Random Network Distillation Based Deep Reinforcement Learning for AGV Path Planning
2404.12594
0
0
Abstract
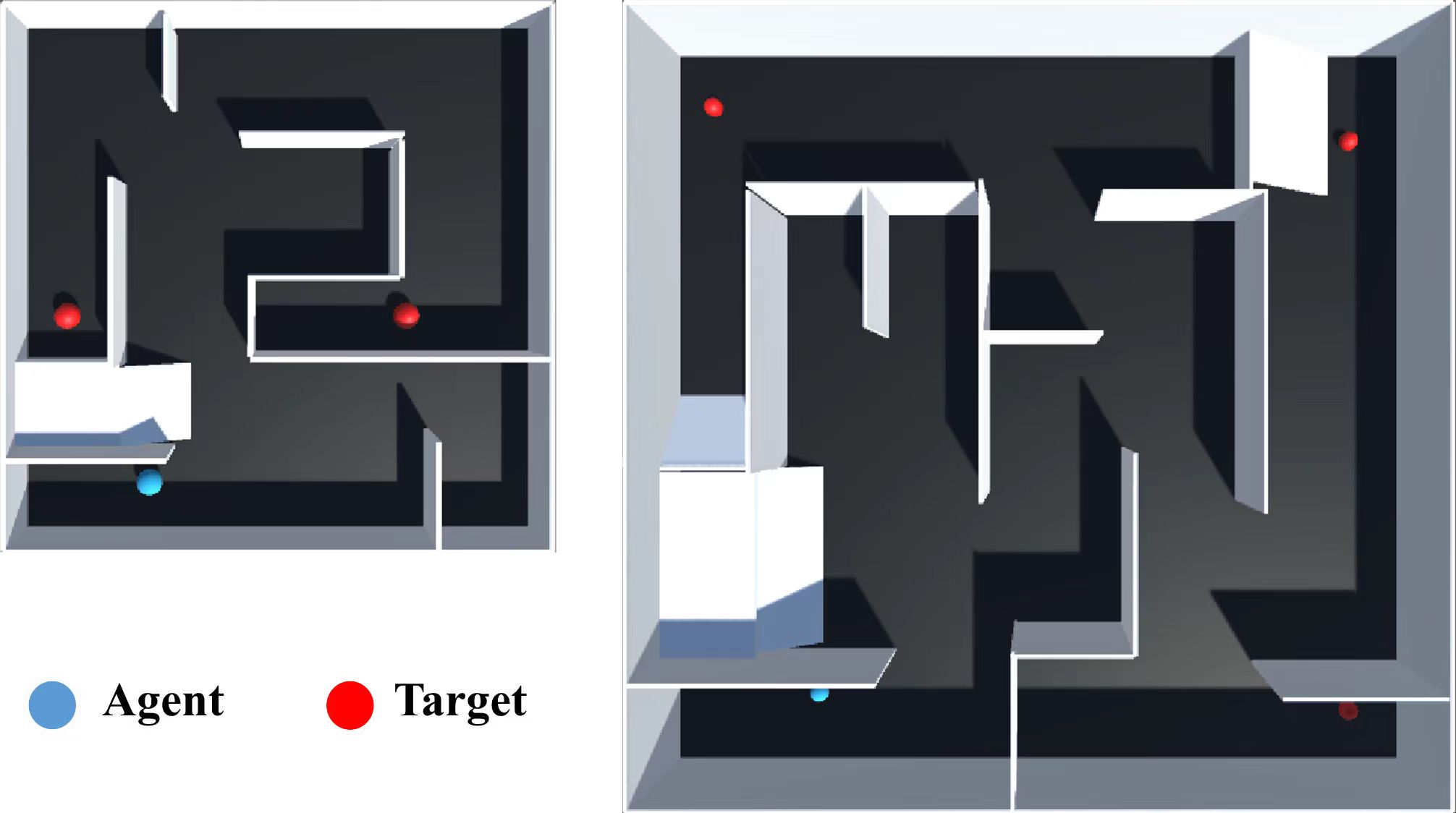
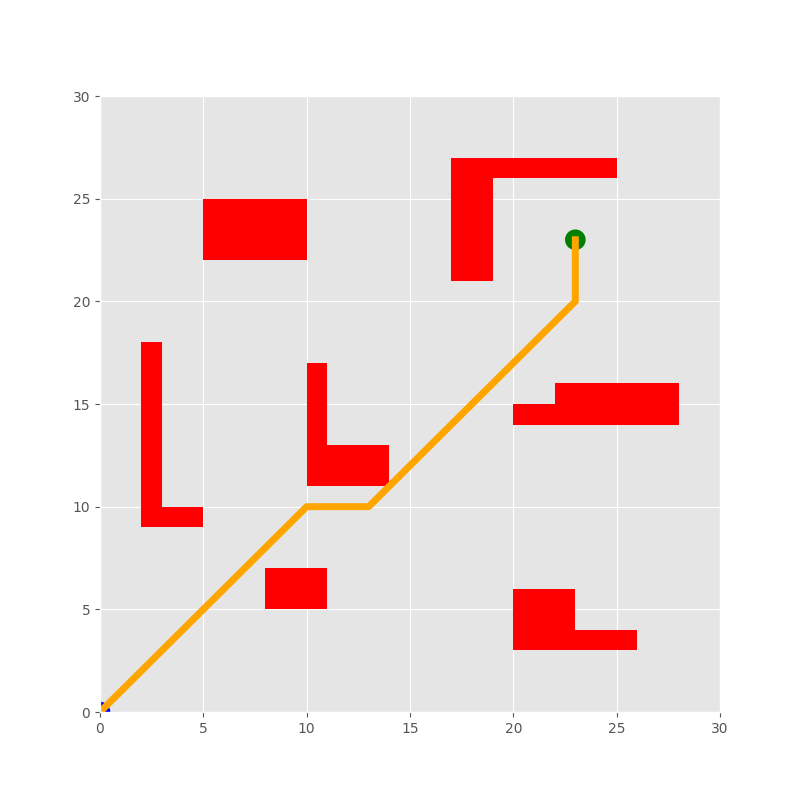
With the flourishing development of intelligent warehousing systems, the technology of Automated Guided Vehicle (AGV) has experienced rapid growth. Within intelligent warehousing environments, AGV is required to safely and rapidly plan an optimal path in complex and dynamic environments. Most research has studied deep reinforcement learning to address this challenge. However, in the environments with sparse extrinsic rewards, these algorithms often converge slowly, learn inefficiently or fail to reach the target. Random Network Distillation (RND), as an exploration enhancement, can effectively improve the performance of proximal policy optimization, especially enhancing the additional intrinsic rewards of the AGV agent which is in sparse reward environments. Moreover, most of the current research continues to use 2D grid mazes as experimental environments. These environments have insufficient complexity and limited action sets. To solve this limitation, we present simulation environments of AGV path planning with continuous actions and positions for AGVs, so that it can be close to realistic physical scenarios. Based on our experiments and comprehensive analysis of the proposed method, the results demonstrate that our proposed method enables AGV to more rapidly complete path planning tasks with continuous actions in our environments. A video of part of our experiments can be found at https://youtu.be/lwrY9YesGmw.
Create account to get full access
Overview
- This paper proposes a deep reinforcement learning-based approach for autonomous guided vehicle (AGV) path planning in dynamic environments.
- The method uses Random Network Distillation (RND), a technique that can improve exploration and learning efficiency in reinforcement learning tasks.
- The authors evaluate their approach on a simulated AGV path planning problem and compare it to other reinforcement learning methods.
Plain English Explanation
The paper is about using a technique called Random Network Distillation (RND) to help train an autonomous guided vehicle (AGV) to navigate through a complex environment. AGVs are robots that can move around on their own without a human driver.
The key idea is that the RND method can help the AGV explore its environment more effectively and learn how to plan its path more efficiently. This is important because AGVs need to be able to navigate through dynamic, changing environments, which can be challenging.
The researchers set up a simulated environment to test their approach and compared it to other reinforcement learning methods for AGV path planning. Reinforcement learning is a type of machine learning where the system learns by trial and error, getting rewards for good actions and penalties for bad ones.
By using the RND technique, the researchers were able to show that their approach could help the AGV learn to navigate the environment more effectively than other reinforcement learning methods. This could have important applications for real-world AGV systems, such as in warehouses or manufacturing plants, where efficient and safe navigation is crucial.
Technical Explanation
The paper presents a deep reinforcement learning-based approach for AGV path planning in dynamic environments, using a technique called Random Network Distillation (RND).
The authors first define the AGV path planning problem as a Markov Decision Process (MDP), where the agent (the AGV) must learn to navigate from a starting position to a goal position while avoiding obstacles. They then introduce the RND method, which involves training a neural network to predict the features of randomly generated observations. This auxiliary task can help the agent explore its environment more effectively and learn a better policy for the main task of path planning.
The authors implement their RND-based deep reinforcement learning approach using the Proximal Policy Optimization (PPO) algorithm. They evaluate the performance of their method on a simulated AGV path planning problem and compare it to other reinforcement learning approaches, such as Soft Actor-Critic (SAC) and Deep Deterministic Policy Gradient (DDPG).
The results show that the RND-based method outperforms the other approaches in terms of path length, success rate, and computational efficiency. The authors attribute this to the ability of RND to encourage exploration and improve the learning process.
Critical Analysis
The paper presents a novel application of the RND technique to the problem of AGV path planning, which is an important and challenging task in robotics and automation. The authors have carefully designed their experiment and provided a thorough evaluation of their approach.
However, the paper does not discuss potential limitations or caveats of their method. For example, it would be valuable to understand how the RND-based approach might perform in more complex, real-world environments with dynamic obstacles, uncertainty, or partial observability. Additionally, the paper does not explore the computational overhead or memory requirements of the RND method, which could be a concern for deployment on resource-constrained AGV systems.
Further research could also investigate the generalizability of the RND-based approach to other path planning problems, such as multi-AGV coordination or navigation in unstructured environments. Incorporating additional domain-specific knowledge or hybrid approaches that combine RND with other techniques could also be an area for future exploration.
Conclusion
This paper presents a deep reinforcement learning-based approach for AGV path planning that leverages the Random Network Distillation (RND) technique to improve exploration and learning efficiency. The results demonstrate the effectiveness of the RND-based method compared to other reinforcement learning approaches, suggesting that it could be a valuable tool for developing robust and efficient AGV navigation systems.
While the paper does not address all potential limitations, it provides a promising direction for further research and development in this important area of robotics and automation. As AGVs continue to play an increasingly crucial role in various industries, advances in path planning algorithms like the one proposed here could have significant practical implications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Exploration and Anti-Exploration with Distributional Random Network Distillation
Kai Yang, Jian Tao, Jiafei Lyu, Xiu Li
0
0
Exploration remains a critical issue in deep reinforcement learning for an agent to attain high returns in unknown environments. Although the prevailing exploration Random Network Distillation (RND) algorithm has been demonstrated to be effective in numerous environments, it often needs more discriminative power in bonus allocation. This paper highlights the bonus inconsistency issue within RND, pinpointing its primary limitation. To address this issue, we introduce the Distributional RND (DRND), a derivative of the RND. DRND enhances the exploration process by distilling a distribution of random networks and implicitly incorporating pseudo counts to improve the precision of bonus allocation. This refinement encourages agents to engage in more extensive exploration. Our method effectively mitigates the inconsistency issue without introducing significant computational overhead. Both theoretical analysis and experimental results demonstrate the superiority of our approach over the original RND algorithm. Our method excels in challenging online exploration scenarios and effectively serves as an anti-exploration mechanism in D4RL offline tasks. Our code is publicly available at https://github.com/yk7333/DRND.
5/21/2024
Multi-AGV Path Planning Method via Reinforcement Learning and Particle Filters
Shao Shuo
0
0
Thanks to its robust learning and search stabilities,the reinforcement learning (RL) algorithm has garnered increasingly significant attention and been exten-sively applied in Automated Guided Vehicle (AGV) path planning. However, RL-based planning algorithms have been discovered to suffer from the substantial variance of neural networks caused by environmental instability and significant fluctua-tions in system structure. These challenges manifest in slow convergence speed and low learning efficiency. To tackle this issue, this paper presents a novel multi-AGV path planning method named Particle Filters - Double Deep Q-Network (PF-DDQN)via leveraging Particle Filters (PF) and RL algorithm. Firstly, the proposed method leverages the imprecise weight values of the network as state values to formulate thestate space equation.Subsequently, the DDQN model is optimized to acquire the optimal true weight values through the iterative fusion process of neural networksand PF in order to enhance the optimization efficiency of the proposedmethod. Lastly, the performance of the proposed method is validated by different numerical simulations. The simulation results demonstrate that the proposed methoddominates the traditional DDQN algorithm in terms of path planning superiority andtraining time indicator by 92.62% and 76.88%, respectively. Therefore, the proposedmethod could be considered as a vital alternative in the field of multi-AGV path planning.
5/24/2024
🏅
New!Research on Autonomous Robots Navigation based on Reinforcement Learning
Zixiang Wang, Hao Yan, Yining Wang, Zhengjia Xu, Zhuoyue Wang, Zhizhong Wu
0
0
Reinforcement learning continuously optimizes decision-making based on real-time feedback reward signals through continuous interaction with the environment, demonstrating strong adaptive and self-learning capabilities. In recent years, it has become one of the key methods to achieve autonomous navigation of robots. In this work, an autonomous robot navigation method based on reinforcement learning is introduced. We use the Deep Q Network (DQN) and Proximal Policy Optimization (PPO) models to optimize the path planning and decision-making process through the continuous interaction between the robot and the environment, and the reward signals with real-time feedback. By combining the Q-value function with the deep neural network, deep Q network can handle high-dimensional state space, so as to realize path planning in complex environments. Proximal policy optimization is a strategy gradient-based method, which enables robots to explore and utilize environmental information more efficiently by optimizing policy functions. These methods not only improve the robot's navigation ability in the unknown environment, but also enhance its adaptive and self-learning capabilities. Through multiple training and simulation experiments, we have verified the effectiveness and robustness of these models in various complex scenarios.
7/4/2024
🤿
Deep Reinforcement Learning for Mobile Robot Path Planning
Hao Liu, Yi Shen, Shuangjiang Yu, Zijun Gao, Tong Wu
0
0
Path planning is an important problem with the the applications in many aspects, such as video games, robotics etc. This paper proposes a novel method to address the problem of Deep Reinforcement Learning (DRL) based path planning for a mobile robot. We design DRL-based algorithms, including reward functions, and parameter optimization, to avoid time-consuming work in a 2D environment. We also designed an Two-way search hybrid A* algorithm to improve the quality of local path planning. We transferred the designed algorithm to a simple embedded environment to test the computational load of the algorithm when running on a mobile robot. Experiments show that when deployed on a robot platform, the DRL-based algorithm in this article can achieve better planning results and consume less computing resources.
4/11/2024