralized neural network policy to control all the agents during training. This allows the agents to learn cooperative behaviors through joint optimization. During execution, each agent can make decisions independently based on the shared policy, enabling scalability and flexibility.
-
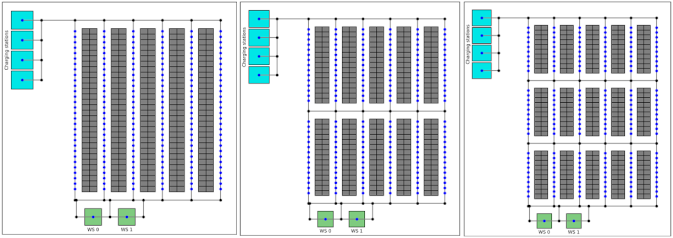
State Representation: The state input to the neural network includes the agents' current positions, the locations of assigned targets, and the positions of obstacles/walls in the environment. This provides the necessary information for the agents to plan their paths.
-
Action Space: The agents can choose from a discrete set of actions, such as moving in the four cardinal directions or staying still. The neural network outputs a probability distribution over these actions for each agent.
-
Reward Function: The reward function encourages the agents to complete their assigned tasks while also minimizing collisions and path lengths. This incentivizes the agents to cooperate and find efficient routes.
-
Training Procedure: The system is trained using proximal policy optimization (PPO), a popular reinforcement learning algorithm. During training, the agents receive joint rewards based on the team's overall performance.
The experiments evaluate the proposed approach on various warehouse environments, comparing it to baseline methods. The results demonstrate the ability of the cooperative multi-agent system to achieve high task completion rates and navigate complex scenes effectively.
Critical Analysis
The paper presents a promising approach for coordinating multiple autonomous agents in intelligent warehouses, but there are a few potential limitations and areas for future research:
-
Scalability: While the decentralized execution allows the system to scale to larger numbers of agents, the centralized training may become computationally challenging as the team size grows. Exploring more scalable training methods could be an area for further investigation.
-
Heterogeneous Agents: The current framework assumes all agents are homogeneous and have the same capabilities. Extending the approach to handle a mix of agent types (e.g., robots with different speeds or payload capacities) could increase its real-world applicability.
-
Dynamic Environments: The paper focuses on static warehouse environments, but real-world warehouses may have dynamic elements, such as moving obstacles or changing task priorities. Evaluating the system's performance in more realistic, time-varying scenarios would be valuable.
-
Robustness: The paper does not extensively explore the robustness of the trained policies to agent failures or unexpected events. Assessing the system's ability to handle such disruptions would be an important consideration for practical deployment.
Overall, the cooperative multi-agent deep reinforcement learning approach presented in the paper shows promise for intelligent warehouse automation. Further research to address the above limitations could help unlock the full potential of this technology.
Conclusion
This paper introduces a cooperative multi-agent deep reinforcement learning framework for solving the target assignment and path finding problem in intelligent warehouses. The key innovation is the use of a centralized training with decentralized execution approach, which allows the agents to learn cooperative behaviors while maintaining scalability and flexibility during operation.
The experimental results demonstrate the system's ability to achieve high task completion rates and navigate complex warehouse environments effectively. While the paper presents a solid technical foundation, there are opportunities for future work to address scalability, heterogeneity, dynamism, and robustness, which could further enhance the practical applicability of this approach for real-world intelligent warehouse automation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-Agent Target Assignment and Path Finding for Intelligent Warehouse: A Cooperative Multi-Agent Deep Reinforcement Learning Perspective
Qi Liu, Jianqi Gao, Dongjie Zhu, Xizheng Pang, Pengbin Chen, Jingxiang Guo, Yanjie Li
Multi-agent target assignment and path planning (TAPF) are two key problems in intelligent warehouse. However, most literature only addresses one of these two problems separately. In this study, we propose a method to simultaneously solve target assignment and path planning from a perspective of cooperative multi-agent deep reinforcement learning (RL). To the best of our knowledge, this is the first work to model the TAPF problem for intelligent warehouse to cooperative multi-agent deep RL, and the first to simultaneously address TAPF based on multi-agent deep RL. Furthermore, previous literature rarely considers the physical dynamics of agents. In this study, the physical dynamics of the agents is considered. Experimental results show that our method performs well in various task settings, which means that the target assignment is solved reasonably well and the planned path is almost shortest. Moreover, our method is more time-efficient than baselines.
Read more8/27/2024
0
Multi-Agent Path Finding with Real Robot Dynamics and Interdependent Tasks for Automated Warehouses
Vassilissa Lehoux-Lebacque, Tomi Silander, Christelle Loiodice, Seungjoon Lee, Albert Wang, Sofia Michel
Multi-Agent Path Finding (MAPF) is an important optimization problem underlying the deployment of robots in automated warehouses and factories. Despite the large body of work on this topic, most approaches make heavy simplifications, both on the environment and the agents, which make the resulting algorithms impractical for real-life scenarios. In this paper, we consider a realistic problem of online order delivery in a warehouse, where a fleet of robots bring the products belonging to each order from shelves to workstations. This creates a stream of inter-dependent pickup and delivery tasks and the associated MAPF problem consists of computing realistic collision-free robot trajectories fulfilling these tasks. To solve this MAPF problem, we propose an extension of the standard Prioritized Planning algorithm to deal with the inter-dependent tasks (Interleaved Prioritized Planning) and a novel Via-Point Star (VP*) algorithm to compute an optimal dynamics-compliant robot trajectory to visit a sequence of goal locations while avoiding moving obstacles. We prove the completeness of our approach and evaluate it in simulation as well as in a real warehouse.
Read more8/28/2024

0
Caching-Augmented Lifelong Multi-Agent Path Finding
Yimin Tang, Zhenghong Yu, Yi Zheng, T. K. Satish Kumar, Jiaoyang Li, Sven Koenig
Multi-Agent Path Finding (MAPF), which involves finding collision-free paths for multiple robots, is crucial in various applications. Lifelong MAPF, where targets are reassigned to agents as soon as they complete their initial targets, offers a more accurate approximation of real-world warehouse planning. In this paper, we present a novel mechanism named Caching-Augmented Lifelong MAPF (CAL-MAPF), designed to improve the performance of Lifelong MAPF. We have developed a new type of map grid called cache for temporary item storage and replacement, and created a locking mechanism to improve the planning solution's stability. A task assigner (TA) is designed for CAL-MAPF to allocate target locations to agents and control agent status in different situations. CAL-MAPF has been evaluated using various cache replacement policies and input task distributions. We have identified three main factors significantly impacting CAL-MAPF performance through experimentation: suitable input task distribution, high cache hit rate, and smooth traffic. In general, CAL-MAPF has demonstrated potential for performance improvements in certain task distributions, map and agent configurations.
Read more4/9/2024

0
Optimal Task Assignment and Path Planning using Conflict-Based Search with Precedence and Temporal Constraints
Yu Quan Chong, Jiaoyang Li, Katia Sycara
The Multi-Agent Path Finding (MAPF) problem entails finding collision-free paths for a set of agents, guiding them from their start to goal locations. However, MAPF does not account for several practical task-related constraints. For example, agents may need to perform actions at goal locations with specific execution times, adhering to predetermined orders and timeframes. Moreover, goal assignments may not be predefined for agents, and the optimization objective may lack an explicit definition. To incorporate task assignment, path planning, and a user-defined objective into a coherent framework, this paper examines the Task Assignment and Path Finding with Precedence and Temporal Constraints (TAPF-PTC) problem. We augment Conflict-Based Search (CBS) to simultaneously generate task assignments and collision-free paths that adhere to precedence and temporal constraints, maximizing an objective quantified by the return from a user-defined reward function in reinforcement learning (RL). Experimentally, we demonstrate that our algorithm, CBS-TA-PTC, can solve highly challenging bomb-defusing tasks with precedence and temporal constraints efficiently relative to MARL and adapted Target Assignment and Path Finding (TAPF) methods.
Read more4/23/2024