Multi-AGV Path Planning Method via Reinforcement Learning and Particle Filters
2403.18236
0
0
Abstract
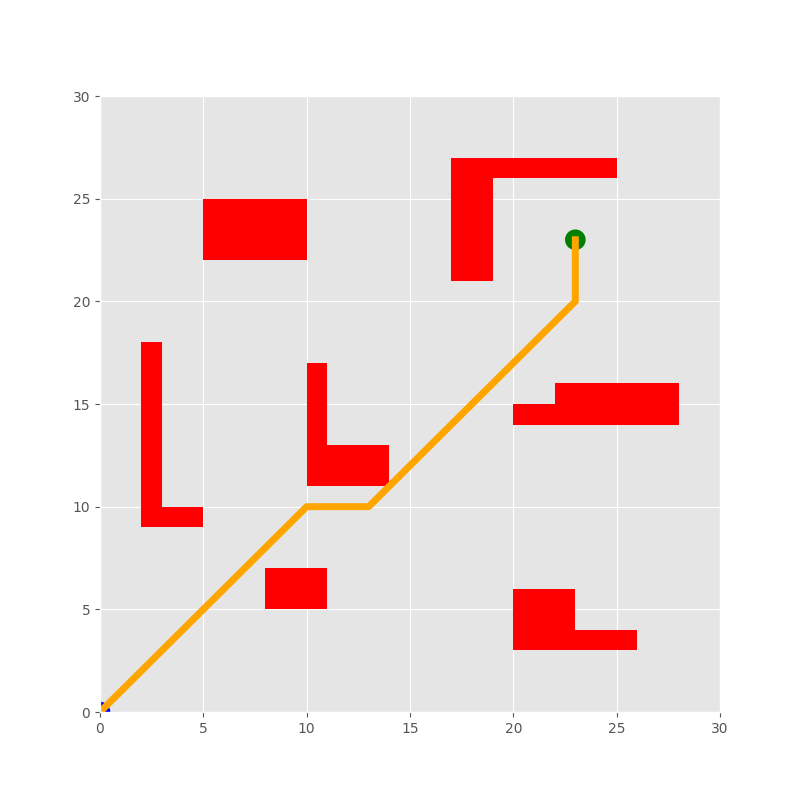
The Reinforcement Learning (RL) algorithm, renowned for its robust learning capability and search stability, has garnered significant attention and found extensive application in Automated Guided Vehicle (AGV) path planning. However, RL planning algorithms encounter challenges stemming from the substantial variance of neural networks caused by environmental instability and significant fluctuations in system structure. These challenges manifest in slow convergence speed and low learning efficiency. To tackle this issue, this paper presents the Particle Filter-Double Deep Q-Network (PF-DDQN) approach, which incorporates the Particle Filter (PF) into multi-AGV reinforcement learning path planning. The PF-DDQN method leverages the imprecise weight values of the network as state values to formulate the state space equation. Through the iterative fusion process of neural networks and particle filters, the DDQN model is optimized to acquire the optimal true weight values, thus enhancing the algorithm's efficiency. The proposed method's effectiveness and superiority are validated through numerical simulations. Overall, the simulation results demonstrate that the proposed algorithm surpasses the traditional DDQN algorithm in terms of path planning superiority and training time indicators by 92.62% and 76.88%, respectively. In conclusion, the PF-DDQN method addresses the challenges encountered by RL planning algorithms in AGV path planning. By integrating the Particle Filter and optimizing the DDQN model, the proposed method achieves enhanced efficiency and outperforms the traditional DDQN algorithm in terms of path planning superiority and training time indicators.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a method for planning paths for multiple autonomous ground vehicles (AGVs) using reinforcement learning and particle filters.
- The approach aims to efficiently coordinate the movement of multiple AGVs in a shared environment while avoiding collisions.
- The researchers leverage reinforcement learning to train the AGVs to navigate optimally, and particle filters to track the dynamic environment and predict future positions of the vehicles.
Plain English Explanation
The paper describes a way to help self-driving vehicles, called autonomous ground vehicles (AGVs), navigate through an area without crashing into each other. The challenge is that when you have multiple AGVs moving around, they need to be coordinated so they don't collide.
The researchers use two key techniques to solve this problem:
-
Reinforcement Learning: This is a type of machine learning where the AGVs "learn" the best way to navigate by trying different actions and getting rewards or penalties based on how well they do. Over time, the AGVs figure out the optimal paths to take.
-
Particle Filters: These are a way to track the current positions of the AGVs and predict where they will be in the future. This helps the system anticipate potential collisions and adjust the vehicles' paths accordingly.
By combining reinforcement learning and particle filters, the researchers developed a system that can efficiently coordinate the movement of multiple AGVs in a shared space, allowing them to reach their destinations safely and without crashes. This could be very useful for applications like warehouse logistics, transportation, or even self-driving cars in the future.
Technical Explanation
The paper proposes a multi-AGV path planning method via reinforcement learning and particle filters. The key components of the approach are:
-
Reinforcement Learning: The researchers use reinforcement learning to train the AGVs to navigate optimally. The AGVs learn by trial-and-error, receiving rewards for actions that lead to successful navigation and penalties for actions that result in collisions or other failures. Over time, the AGVs learn the best paths to reach their destinations.
-
Particle Filters: The system uses particle filters to track the current positions of the AGVs and predict their future locations. Particle filters represent the state of the environment (the positions of the AGVs) using a large number of "particles" that evolve over time based on sensor data and a dynamic model of the environment. This allows the system to anticipate potential collisions and adjust the AGVs' paths accordingly.
-
Coordination: By combining reinforcement learning and particle filters, the researchers developed a method to efficiently coordinate the movement of multiple AGVs in a shared environment. The reinforcement learning component optimizes the individual AGV's paths, while the particle filters ensure that the overall system can adapt to the dynamic environment and avoid collisions.
The researchers evaluated their approach through simulations and demonstrated its effectiveness in coordinating the movement of multiple AGVs while minimizing travel time and collisions. This work could have applications in warehouse logistics, transportation, and other domains involving the coordination of autonomous vehicles.
Critical Analysis
The paper provides a promising approach for multi-AGV path planning, leveraging the strengths of reinforcement learning and particle filters. However, there are a few potential limitations and areas for further research that could be considered:
-
Real-world Applicability: While the simulations demonstrate the effectiveness of the approach, the researchers acknowledge the need for further testing in real-world environments with more complex obstacles and dynamics. Transitioning the method to physical AGVs may introduce additional challenges related to sensor accuracy, communication, and computational constraints.
-
Scalability: The paper focuses on a relatively small number of AGVs (up to 10). It would be important to evaluate the scalability of the approach as the number of vehicles increases, as the coordination and computation complexity could become more challenging.
-
Uncertainty Handling: The particle filters used in the system rely on accurate dynamic models of the environment. In real-world scenarios, there may be greater uncertainty in the sensor data and the underlying dynamics, which could impact the accuracy of the collision predictions. Exploring more robust uncertainty handling techniques could be an area for further research.
-
Explainability: As with many reinforcement learning-based systems, the trained AGV policies may be difficult to interpret and explain. Developing more transparent and explainable approaches could be valuable for building trust and understanding the decision-making processes of the autonomous vehicles.
Despite these potential limitations, the paper presents a compelling framework for coordinating the movement of multiple AGVs, which could have significant implications for warehouse automation, autonomous transportation, and other domains involving the coordination of autonomous systems.
Conclusion
This paper introduces a novel approach for planning paths for multiple autonomous ground vehicles (AGVs) using a combination of reinforcement learning and particle filters. The reinforcement learning component allows the AGVs to learn optimal navigation policies, while the particle filters enable the system to track the dynamic environment and predict potential collisions, enabling efficient coordination of the AGVs' movements.
The researchers demonstrated the effectiveness of their approach through simulations, showing reductions in travel time and collisions compared to other methods. While further work is needed to address real-world challenges and scale the system to larger fleets of AGVs, this research represents an important step towards enabling the safe and efficient deployment of autonomous vehicles in complex, dynamic environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Random Network Distillation Based Deep Reinforcement Learning for AGV Path Planning
Huilin Yin, Shengkai Su, Yinjia Lin, Pengju Zhen, Karin Festl, Daniel Watzenig
0
0
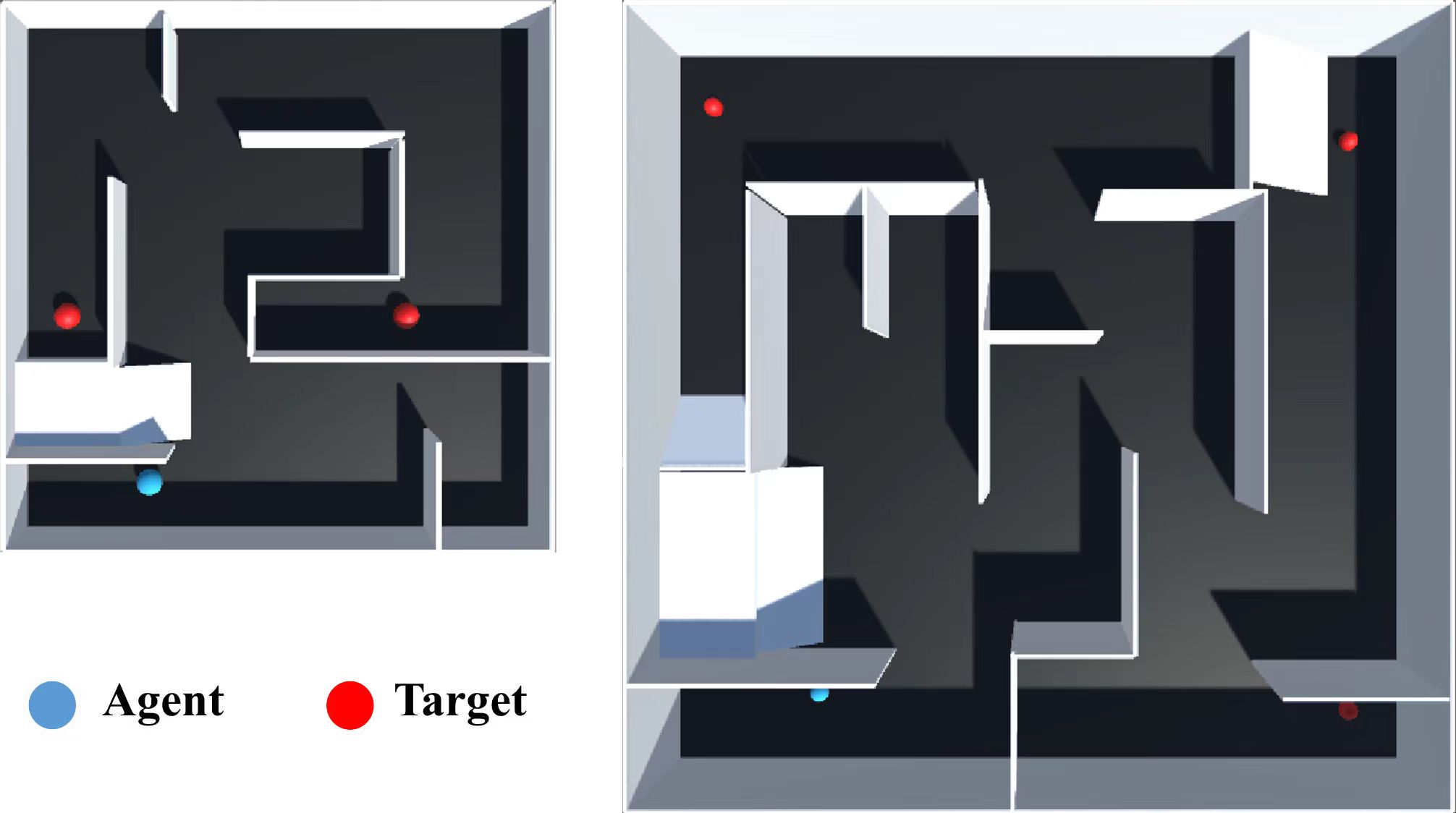
With the flourishing development of intelligent warehousing systems, the technology of Automated Guided Vehicle (AGV) has experienced rapid growth. Within intelligent warehousing environments, AGV is required to safely and rapidly plan an optimal path in complex and dynamic environments. Most research has studied deep reinforcement learning to address this challenge. However, in the environments with sparse extrinsic rewards, these algorithms often converge slowly, learn inefficiently or fail to reach the target. Random Network Distillation (RND), as an exploration enhancement, can effectively improve the performance of proximal policy optimization, especially enhancing the additional intrinsic rewards of the AGV agent which is in sparse reward environments. Moreover, most of the current research continues to use 2D grid mazes as experimental environments. These environments have insufficient complexity and limited action sets. To solve this limitation, we present simulation environments of AGV path planning with continuous actions and positions for AGVs, so that it can be close to realistic physical scenarios. Based on our experiments and comprehensive analysis of the proposed method, the results demonstrate that our proposed method enables AGV to more rapidly complete path planning tasks with continuous actions in our environments. A video of part of our experiments can be found at https://youtu.be/lwrY9YesGmw.
4/22/2024
🤿
Deep Reinforcement Learning for Mobile Robot Path Planning
Hao Liu, Yi Shen, Shuangjiang Yu, Zijun Gao, Tong Wu
0
0
Path planning is an important problem with the the applications in many aspects, such as video games, robotics etc. This paper proposes a novel method to address the problem of Deep Reinforcement Learning (DRL) based path planning for a mobile robot. We design DRL-based algorithms, including reward functions, and parameter optimization, to avoid time-consuming work in a 2D environment. We also designed an Two-way search hybrid A* algorithm to improve the quality of local path planning. We transferred the designed algorithm to a simple embedded environment to test the computational load of the algorithm when running on a mobile robot. Experiments show that when deployed on a robot platform, the DRL-based algorithm in this article can achieve better planning results and consume less computing resources.
4/11/2024
SmartPathfinder: Pushing the Limits of Heuristic Solutions for Vehicle Routing Problem with Drones Using Reinforcement Learning
Navid Mohammad Imran, Myounggyu Won
0
0
The Vehicle Routing Problem with Drones (VRPD) seeks to optimize the routing paths for both trucks and drones, where the trucks are responsible for delivering parcels to customer locations, and the drones are dispatched from these trucks for parcel delivery, subsequently being retrieved by the trucks. Given the NP-Hard complexity of VRPD, numerous heuristic approaches have been introduced. However, improving solution quality and reducing computation time remain significant challenges. In this paper, we conduct a comprehensive examination of heuristic methods designed for solving VRPD, distilling and standardizing them into core elements. We then develop a novel reinforcement learning (RL) framework that is seamlessly integrated with the heuristic solution components, establishing a set of universal principles for incorporating the RL framework with heuristic strategies in an aim to improve both the solution quality and computation speed. This integration has been applied to a state-of-the-art heuristic solution for VRPD, showcasing the substantial benefits of incorporating the RL framework. Our evaluation results demonstrated that the heuristic solution incorporated with our RL framework not only elevated the quality of solutions but also achieved rapid computation speeds, especially when dealing with extensive customer locations.
4/23/2024
🤿
Adaptive speed planning for Unmanned Vehicle Based on Deep Reinforcement Learning
Hao Liu, Yi Shen, Wenjing Zhou, Yuelin Zou, Chang Zhou, Shuyao He
0
0
In order to solve the problem of frequent deceleration of unmanned vehicles when approaching obstacles, this article uses a Deep Q-Network (DQN) and its extension, the Double Deep Q-Network (DDQN), to develop a local navigation system that adapts to obstacles while maintaining optimal speed planning. By integrating improved reward functions and obstacle angle determination methods, the system demonstrates significant enhancements in maneuvering capabilities without frequent decelerations. Experiments conducted in simulated environments with varying obstacle densities confirm the effectiveness of the proposed method in achieving more stable and efficient path planning.
4/29/2024